
作者介绍:
韦万,PingCAP 数据库研发工程师,主要领域是数据库的存储引擎研发,以及系统性能优化。
一、为什么我们需要 HTAP 数据库?
在互联网浪潮出现之前,企业的数据量普遍不大,特别是核心的业务数据,通常一个单机的数据库就可以保存。那时候的存储并不需要复杂的架构,所有的线上请求(OLTP, Online Transactional Processing) 和后台分析 (OLAP, Online Analytical Processing) 都跑在同一个数据库实例上。后来渐渐的业务越来越复杂,数据量越来越大,DBA 们再也优化不动 SQL 了。其中一个显著问题是:单机数据库支持线上的 TP 请求已经非常吃力,没办法再跑比较重的 AP 分析型任务。跑起来要么 OOM,要么影响线上业务,要么做了主从分离、分库分表之后很难实现业务需求。
在这样的背景下,以 Hadoop 为代表的大数据技术开始蓬勃发展,它用许多相对廉价的 x86 机器构建了一个数据分析平台,用并行的能力破解大数据集的计算问题。所以从某种程度上说,大数据技术可以算是传统关系型数据库技术发展过程的一个分支。当然在过程中大数据领域也发展出了属于自己的全新场景,诞生了许多新的技术,这个不深入提了。
由此,架构师把存储划分成线上业务和数据分析两个模块。如下图所示,业务库的数据通过 ETL 工具抽取出来,导入专用的分析平台。业务数据库专注提供 TP 能力,分析平台提供 AP 能力,各施其职,看起来已经很完美了。但其实这个架构也有自己的不足。
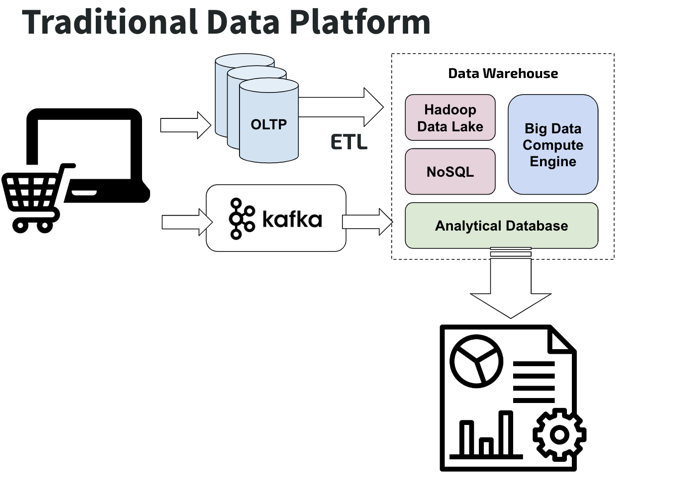
首先是复杂性问题。本身 ETL 过程就是一个很繁琐的过程,一个例证是 ETL 做的好,可以成为一个商业模式。因为是两个系统,必然带来更高的学习成本、维护成本和整合成本。如果你使用的是开源的大数据工具搭建的分析平台,那么肯定会遇到各种工具之间的磨合的问题,还有由于各种工具良莠不齐所导致的质量问题。
其次是实时性问题。通常我们认为越接近实时的数据,它的价值越大。很多业务场景,对实时性有很高的要求,比如风控系统,它需要对数据不停的分析,并且在险情出现之后尽快响应。而通常的 ETL 是一个周期性的操作,比如一天或者一个小时导一次数据,数据实时性是没有办法保证的。
最后是一致性问题。一致性在数据库里面是很重要的概念,数据库的事务就是用来保证一致性的。如果把数据分表存储在两个不同的系统内,那么很难保证一致性,即 AP 系统的查询结果没有办法与线上业务正确对应。那么这两个系统的联动效应就会受到限制,比如用户没办法在一个事务里面,同时访问两个系统的数据。
由于现有的数据平台存在的以上局限性,我们认为开发一个HTAP(Hybrid Transactional/Analytical Processing)融合型数据库产品可以缓解大家在 TP or AP 抉择上的焦虑,或者说,让数据库的使用者不用考虑过度复杂的架构,在一套数据库中既能满足 OLTP 类需求,也能满足 OLAP 类需求。这也是 TiDB 最初设计时的初衷。
二、TiFlash 是什么?
TiDB 定位为一款 HTAP 数据库,希望同时解决 TP 和 AP 问题。我们知道 TiDB 可以当作可线性扩展的 MySQL 来用,本身设计是可以满足 TP 的需求的。在 17 年我们发布了 TiSpark,它可以直接读取 TiKV 的数据,利用 Spark 强大的计算能力来加强 AP 端的能力。然而由于 TiKV 毕竟是为 TP 场景设计的存储层,对于大批量数据的提取、分析能力有限,所以我们为 TiDB 引入了以新的 TiFlash 组件,它的使命是进一步增强 TiDB 的 AP 能力,使之成为一款真正意义上的 HTAP 数据库。

TiFlash 是 TiDB 的一个 AP 扩展。在定位上,它是与 TiKV 相对应的存储节点,与 TiKV 分开部署。它既可以存储数据,也可以下推一部分的计算逻辑。数据是通过 Raft Learner 协议,从 TiKV 同步过来的。TiFlash 与 TiKV 最大的区别,一是原生的向量化模型,二是列式存储。 这是都是专门为 AP 场景做的优化。TiFlash 项目借助了 Clickhouse 的向量化引擎,因此计算上继承了它高性能的优点。
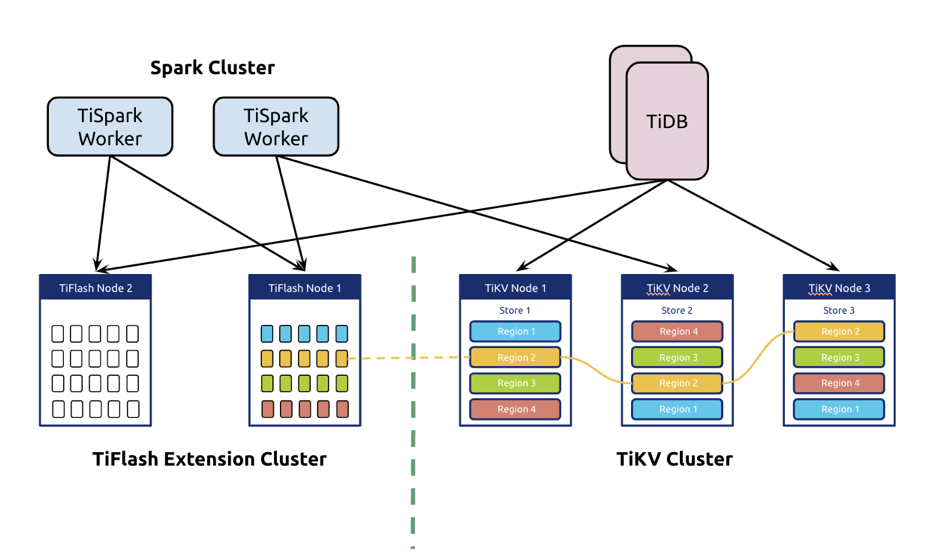
由于 TiFlash 节点和 TiKV 节点是分开部署的,所以即使我们跑很重的计算任务,也不会对线上业务产生影响。
上层的计算节点,包括 TiSpark 和 TiDB,他们都可以访问 TiKV 和 TiFlash。后面会介绍我们是如何利用这个架构的优势,在一个系统内同时服务 TP 和 AP 这两个场景,并且产生 1+1>2 的效果。
三、TiFlash 技术内幕
对于一个数据库系统,TP 和 AP 是有系统设计上的冲突的。TP 场景我们关注的是事务正确性,性能指标是 QPS、延迟,它通常是点写、点查的场景;而 AP 更关心的吞吐量,是大批量数据的处理能力,处理成本。比如很多情况下 AP 的分析查询是需要扫描几百上千万条数据,join 十几张表,这种场景下系统的设计哲学和 TP 完全不同。TP 通常使用行式存储,例如 InnoDB,RocksDB 等;而 AP 系统通常使用列式存储。将这两个需求放在同一个系统里面实现,从设计上很难取舍,再加上 AP 的查询业务通常属于资源消耗型,隔离性做不好,很容易影响TP 业务。所以做一个 HTAP 系统是一件难度非常高的事情,很考验系统的工程设计能力。
1. 列式存储

一般来说,AP 系统基本上都是使用列式存储,TiFlash 也不例外。列式存储天然可以做列过滤,并且压缩率很高,适合大数据的 Scan 场景。另外列式存储更适合做向量化加速,适合下推的聚合类算子也更多。TiFlash 相对于 TiKV,在 Scan 场景下性能有数量级的提升。
而行式存储显然更适合 TP 场景,因为它很适合点查,只读少量数据,IO 次数、粒度都更小。在绝大多数走索引的查询中,可以实现高 QPS 和低延迟。
由于我们把 TiFlash 和 TiKV 整合在了 TiDB 内部,用户可以灵活选择使用哪种存储方式。数据写入了 TiKV 之后,用户可以根据需选择是否同步到 TiFlash,以供 AP 加速。目前可选的同步粒度是表或者库。
2. 低成本数据复制
数据复制永远是分布式系统的最重要的问题之一。TiFlash 作为 TiDB 的另外一个存储层,需要实时同步 TiKV 的数据。我们采用的方案也很自然:既然 TiKV 节点内部使用 Raft 协议同步,那自然 TiKV 到 TiFlash 也是可以用 Raft 协议同步数据的。TiFlash 会把自己伪装成一个 TiKV 节点,加入 Raft Group。比较不一样的是,TiFlash 只会作为 Raft Learner,并不会成为 Raft Leader / Follower。原因是目前 TiFlash 还不支持来自 SQL 端(TiDB/ TiSpark)的直接写入,我们将在稍后支持这一特性。
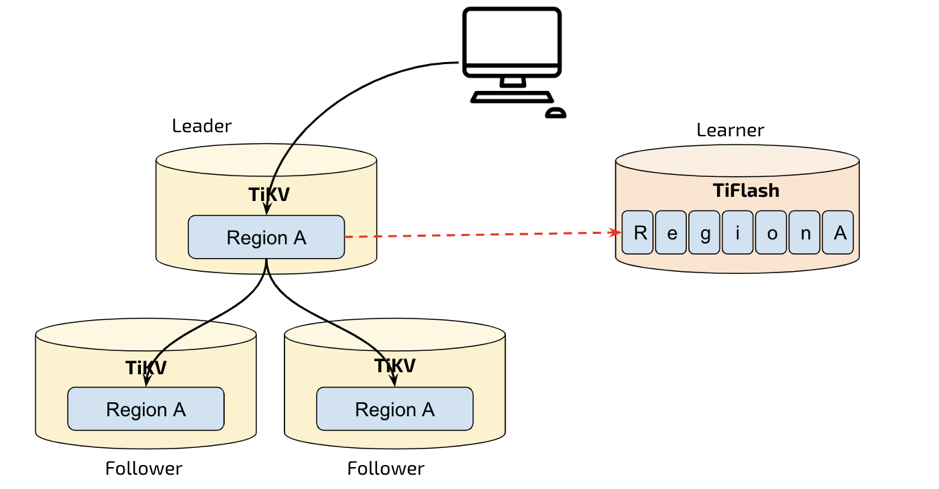
大家知道,Raft 协议为了提高数据复制效率,Raft Log 从 Leader 到 Follower / Learner 的复制通常会优化成异步复制,只要记录被复制到了 Leader + Follower 的 “多数” 节点,就认为已经 commit 了。并且 Learner 是排除在 “多数” 之外的,也就是说更新不需要等待 Learner 确认。这样的实现方式,缺点是 Learner 上的数据可能有一定延迟,优点是大大减少了引入 TiFlash 造成的额外数据复制开销。当然如果复制延迟太大,说明节点之间的网络或者机器的写入性能出现了问题,这时候我们会有报警提示做进一步的处理。
3. 强一致性
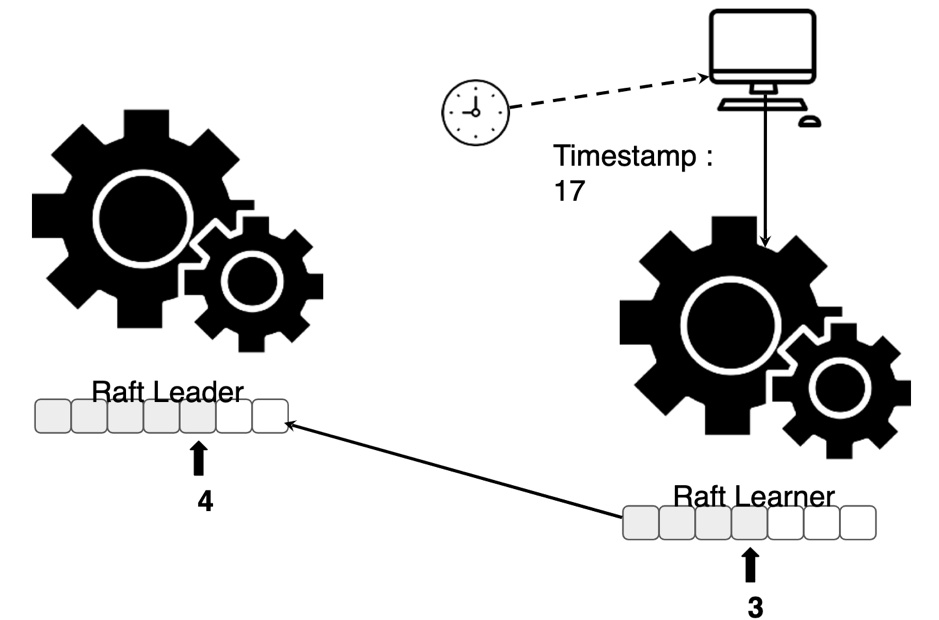
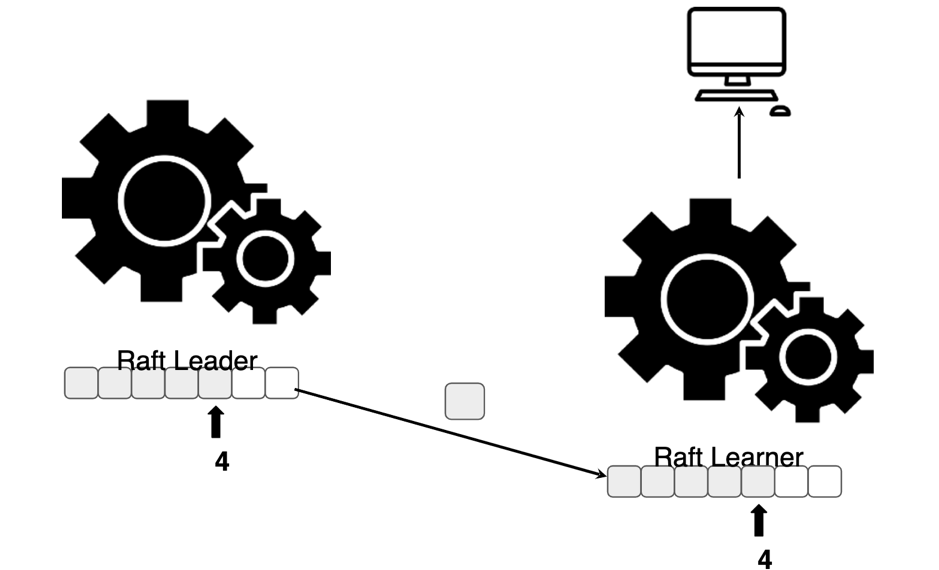
那既然是异步复制,如何保证读一致性呢?通常来说,因为在 Leader 节点一定可以拿到最新的数据,所以我们只会去 Leader 节点读数据。但是 TiFlash 只有 Learner,不可能这样读数据。我们使用 Raft Follower / Learner Read 机制来实现直接在 TiFlash 节点读数据。原理是利用了 Raft Log 的偏移量 + 全局时间戳的特性。首先在请求发起的时候获取一个 read ts,那么对于所有的 Region(Region 是 TiDB 内部数据切割单位,也是 Raft Group 单位),只要确定本地 Region 副本已经同步到足够新的 Raft Log,那么直接读这个 Region 副本就是安全的。可以利用 MVCC 的特性,对于每一条 unique key,过滤出 commit ts<= read ts 的所有版本,其中 commit ts 最大的版本就是我们应该读取的版本。
这里的问题是,Learner 如何知道当前 Region 副本足够新呢?实时上 Learner 在读数据之前,会带上 read ts 向 Leader 发起一次请求,从而获得确保 Region 足够新的 Raft Log 的偏移量。TiFlash 目前的实现是在本地 Region 副本同步到足够新之前,会等待直到超时。未来我们会加上其他策略,比如主动要求同步数据(如图 6 和图 7 所示)。
4. 更新支持
TiFlash 会同步 TiKV 上的表的所有变更,是两个异构的系统之间同步数据,会遇到一些很困难的问题。其中比较有代表性的是如何让 TiFlash 能实时复制 TiKV 的更新,并且是实时、事务性的更新。通常我们认为列式存储的更新相对困难,因为列存往往使用块压缩,并且块相对于行存更大,容易增加写放大。而分列存储也更容易引起更多的小 IO。另外由于 AP 的业务特点,需要大量 Scan 操作,如何在高速更新的同时保证 Scan 性能,也是很大的问题。
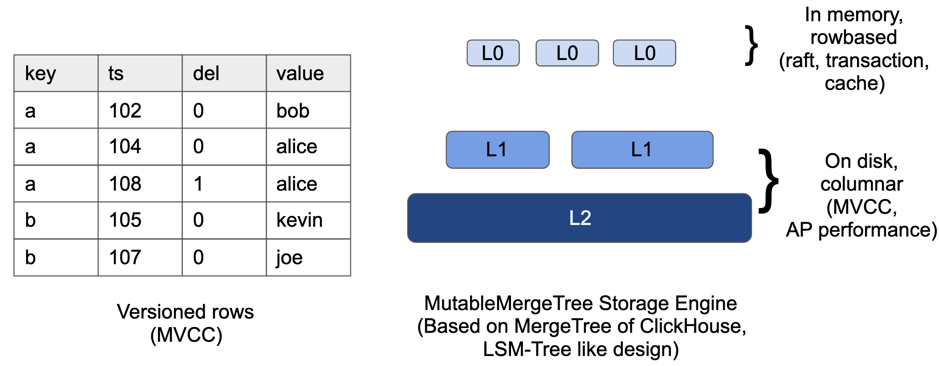
目前 TiFlash 的方案是,存储引擎使用类 LSM-Tree 的存储架构,并且使用 MVCC 来实现和 TiDB 一致的 SI 隔离级别。LSM-Tree 架构可以很好的处理 TP 类型的高频小 IO 写入;同时又有的一定的局部有序性,有利于做 Scan 优化。
四、TiFlash 带来的想象空间
在新的业务纬度上让 TiDB 更加 Scalable。通过引入全新的 TiFlash AP 扩展,让 TiDB 拥有了真正的 AP 能力,即为 AP 专门优化的存储和计算。我们可以通过增减相对应的节点,动态的增减 TiDB 系统的 TP 或者 AP 端的能力。数据不再需要在两个独立的系统之间手动同步,并且可以保证实时性、事务性。
AP 与 TP 业务的隔离性,让 TiDB 的 AP 业务对线上的 TP 影响降到最低。因为 TiFlash 是独立节点,通常和 TiKV 分开部署,所以可以做到硬件级别的资源隔离。我们在 TiDB 系统中使用标签来管理不同类型的存储节点。
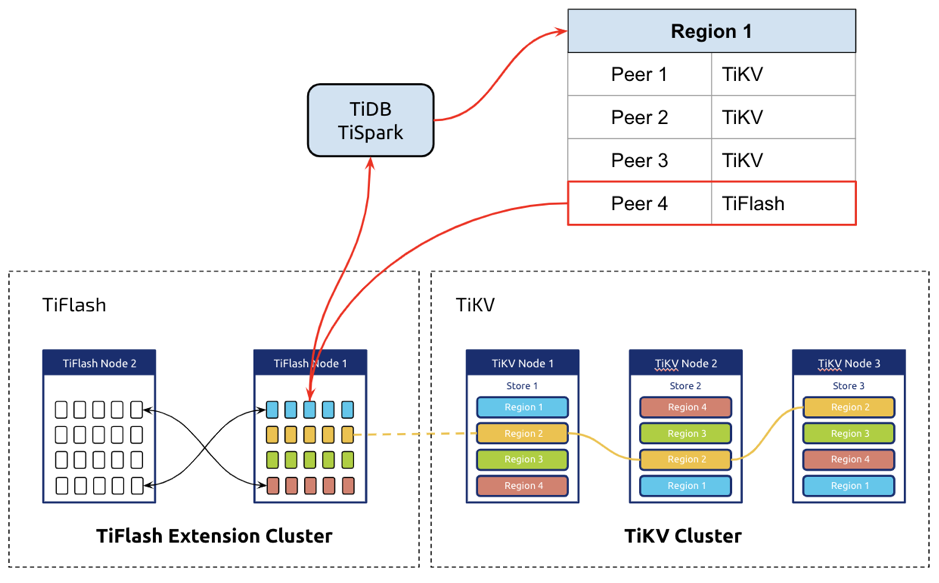
从 TiDB 的视角,TiFlash 和 TiKV 从层次上是一致的,都是存储节点。区别在于它们在启动时候给 PD (PD 为 TiDB 集群的 Coordinator)上报的节点标签。TiDB 就可以利用这些信息,把不同类型的请求路由到相应的节点。比如我们可以根据一些启发试算法,以及统计信息,了解到一条 SQL 需要 Scan 大量的数据并且做聚合运算,那么显然这条 SQL 的 Scan 算子去 TiFlash 节点请求数据会更合理。而这些繁重的 IO 和计算并不会影响 TiKV 侧的 TP 业务。
TiFlash 带来了全新的融合体验。TiFlash 节点并不只是单纯的从 TiKV 节点同步数据,它们其实可以有进一步的配合,带来 1+1>2 的效果。上层的计算层,TiDB 或者 TiSpark,是可以同时从 TiFlash 和 TiKV 读取数据的。
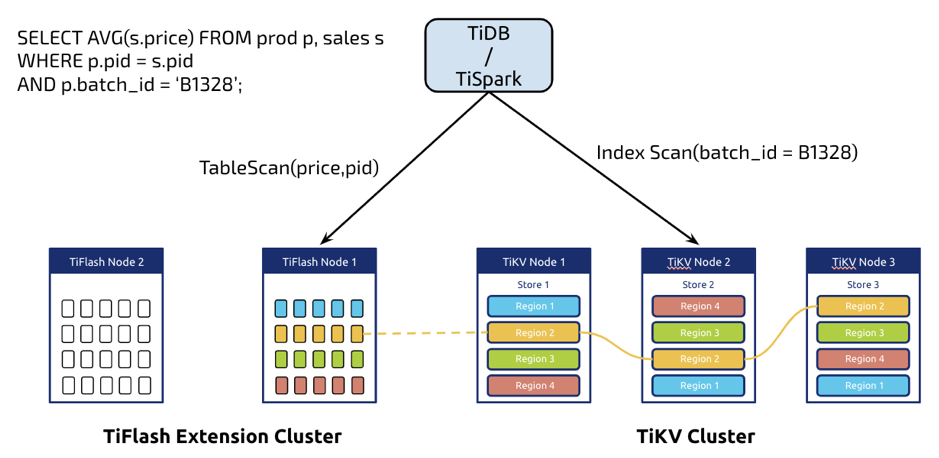
如图 10 所示,比如我们遇到一条 SQL,它需要 join 两份数据,其中一份数据需要全表扫描,另外一份则可以走索引,那么很显然可以同时利用 TiFlash 强大的 Scan 和 TiKV 的点查。值得一提的是,用户通常会配置 3 或 5 份副本在 TiKV,为了节约成本,可能只部署 1 份副本到 TiFlash。那么当一个 TiFlash 节点挂掉之后,我们就需要重新从 TiKV 同步节点。
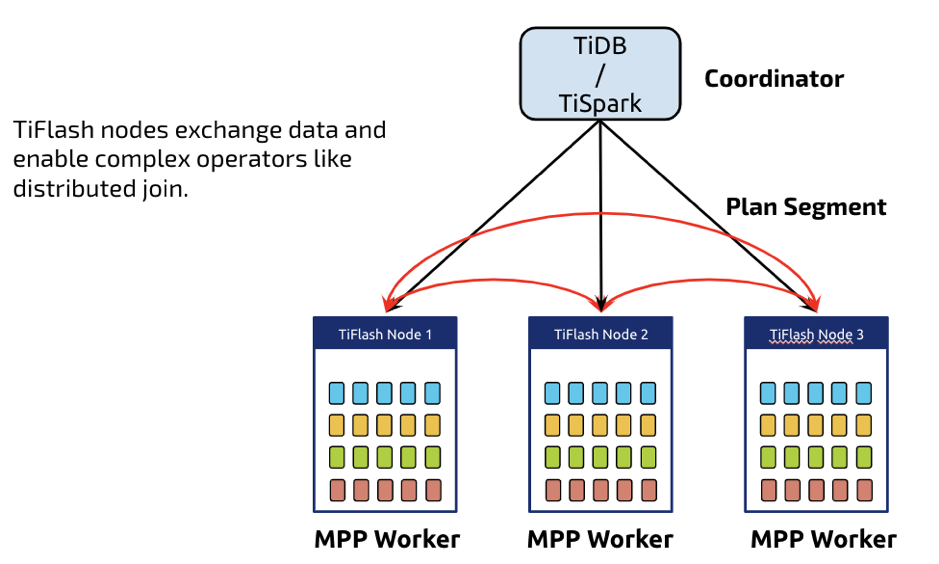
我们接下来计划让 TiFlash 节点成为 MPP 集群。即 TiDB 或者 TiSpark 接收到 SQL 之后,可以选择把计算完全下推。MPP 主要是为了进一步提升 AP 的计算效率。
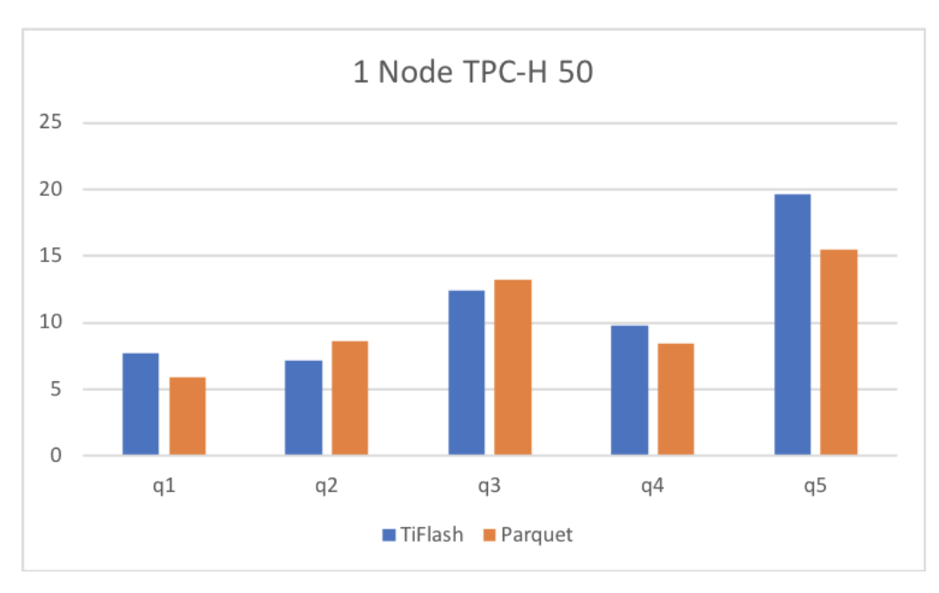
上图是 TiFlash 某一个版本的性能数据,我们使用 TiSpark + TiFlash 来对比 Spark + Parquet。可以看到 TiFlash 在支持了实时 update 和事务一致性的情况下,仍然达到了基本一致的性能。TiFlash 目前还在快速迭代之中,最新版本相对于这里其实已经有很大幅度的提升。另外我们目前正在研发一款专门为 TiFlash 全新设计的存储引擎,至少带来 2 倍的性能提升。可以期待一下之后出来的性能。
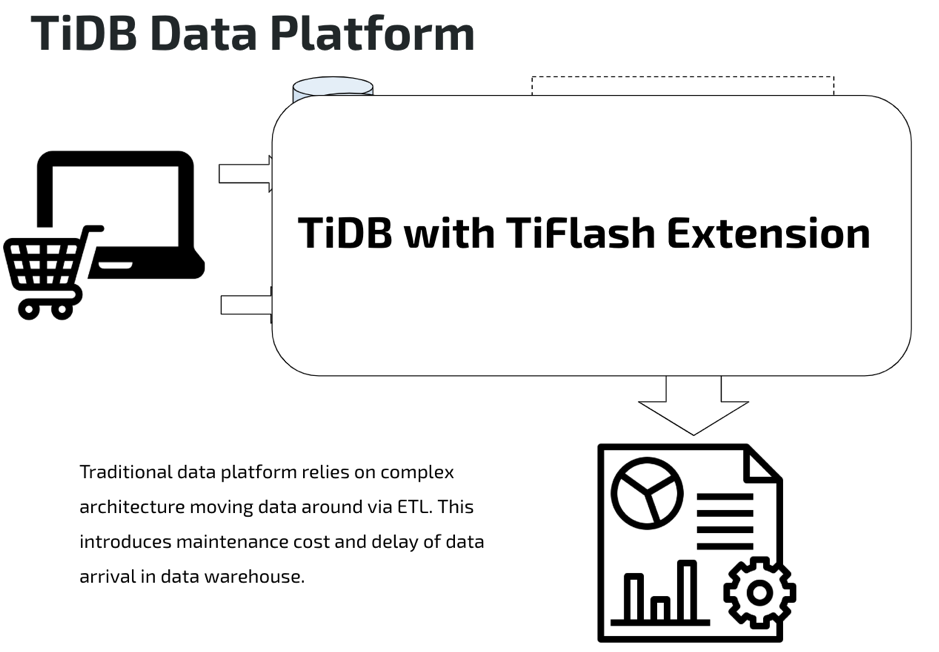
简单就是生产力。传统的数据平台由于技术的限制,企业需要做非常繁重的建设工作。需要把许多技术整合在一起才能实现业务需求,而系统之间使用复杂繁琐的 ETL 过程同步数据,导致数据链条很长,效果也不一定好。TiDB 希望把系统的复杂性留在工具层面,从而大幅度简化用户的应用架构。
目前 TiFlash 正在与部分合作伙伴进行内部 POC,预计年底之前会发布一个 GA 版本,敬请期待。
(对 TiFlash 感兴趣的朋友欢迎私聊作者,交流更多技术细节~ weiwan@pingcap.com)
共同学习,写下你的评论
评论加载中...
作者其他优质文章



