
spark的orderby算法类似于桶排序,有三个阶段:
1. 抽样确定bound
2. 根据bound进行shuffle write
3. shuffle read 并在内存中排序
接下来开始实验:
配置为两台物理机master1和slave5:
master1: 4cores, 4g mem executor0: 4cores, 1g mem
slave5: 4cres, 4g mem executor1: 4cores, 1g mem
数据:
2g数据集共5百万条记录保存在master1的hdfs上
程序逻辑很简单:spark.read.orderby.write
driver在master1上
我们先分析spark的ui记录,再根据ganglia的数据做进一步的分析
jobs如下:有3个job共运行大约15分钟
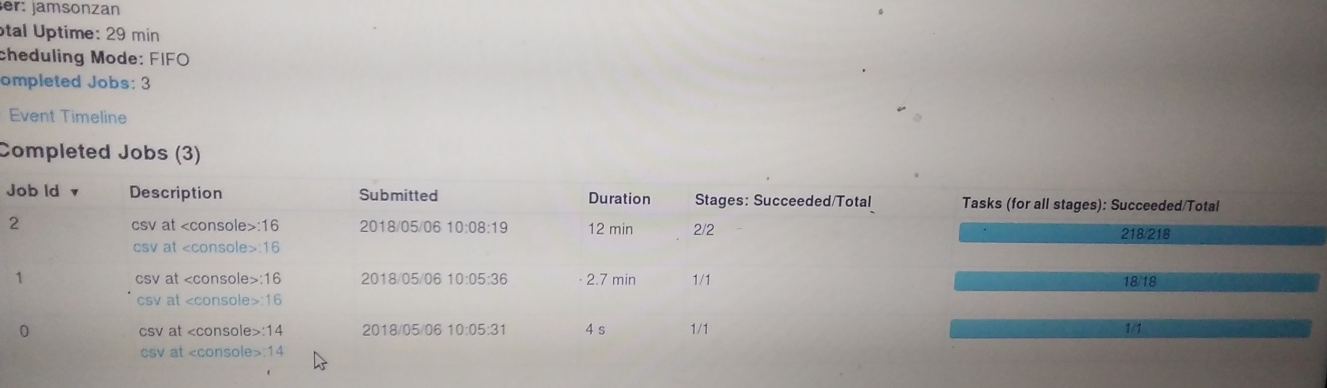
job0由master1读取了一个128m的数据,我觉得这个job的作用是获取数据类型,列名等,这样如果程序有逻辑错误就可以在编译时抛出, 不过程序中的数据结构应该是dataset[T], T 不能是 ROW
job1是全表扫描并进行抽样的过程,tasks如下:
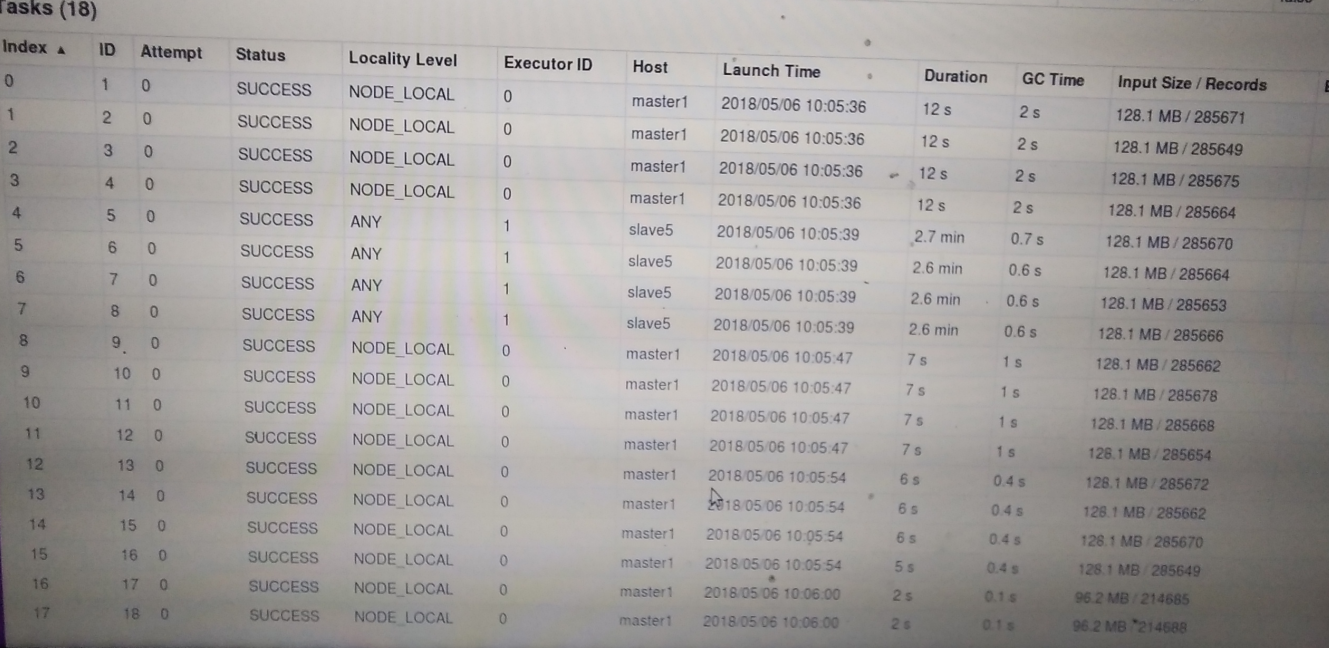
疑惑点:master1第一次读取4个分区时gc时间,gc是jvm内存不够用时发生的,为什么一开始就发生了,而且后面发生的gc时间反而更短,slave5的gc 为0.6秒 是不是因为drvie在master1上?
还有一个值得注意的地方是slave5运行极慢,master1完成了14个分区,它还没有完成,整个job1的时间就是task4的时间
我的想法:hdfs在master1上, 网络io拖慢了速度
接下来看job2:有两个stage: 一个shuffle write, 一个shuffle read后排序并output到master1上
stage1根据job1的抽样结果进行write, 任务分配和job1类似 也是slave5只完成4个task 这是job1导致的
18个task运行完大约2min,是master1运行完14个task的时间,可以看到由于job1的分配不均衡造成了slave5极大的cpu资源浪费
stage2是shuffle write过程:
shuffle后共200个分区,任务分配较均衡,指标总览图已经能很好说明问题,如下:
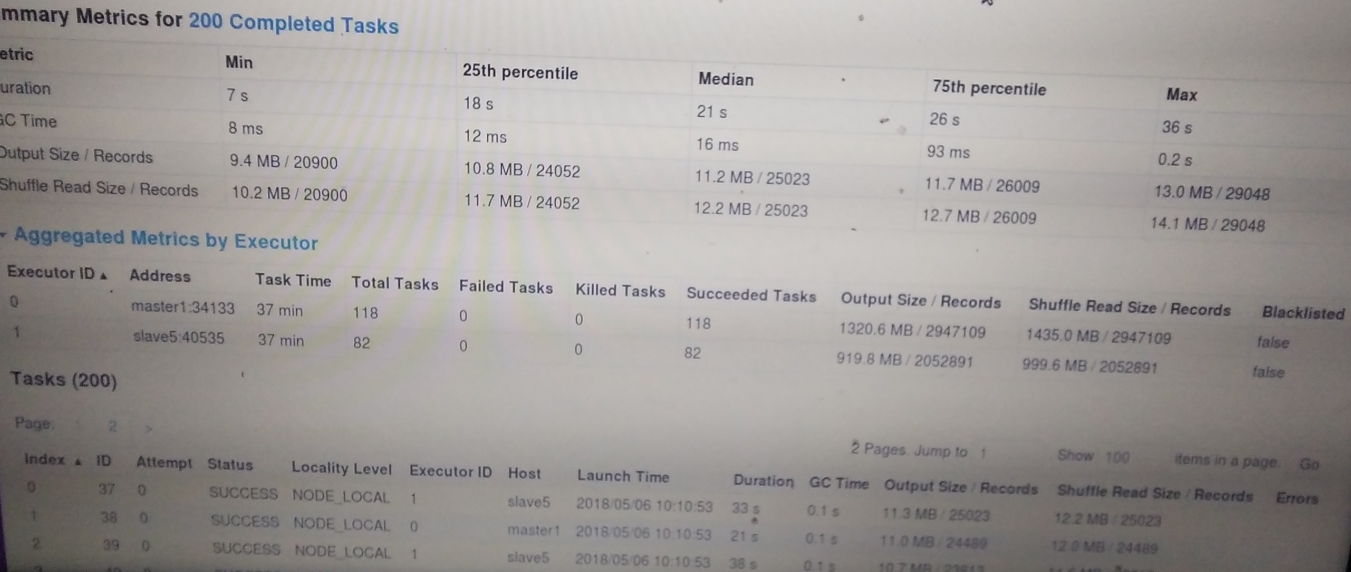
因为read的数据大部分在master1上
还是可以看出由于网络io慢导致slave5干活慢进而减少了干活总量
不过两台机器运行总时间相近,并没有出现像前面那样由于任务分配不均衡导致一台机在空等的情况
接下来分析ganglia的报告,主要的图:
master1:
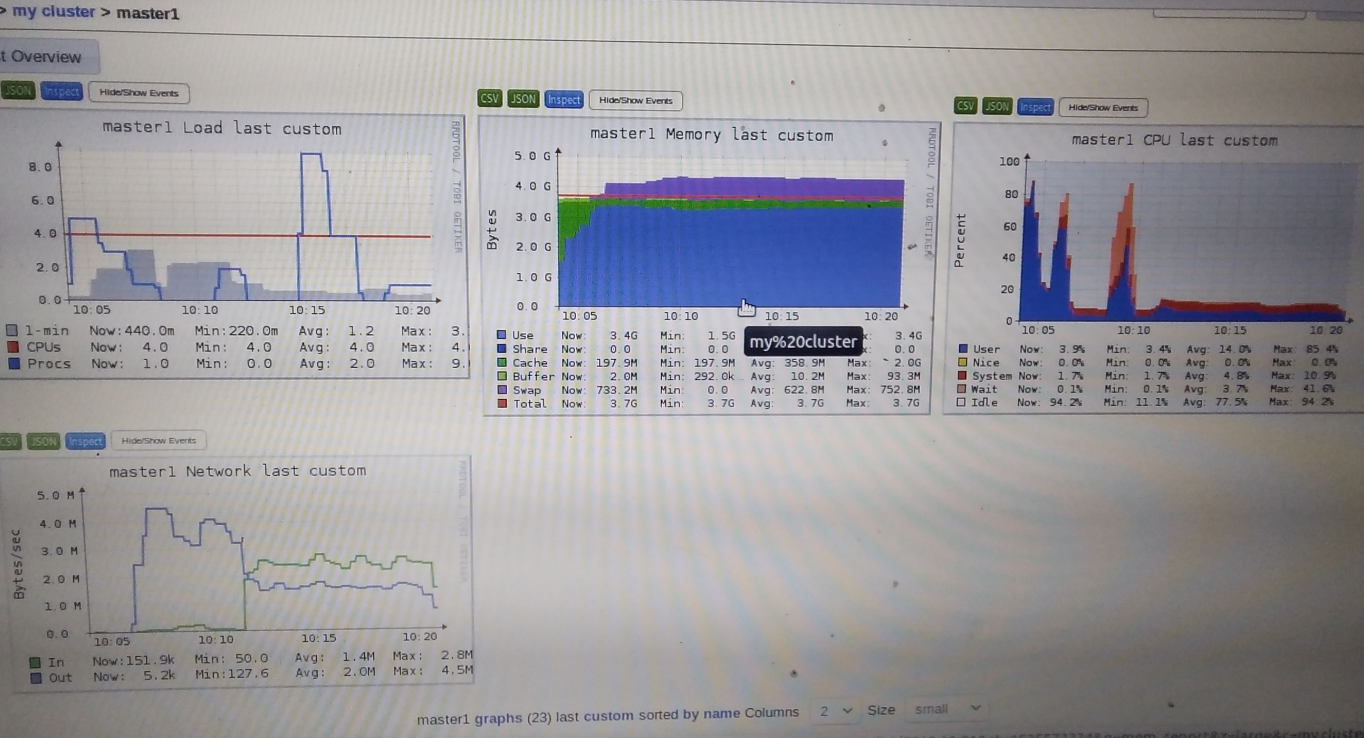
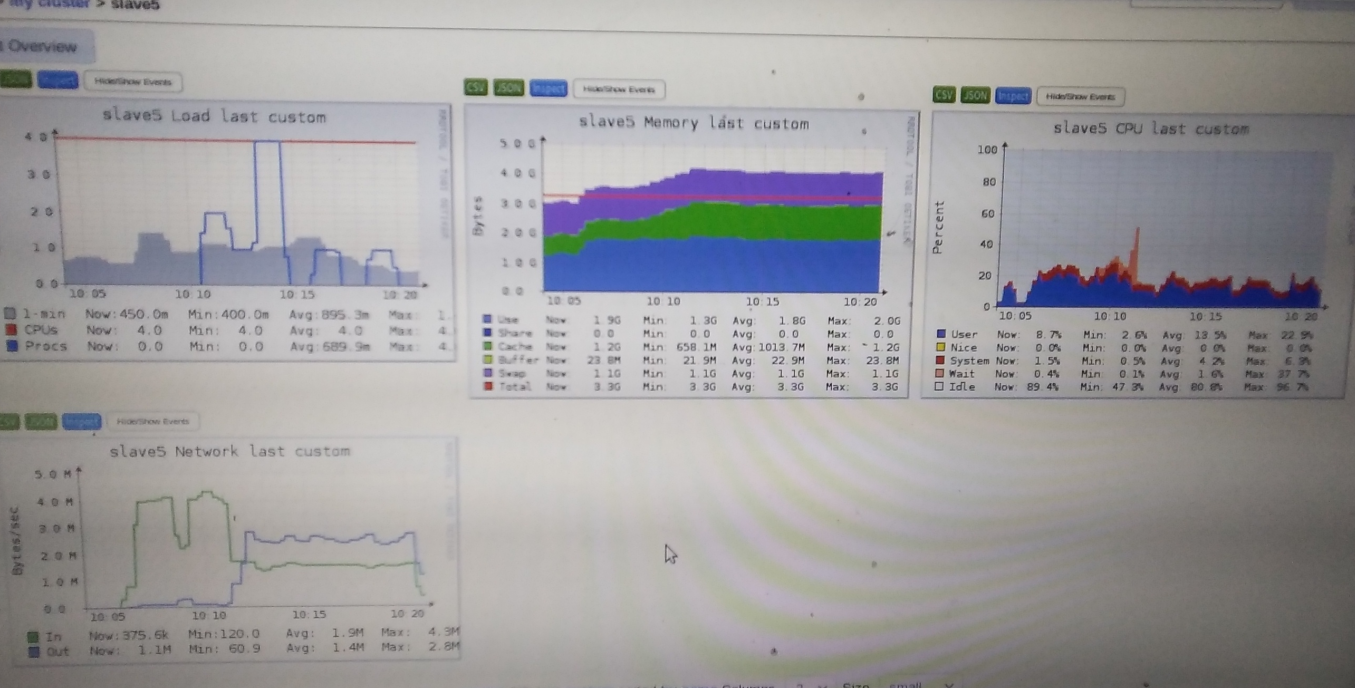
slave5:
spark应用提交时间在10:05
先分析slave5:
slave5先在master1读取大约512M数据
可以看到网络io大约4MB/s 第一个io高峰大约150s, 也就是2.5分钟
疑惑点:slave5的4个task都持续2.7分钟,也就是说
4个分区都到了再一起处理的,为什么不到了一个分区后马上处理?
网络io阶段,和io后的cpu占用(对应cpu10:05后的第一个小高峰)并没有明显不同,spark用的是水塘抽样算法,按理说cpu占用应该较多?
结合两个疑惑,提出猜想:
抽样时并不需要等某个分区到达,而是到了几行数据就马上处理,这样cpu的占用就分摊在了网络io阶段,有一种流水线式的感觉
所以网络io完成,抽样也差不多完成了
接下来是shuffle write:时间在10:08到10:11
storage + executor 内存 = 1g *0.6 其中executor内存1g*0.6*0.5=300M对于512M的数据是有spill到磁盘上的(disk图可以验证),奇怪的是spark ui并没有spill(disk)的记录,对于master1也没找到
疑惑点:
第二个网络io高峰大约240M数据量是干什么去了?shuffle write不需要这么大量的网络io啊 还是抽样后送到drvier确定bound需要240M?
cpu为什么会有一个wait io指标,当进行io时操作系统不是会挂起进程防止它占用cpu吗,更奇怪的是为什么前面读取数据和后面的写入又没出现这个指标
再看后面的shuffle read并output时间段除了前面提到的wait io问题就比较正常,没有什么疑惑
接下来看master1:开的东西比较多,内存有点吃紧
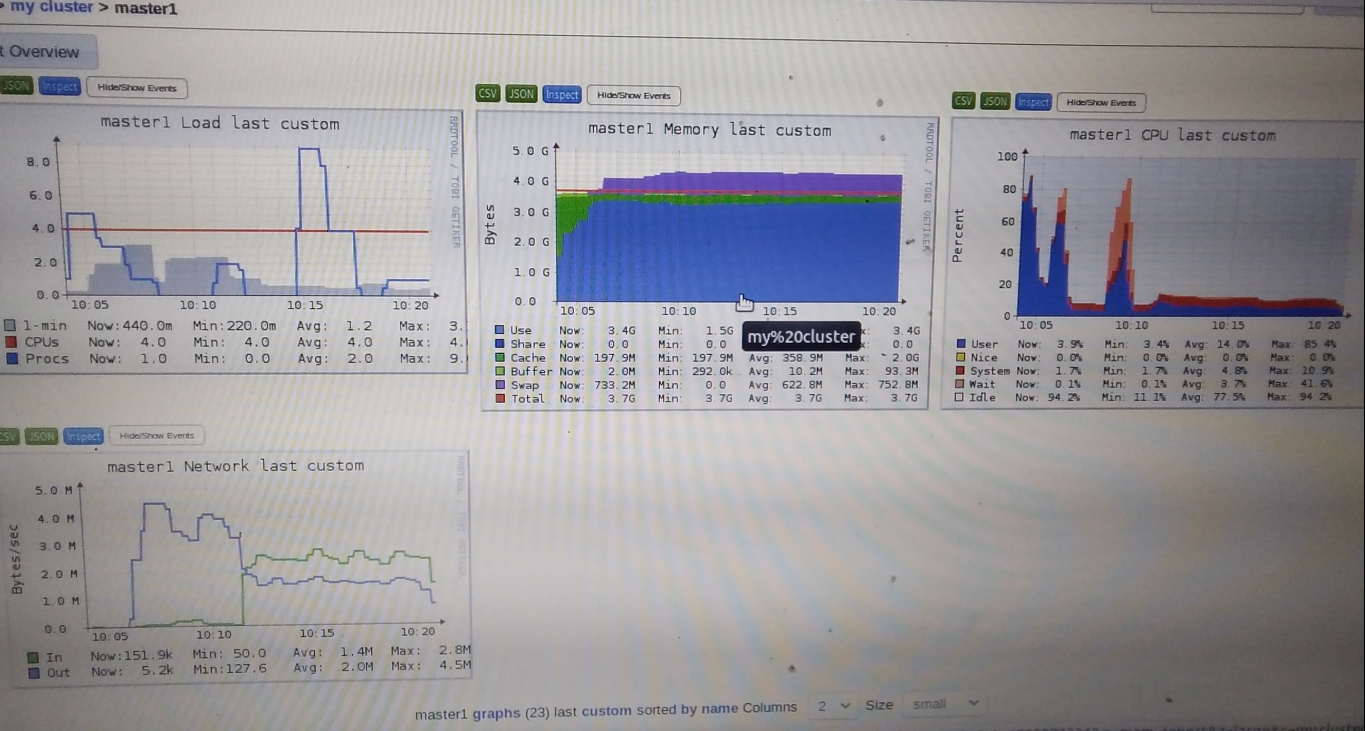
除了slave5分析的一些情况,以下为master1关注点:
swap区的应该是别的应用程序,内存被spark抢去了
疑惑点:master1任务应该是比较重的,然而除了几个高峰段的cpu占用居然比slave5低?
以上为理论分析和实验对比之后的个人理解和疑惑点,结!
共同学习,写下你的评论
评论加载中...
作者其他优质文章



