
作者:Su Li,Zhang Ming
Java 是当前非常流行的开发语言,很多 TiDB 用户的业务层都是使用 Java 开发的,本文将从 Java 数据库交互组件开发的角度出发,介绍各组件的推荐配置和推荐使用方式,希望能帮助 Java 开发者在使用 TiDB 时能更好的发挥数据库性能。
Java 应用中的数据库相关组件
通常 Java 应用中和数据库相关的常用组件有:
-
网络协议:客户端通过标准 MySQL 协议 和 TiDB 进行网络交互。
-
JDBC API 及实现:Java 应用通常使用 JDBC (Java Database Connectivity) 来访问数据库。JDBC 定义了访问数据库 API,而 JDBC 实现完成标准 API 到 MySQL 协议的转换,常见的 JDBC 实现是 MySQL Connector/J,此外有些用户可能使用 MariaDB Connector/J。
-
数据库连接池:为了避免每次创建连接,通常应用会选择使用数据库连接池来复用连接,JDBC DataSource 定义了连接池 API,开发者可根据实际需求选择使用某种开源连接池实现。
-
数据访问框架:应用通常选择通过数据访问框架(MyBatis、Hibernate)的封装来进一步简化和管理数据库访问操作。
-
业务实现:业务逻辑控制着何时发送和发送什么指令到数据库,其中有些业务会使用 Spring Transaction 切面来控制管理事务的开始和提交逻辑。
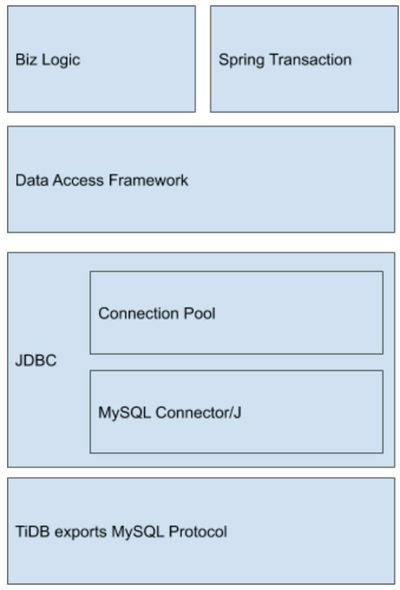
如上图所示,应用可能使用 Spring Transaction 来管理控制事务非手工启停,通过类似 MyBatis 的数据访问框架管理生成和执行 SQL,通过连接池获取已池化的长连接,最后通过 JDBC 接口调用实现通过 MySQL 协议和 TiDB 完成交互。
接下来将分别介绍使用各个组件时可能需要关注的问题。
JDBC
Java 应用尽管可以选择在不同的框架中封装,但在最底层一般会通过调用 JDBC 来与数据库服务器进行交互。对于 JDBC,需要关注的主要有:API 的选择和 API Implementer 的参数配置。
1. JDBC API
对于基本的 JDBC API 使用可以参考 JDBC 官方教程,本文主要强调几个比较重要的 API 选择。
1.1 使用 Prepare API
对于 OLTP 场景,程序发送给数据库的 SQL 语句在去除参数变化后都是可穷举的某几类,因此建议使用 预处理语句 (Prepared Statements) 代替普通的 文本执行,并复用 Prepared Statements 来直接执行,从而避免 TiDB 重复解析的开销。
目前多数上层框架都会调用 Prepare API 进行 SQL 执行,如果直接使用 JDBC API 进行开发,注意选择使用 Prepare API。
另外需要注意 MySQL Connector/J 实现中默认只会做客户端的语句预处理,会将 ? 在客户端替换后以文本形式发送到客户端,所以除了要使用 Prepare API,还需要在 JDBC 连接参数中配置 useServerPrepStmts = true,才能在 TiDB 服务器端进行语句预处理(下面参数配置章节有详细介绍)。
1.2 使用 Batch 批量插入更新
对于批量插入更新,如果插入记录较多,可以选择使用 addBatch/executeBatch API。通过 addBatch 的方式将多条 SQL 的插入更新记录先缓存在客户端,然后在 executeBatch 时一起发送到数据库服务器。
注意:
对于 MySQL Connector/J 实现,默认 Batch 只是将多次
addBatch的 SQL 发送时机延迟到调用executeBatch的时候,但实际网络发送还是会一条条的发送,通常不会降低与数据库服务器的网络交互次数。如果希望 Batch 网络发送批量插入,需要在 JDBC 连接参数中配置
rewriteBatchedStatements=true(下面参数配置章节有详细介绍)。
1.3 使用 StreamingResult 流式获取执行结果
一般情况下,为提升执行效率,JDBC 会默认提前获取查询结果并将其保存在客户端内存中。但在查询返回超大结果集的场景中,客户端会希望数据库服务器减少向客户端一次返回的记录数,等客户端在有限内存处理完一部分后再去向服务器要下一批。
在 JDBC 中通常有以下两种处理方式:
-
设置
FetchSize为Integer.MIN_VALUE让客户端不缓存,客户端通过StreamingResult的方式从网络连接上流式读取执行结果。 -
使用 Cursor Fetch 首先需 设置
FetchSize为正整数且在 JDBC URL 中配置useCursorFetch=true。
TiDB 中同时支持两种方式,但更推荐使用第一种将 FetchSize 设置为 Integer.MIN_VALUE 的方式,比第二种功能实现更简单且执行效率更高。
2. MySQL JDBC 参数
JDBC 实现通常通过 JDBC URL 参数的形式来提供实现相关的配置。这里以 MySQL 官方的 Connector/J 来介绍 参数配置(如果使用的是 MariaDB,可以参考 MariaDB 的类似配置)。因为配置项较多,这里主要关注几个可能影响到性能的参数。
2.1 Prepare 相关参数
useServerPrepStmts
默认情况下,useServerPrepStmts 为 false,即尽管使用了 Prepare API,也只会在客户端做 “prepare”。因此为了避免服务器重复解析的开销,如果同一条 SQL 语句需要多次使用 Prepare API,则建议设置该选项为 true。
在 TiDB 监控中可以通过 Query Summary > QPS By Instance 查看请求命令类型,如果请求中 COM_QUERY 被 COM_STMT_EXECUTE 或 COM_STMT_PREPARE 代替即生效。
cachePrepStmts
虽然 useServerPrepStmts=true 能让服务端执行 prepare 语句,但默认情况下客户端每次执行完后会 close prepared 的语句,并不会复用,这样 prepare 效率甚至不如文本执行。所以建议开启 useServerPrepStmts=true 后同时配置 cachePrepStmts=true,这会让客户端缓存 prepare 语句。
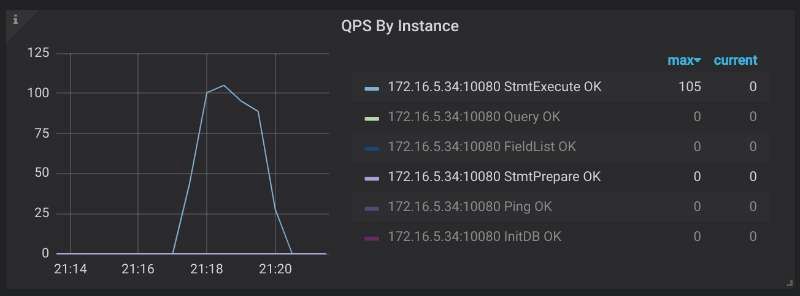
在 TiDB 监控中可以通过 Query Summary > QPS By Instance 查看请求命令类型,如果类似下图,请求中 COM_STMT_EXECUTE 数目远远多于 COM_STMT_PREPARE 即生效。
另外,通过 useConfigs=maxPerformance 配置会同时配置多个参数,其中也包括 cachePrepStmts=true。
prepStmtCacheSqlLimit
在配置 cachePrepStmts 后还需要注意 prepStmtCacheSqlLimit 配置(默认为 256),该配置控制客户端缓存 prepare 语句的最大长度,超过该长度将不会被缓存。
在一些场景 SQL 的长度可能超过该配置,导致 prepared SQL 不能复用,建议根据应用 SQL 长度情况决定是否需要调大该值。
在 TiDB 监控中通过 Query Summary > QPS by Instance 查看请求命令类型,如果已经配置了 cachePrepStmts=true,但 COM_STMT_PREPARE 还是和 COM_STMT_EXECUTE 基本相等且有 COM_STMT_CLOSE,需要检查这个配置项是否设置得太小。
prepStmtCacheSize
prepStmtCacheSize 控制缓存的 prepare 语句数目(默认为 25),如果应用需要 prepare 的 SQL 种类很多且希望复用 prepare 语句,可以调大该值。
和上一条类似,在监控中通过 Query Summary > QPS by Instance 查看请求中 COM_STMT_EXECUTE 数目是否远远多于 COM_STMT_PREPARE 来确认是否正常。
2.2 Batch 相关参数
在进行 batch 写入处理时推荐配置 rewriteBatchedStatements=true,在已经使用 addBatch 或 executeBatch 后默认 JDBC 还是会一条条 SQL 发送,例如:
pstmt = prepare(“insert into t (a) values(?)”);
pstmt.setInt(1, 10);
pstmt.addBatch();
pstmt.setInt(1, 11);
pstmt.addBatch();
pstmt.setInt(1, 12);
pstmt.executeBatch();
虽然使用了 batch 但发送到 TiDB 语句还是单独的多条 insert:
insert into t(a) values(10);
insert into t(a) values(11);
insert into t(a) values(12);
如果设置 rewriteBatchedStatements=true,发送到 TiDB 的 SQL 将是:
insert into t(a) values(10),(11),(12);
需要注意的是,insert 语句的改写,只能将多个 values 后的值拼接成一整条 SQL,insert 语句如果有其他差异将无法被改写。 例如:
insert into t (a) values (10) on duplicate key update a = 10;
insert into t (a) values (11) on duplicate key update a = 11;
insert into t (a) values (12) on duplicate key update a = 12;
将无法被改写成一条语句。该例子中,如果将 SQL 改写成如下形式:
insert into t (a) values (10) on duplicate key update a = values(a);
insert into t (a) values (11) on duplicate key update a = values(a);
insert into t (a) values (12) on duplicate key update a = values(a);
即可满足改写条件,最终被改写成:
insert into t (a) values (10), (11), (12) on duplicate key update a = values(a);
批量更新时如果有 3 处或 3 处以上更新,则 SQL 语句会改写为 multiple-queries 的形式并发送,这样可以有效减少客户端到服务器的请求开销,但副作用是会产生较大的 SQL 语句,例如这样:
update t set a = 10 where id = 1; update t set a = 11 where id = 2; update t set a = 12 where id = 3;
另外因为一个 客户端 bug,不建议在批量 insert 以外的场景设置 rewriteBatchedStatements=true。
2.3 执行前检查参数
通过监控可能会发现,虽然业务只向集群进行 insert 操作,却看到有很多多余的 select 语句。通常这是因为 JDBC 发送了一些查询设置类的 SQL 语句(例如 select @@session.transaction_read_only)。这些 SQL 对 TiDB 无用,推荐配置 useConfigs=maxPerformance 来避免额外开销。
useConfigs=maxPerformance 会包含一组配置:
cacheServerConfiguration=true
useLocalSessionState=true
elideSetAutoCommits=true
alwaysSendSetIsolation=false
enableQueryTimeouts=false
配置后查看监控可以看到多余语句减少。
连接池
TiDB (MySQL) 连接建立是比较昂贵的操作(至少对于 OLTP),除了建立 TCP 连接外还需要进行连接鉴权操作,所以客户端通常会把 TiDB (MySQL) 连接保存到连接池中进行复用。
Java 的连接池实现很多(比如,HikariCP, tomcat-jdbc, durid, c3p0, dbcp),TiDB 不会限定使用的连接池,应用可以根据业务特点自行选择连接池实现。
1. 连接数配置
比较常见的是应用需要根据自身情况配置合适的连接池大小,以 HikariCP 为例:
-
maximumPoolSize:连接池最大连接数,配置过大会导致 TiDB 消耗资源维护无用连接,配置过小则会导致应用获取连接变慢,所以需根据应用自身特点配置合适的值,可参考 这篇文章。 -
minimumIdle:连接池最大空闲连接数,主要用于在应用空闲时存留一些连接以应对突发请求,同样是需要根据业务情况进行配置。
应用在使用连接池时需要注意连接使用完成后归还连接,推荐应用使用对应的连接池相关监控(如 metricRegistry),通过监控能及时定位连接池问题。
2. 探活配置
连接池维护到 TiDB 的长连接,TiDB 默认不会主动关闭客户端连接(除非报错),但一般客户端到 TiDB 之间还会有 LVS 或 HAProxy 之类的网络代理,它们通常会在连接空闲一定时间后主动清理连接。除了注意代理的 idle 配置外,连接池还需要进行保活或探测连接。
如果常在 Java 应用中看到以下错误:
The last packet sent successfully to the server was 3600000 milliseconds ago. The driver has not received any packets from the server. com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
如果 n milliseconds ago 中的 n 是 0 或很小的值,则通常是执行的 SQL 导致 TiDB 异常退出引起的报错,推荐查看 TiDB stderr 日志;如果 n 是一个非常大的值(比如这里的 3600000),很可能是因为这个连接空闲太久然后被中间 proxy 关闭了,通常解决方式除了调大 proxy 的 idle 配置,还可以让连接池:
-
每次使用连接前检查连接是否可用。
-
使用单独线程定期检查连接是否可用。
-
定期发送 test query 保活连接。
不同的连接池实现可能会支持其中一种或多种方式,可以查看所使用的连接池文档来寻找对应配置。
数据访问框架
业务应用通常会使用某种数据访问框架来简化数据库的访问。
1. MyBatis
MyBatis 是目前比较流行的 Java 数据访问框架,主要用于管理 SQL 并完成结果集和 Java 对象的来回映射工作。MyBatis 和 TiDB 兼容性很好,从历史 issue 可以看出 MyBatis 很少出现问题。这里主要关注如下几个配置。
1.1 Mapper 参数
MyBatis 的 Mapper 中支持两种参数:
-
select 1 from t where id = #{param1}会作为 prepare 语句转换为select 1 from t where id = ?进行 prepare, 并使用实际参数来复用执行,通过配合前面的 Prepare 连接参数能获得最佳性能。 -
select 1 from t where id = ${param2}会做文本替换为select 1 from t where id = 1执行,如果这条语句被 prepare 成了不同参数,可能会导致 TiDB 缓存大量的 prepare 语句,并且这种方式执行 SQL 有注入安全风险。
1.2 动态 SQL Batch
要支持将多条 insert 语句自动重写为 insert ... values(...), (...), ... 的形式,除了前面所说的在 JDBC 配置 rewriteBatchedStatements=true 外,MyBatis 还可以使用动态 SQL 的 foreach 语法 来半自动生成 batch insert。比如下面的 mapper:
<insert id="insertTestBatch" parameterType="java.util.List" fetchSize="1">
insert into test
(id, v1, v2)
values
<foreach item="item" index="index" collection="list" separator=",">
(
#{item.id}, #{item.v1}, #{item.v2}
)
</foreach>
on duplicate key update v2 = v1 + values(v1)
</insert>
会生成一个 insert on duplicate key update 语句,values 后面的 (?, ?, ?) 数目是根据传入的 list 个数决定,最终效果和使用 rewriteBatchStatements=true 类似,可以有效减少客户端和 TiDB 的网络交互次数,同样需要注意 prepare 后超过 prepStmtCacheSqlLimit 限制导致不缓存 prepare 语句的问题。
1.3 Streaming 结果
前面介绍了在 JDBC 中如何使用流式读取结果,除了 JDBC 相应的配置外,在 MyBatis 中如果希望读取超大结果集合也需要注意:
-
可以通过在 mapper 配置中对单独一条 SQL 设置
fetchSize(见上一段代码段),效果等同于调用 JDBC setFetchSize。 -
可以使用带 ResultHandler 的查询接口来避免一次获取整个结果集。
-
可以使用 Cursor 类来进行流式读取。
对于使用 xml 配置映射,可以通过在映射 <select> 部分配置 fetchSize="-2147483648"(Integer.MIN_VALUE) 来流式读取结果。
<select id="getAll" resultMap="postResultMap" fetchSize="-2147483648">
select * from post;
</select>
而使用代码配置映射,则可以使用 @Options(fetchSize = Integer.MIN_VALUE) 并返回 Cursor 从而让 SQL 结果能被流式读取。
@Select("select * from post")
@Options(fetchSize = Integer.MIN_VALUE)
Cursor<Post> queryAllPost();
2. ExecutorType
在 openSession 的时候可以选择 ExecutorType,MyBatis 支持三种 executor:
-
Simple:每次执行都会向 JDBC 进行 prepare 语句的调用(如果 JDBC 配置有开启cachePrepStmts,重复的 prepare 语句会复用)。 -
Reuse:在 executor 中缓存 prepare 语句,这样不用 JDBC 的cachePrepStmts也能减少重复 prepare 语句的调用。 -
Batch:每次更新只有在addBatch到 query 或 commit 时才会调用executeBatch执行,如果 JDBC 层开启了rewriteBatchStatements,则会尝试改写,没有开启则会一条条发送。
通常默认值是 Simple,需要在调用 openSession 时改变 ExecutorType。如果是 Batch 执行,会遇到事务中前面的 update 或 insert 都非常快,而在读数据或 commit 事务时比较慢的情况,这实际上是正常的,在排查慢 SQL 时需要注意。
Spring Transaction
在应用代码中业务可能会通过使用 Spring Transaction 和 AOP 切面的方式来启停事务。
通过在方法定义上添加 @Transactional 注解标记方法,AOP 将会在方法前开启事务,方法返回结果前 commit 事务。如果遇到类似业务,可以通过查找代码 @Transactional 来确定事务的开启和关闭时机。需要特别注意有内嵌的情况,如果发生内嵌,Spring 会根据 Propagation 配置使用不同的行为,因为 TiDB 未支持 savepoint,所以不支持嵌套事务。
排查工具
在 Java 应用发生问题并且不知道业务逻辑情况下,使用 JVM 强大的排查工具会比较有用。这里简单介绍几个常用工具:
1. jstack
jstack 对应于 Go 中的 pprof/goroutine,可以比较方便地排查进程卡死的问题。
通过执行 jstack pid,即可输出目标进程中所有线程的线程 id 和堆栈信息。输出中默认只有 Java 堆栈,如果希望同时输出 JVM 中的 C++ 堆栈,需要加 -m 选项。
通过多次 jstack 可以方便地发现卡死问题(比如:都通过 Mybatis BatchExecutor flush 调用 update)或死锁问题(比如:测试程序都在抢占应用中某把锁导致没发送 SQL)
另外,top -p $PID -H 或者 Java swiss knife 都是常用的查看线程 ID 的方法。通过 printf "%x\n" pid 把线程 ID 转换成 16 进制,然后去 jstack 输出结果中找对应线程的栈信息,可以定位“某个线程占用 CPU 比较高,不知道它在执行什么”的问题。
2. jmap & mat
通过 mat 可以看到进程中所有对象的关联信息和属性,还可以观察线程运行的状态。比如:我们可以通过 mat 找到当前应用中有多少 MySQL 连接对象,每个连接对象的地址和状态信息是什么。
需要注意 mat 默认只会处理 reachable objects,如果要排查 young gc 问题可以在 mat 配置中设置查看 unreachable objects。另外对于调查 young gc 问题(或者大量生命周期较短的对象)的内存分配,用 Java Flight Recorder 比较方便。
3. trace
线上应用通常无法修改代码,又希望在 Java 中做动态插桩来定位问题,推荐使用 btrace 或 arthas trace。它们可以在不重启进程的情况下动态插入 trace 代码。
4. 火焰图
Java 应用中获取火焰图较繁琐,可参阅 Java Flame Graphs Introduction: Fire For Everyone! 来手动获取。
总结
本文从常用 Java 数据库交互组件的角度,阐述了开发 Java 应用程序使用 TiDB 的常见问题与解决办法。TiDB 是高度兼容 MySQL 协议的数据库,基于 MySQL 开发的 Java 应用的最佳实践也多适用于 TiDB。如果大家在使用上遇到了任何问题,可以在 asktug.com 提问,也欢迎更多小伙伴和我们一起分享讨论 Java 应用使用 TiDB 的实践技巧。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


