
已经有大约半年的时间没有碰C语言了,当时学习的时候记录了很多的笔记,但是都是特别混乱,后悔那个时候,不懂得写博客,这里凭借记忆和零零散散的笔记记录,尝试系统性地复习一下C语言。
之前都是在Windows环境下学习,这次把重心放在Linux环境下,这次的复习源于基础,但是要高于基础。
@[toc]
工具
Linux环境下一般都是通过gcc来编译C代码的。
gcc编译器
gcc(GNU Compiler Collection,GNU 编译器套件),是由 GNU 开发的编程语言编译器。gcc原本作为GNU操作系统的官方编译器,现已被大多数类Unix操作系统(如Linux、BSD、Mac OS X等)采纳为标准的编译器,gcc同样适用于微软的Windows。
gcc最初用于编译C语言,随着项目的发展gcc已经成为了能够编译C、C++、Java、Ada、fortran、Object C、Object C++、Go语言的编译器大家族。
编译命令格式:
gcc [-option1] ... <filename>
g++ [-option1] ... <filename>
- 命令、选项和源文件之间使用空格分隔
- 一行命令中可以有零个、一个或多个选项
- 文件名可以包含文件的绝对路径,也可以使用相对路径
- 如果命令中不包含输出可执行文件的文件名,可执行文件的文件名会自动生成一个默认名,Linux平台为a.out,Windows平台为a.exe
gcc、g++编译常用选项说明:
| 选项 | 含义 |
|---|---|
| -o file | 指定生成的输出文件名为file |
| -E | 只进行预处理 |
| -S(大写) | 只进行预处理和编译 |
| -c(小写) | 只进行预处理、编译和汇编 |
C语言是不跨平台的,用Java用习惯的我突然回到C,有点不适应,用SpringBoot完成的Java项目,打成jar包,只要安装了Java的环境,哪个地方都能跑。
对于C来说Linux编译后的可执行程序只能在Linux运行,Windows编译后的程序只能在Windows下运行。64位的Linux编译后的程序只能在64位Linux下运行,32位Linux编译后的程序只能在32位的Linux运行。
VS2019
这个是Windows环境下的工具。
用的是社区版,只装了C++的功能,快捷键用起来比较舒服,反编译还方便,学习了Java才知道有语法糖这个东西(Java的编译器帮我们做了很多的东西),这次重拾C/C++的时候,一定要摸清楚它们的编译器编译的时候做了哪些我们看不到,但是对我们来说很重要的事情
大二上学了一点汇编基础,要是有能力的话,后面看汇编也未尝不可。
C语言编译过程
C程序编译步骤
C代码编译成可执行程序经过4步:
1)预处理:宏定义展开、头文件展开、条件编译等,同时将代码中的注释删除,这里并不会检查语法
2)编译:检查语法,将预处理后文件编译生成汇编文件
3)汇编:将汇编文件生成目标文件(二进制文件)
4)链接:C语言写的程序是需要依赖各种库的,所以编译之后还需要把库链接到最终的可执行程序中去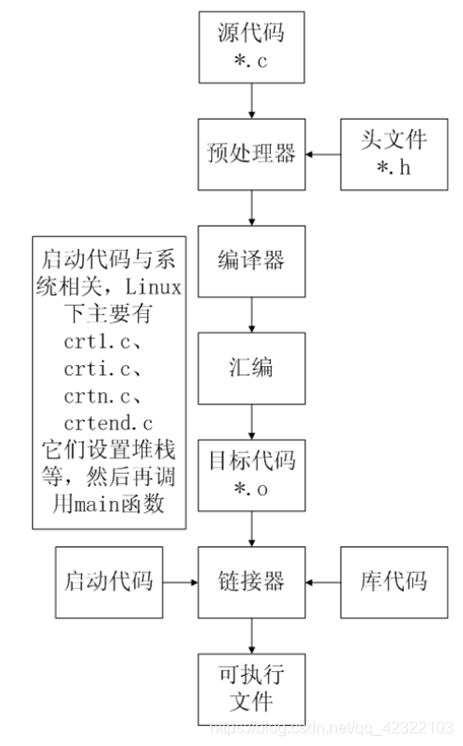
这里用gcc展示一下编译过程
vim hello.c
分步编译
预处理:gcc -E hello.c -o hello.i
编 译:gcc -S hello.i -o hello.s
汇 编:gcc -c hello.s -o hello.o
链 接:gcc hello.o -o hello_elf
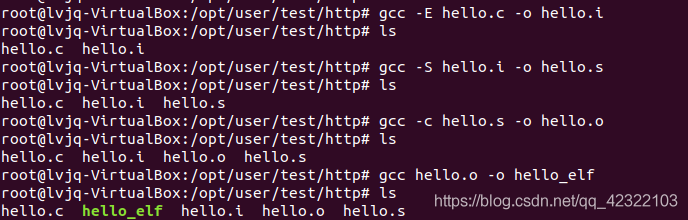
执行:
可以查看一下程序所依赖的动态库
.so结尾的都是库
libc是c的代码库,linux-gnu是Linux的标准协议,libc.so.6满足这个标准
下面的那个是Linux的平台库
| 选项 | 含义 |
|---|---|
| -E | 只进行预处理 |
| -S (大写) | 只进行预处理和编译 |
| -c (小写) | 只进行预处理、编译和汇编 |
| -o file | 指定生成的输出文件名为file |
| 文件后缀 | 含义 |
|---|---|
| .c | C语言文件 |
| .i | 预处理后的C语言文件 |
| .s | 编译后的汇编文件 |
| .o | 编译后的目标文件 |
注意这里没有贴分步编译后的文件的内容,但是里面的内容很有价值一定要看一看。一定要联系前面C代码编译成可执行程序经过4步的文字描述
一步编译的情况也演示一下吧:
关于执行:
我们的程序文件存在于外存储器,要读到内存中进行执行,这个时候就涉及缓存和寄存器,CPU相关的东西了。计算机组成原理(或者说计算机系统)方面的知识就不多赘述,不然篇幅太长了。
C语言代码主体
必要内容
include头文件
#include< > 与 #include ""的区别:
- < > 表示系统直接按系统指定的目录检索
- “” 表示系统先在 “” 指定的路径(没写路径代表当前路径)查找头文件,如果找不到,再按系统指定的目录检索
main函数
- 一个完整的C语言程序,是由一个、且只能有一个main()函数(又称主函数,必须有)和若干个其他函数结合而成(可选)。
- main函数是C语言程序的入口,程序是从main函数开始执行。
{} 括号,程序体和代码块
- {}叫代码块,一个代码块内部可以有一条或者多条语句
- C语言每句可执行代码都是";"分号结尾
- 所有的#开头的行,都代表预编译指令,预编译指令行结尾是没有分号的
- 所有的可执行语句必须是在代码块里面
注释
- //叫行注释,注释的内容编译器是忽略的,注释主要的作用是在代码中加一些说明和解释,这样有利于代码的阅读
- /* */叫块注释
- 块注释是C语言标准的注释方法
- 行注释是从C++语言借鉴过来的
return语句
- return代表函数执行完毕,返回return代表函数的终止
- 如果main定义的时候前面是int,那么return后面就需要写一个整数;如果main定义的时候前面是void,那么return后面什么也不需要写
- 在main函数中return 0代表程序执行成功,return -1代表程序执行失败
- int main()和void main()在C语言中是一样的,但C++只接受int main这种定义方式
C语言数据类型
关键字
C语言有32个关键字:
数据类型关键字
| 分类 | 名称 | 描述 |
|---|---|---|
| 基本数据类型 (5个) | void | 声明函数无返回值或无参数,声明无类型指针,显式丢弃运算结果。 |
| . | char | |
| . | int | 整型数据,通常为编译器指定的机器字长。 |
| . | float | 单精度浮点型数据,属于浮点数据的一种,小数点后保存6位。 |
| . | double | 双精度浮点型数据,属于浮点数据的一种,比float保存的精度高,小数点后保存15/16位。 |
| 类型修饰关键字(4个) | short | 修饰int,短整型数据,可省略被修饰的int。 |
| . | long | 修饰int,长整形数据,可省略被修饰的int。 |
| . | signed | 修饰整型数据,有符号数据类型。 |
| . | unsigned | 修饰整型数据,无符号数据类型。 |
| 复杂类型关键字(5个) | struct | 结构体声明 |
| . | union | 共用体声明 |
| . | enum | 枚举声明 |
| . | typedef | 声明类型别名 |
| . | sizeof | 得到特定类型或特定类型变量的大小。 |
| 存储级别关键字(6个) | auto | 指定为自动变量,由编译器自动分配及释放。通常在栈上分配。 |
| . | static | 指定为静态变量,分配在静态变量区,修饰函数时,指定函数作用域为文件内部。 |
| . | register | 指定为寄存器变量,建议编译器将变量存储到寄存器中使用,也可以修饰函数形参,建议编译器通过寄存器而不是堆栈传递参数。 |
| . | extern | 指定对应变量为外部变量,即在另外的目标文件中定义,可以认为是约定由另外文件声明的。 |
| . | const | 与volatile合称“cv特性”,指定变量不可被当前线程/进程改变(但有可能被系统或其他线程/进程改变) |
| . | volatile | 与const合称“cv特性”,指定变量的值有可能会被系统或其他进程/线程改变,强制编译器每次从内存中取得该变量的值 |
| 跳转结构(4个) | return | 用在函数体中,返回特定值(或者是void值,即不返回值) |
| . | continue | 结束当前循环,开始下一轮循环 |
| . | break | 跳出当前循环或switch结构 |
| . | goto | 无条件跳转语句。 |
| 分支结构(5个) | if | 条件语句 |
| . | else | 条件语句否定分支(与if连用) |
| . | switch | 开关语句(多重分支语句) |
| . | case | 开关语句中的分支标记 |
| . | default | |
| 循环结构(3个)for | for循环结构 | |
| . | do | do循环结构 |
| . | while |
数据类型的作用:编译器预算对象(变量)分配的内存空间大小。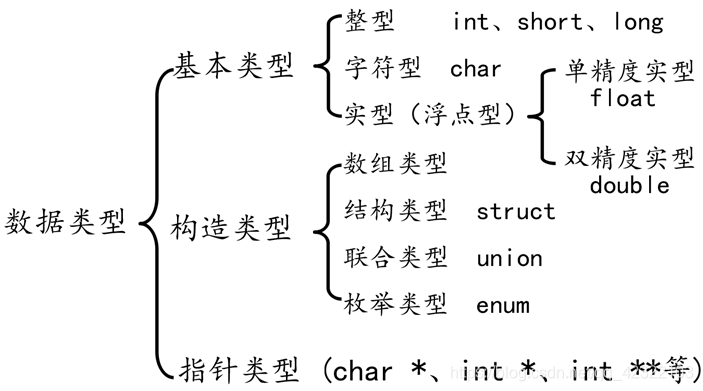
常量
常量:
- 在程序运行过程中,其值不能被改变的量
- 常量一般出现在表达式或赋值语句中
整型常量 100,200,-100,0
实型常量 3.14 , 0.125,-3.123
字符型常量 ‘a’,‘b’,‘1’,‘\n’
字符串常量 “a”,“ab”,“12356”
变量
变量:
- 在程序运行过程中,其值可以改变
- 变量在使用前必须先定义,定义变量前必须有相应的数据类型
标识符命名规则:
- 标识符不能是关键字
- 标识符只能由字母、数字、下划线组成
- 第一个字符必须为字母或下划线
- 标识符中字母区分大小写
变量特点:
- 变量在编译时为其分配相应的内存空间
- 可以通过其名字和地址访问相应内存
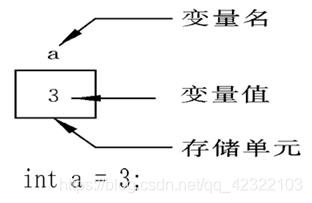
声明和定义区别
- 声明变量不需要建立存储空间,如:extern int a;
- 定义变量需要建立存储空间,如:int b;
#include <stdio.h>
int main()
{
//extern 关键字只做声明,不能做任何定义
//声明一个变量a,a在这里没有建立存储空间
extern int a;
a = 10; //err, 没有空间,就不可以赋值
int b = 10; //定义一个变量b,b的类型为int,b赋值为10
return 0;
}
从广义的角度来讲声明中包含着定义,即定义是声明的一个特例,所以并非所有的声明都是定义:
- int b 它既是声明,同时又是定义
- 对于 extern b来讲它只是声明不是定义
一般的情况下,把建立存储空间的声明称之为“定义”,而把不需要建立存储空间的声明称之为“声明”。
进制表示
C语言表示相应进制数:
| 进制 | 描述 |
|---|---|
| 十进制 | 以正常数字1-9开头,如123 |
| 八进制 | 以数字0开头,如0123 |
| 十六进制 | 以0x开头,如0x123 |
| 二进制 | C语言不能直接书写二进制数 |
sizeof 关键字
sizeof不是函数,所以不需要包含任何头文件,它的功能是计算一个数据类型的大小,单位为字节
sizeof的返回值为size_t
size_t类型在32位操作系统下是unsigned int,是一个无符号的整数
int main()
{
int a;
int b = sizeof(a);//sizeof得到指定值占用内存的大小,单位:字节
printf("b = %d\n", b);
size_t c = sizeof(a);
printf("c = %u\n", c);//用无符号数的方式输出c的值
return 0;
}
整型:int
整型变量的定义和输出
| 打印格式 | 含义 |
|---|---|
| %d | 输出一个有符号的10进制int类型 |
| %o(字母o) | 输出8进制的int类型 |
| %x | 输出16进制的int类型,字母以小写输出 |
| %X | 输出16进制的int类型,字母以大写写输出 |
| %u | 输出一个10进制的无符号数 |
整型变量的输入
#include <stdio.h>
int main()
{
int a;
printf("请输入a的值:");
//不要加“\n”
scanf("%d", &a);
printf("a = %d\n", a); //打印a的值
return 0;
}
short、int、long、long long
| 数据类型 | 占用空间 |
|---|---|
| short(短整型) | 2字节 |
| int(整型) | 4字节 |
| long(长整形) | Windows为4字节,Linux为4字节(32位),8字节(64位) |
| long long(长长整型) | 8字节 |
注意:
- 需要注意的是,整型数据在内存中占的字节数与所选择的操作系统有关。虽然 C 语言标准中没有明确规定整型数据的长度,但 long 类型整数的长度不能短于 int 类型, short 类型整数的长度不能长于 int 类型。
- 当一个小的数据类型赋值给一个大的数据类型,不会出错,因为编译器会自动转化。但当一个大的类型赋值给一个小的数据类型,那么就可能丢失高位。
| 整型常量 | 所需类型 |
|---|---|
| 10 | 代表int类型 |
| 10l, 10L | 代表long类型 |
| 10ll, 10LL | 代表long long类型 |
| 10u, 10U | 代表unsigned int类型 |
| 10ul, 10UL | 代表unsigned long类型 |
| 10ull, 10ULL | 代表unsigned long long类型 |
| 打印格式 | 含义 |
|---|---|
| %hd | 输出short类型 |
| %d | 输出int类型 |
| %l | 输出long类型 |
| %ll | 输出long long类型 |
| %hu | 输出unsigned short类型 |
| %u | 输出unsigned int类型 |
| %lu | 输出unsigned long类型 |
| %llu | 输出unsigned long long类型 |
有符号数和无符号数
有符号数
有符号数是最高位为符号位,0代表正数,1代表负数。
无符号数
无符号数最高位不是符号位,而就是数的一部分,无符号数不可能是负数。
当我们写程序要处理一个不可能出现负值的时候,一般用无符号数,这样可以增大数的表达最大值。
有符号和无符号整型取值范围
| 数据类型 | 占用空间 | 取值范围 |
|---|---|---|
| short | 2字节 | -32768 到 32767 |
| int | 4字节 | -2147483648 到 2147483647 |
| long | 4字节 | -2147483648 到 2147483647 |
| unsigned short | 2字节 | 0 到 65535 |
| unsigned int | 4字节 | 0 到 4294967295 |
| unsigned long | 4字节 | 0 到 4294967295 |
字符型:char
字符型变量用于存储一个单一字符,在 C 语言中用 char 表示,其中每个字符变量都会占用 1 个字节。在给字符型变量赋值时,需要用一对英文半角格式的单引号(’ ')把字符括起来。
字符变量实际上并不是把该字符本身放到变量的内存单元中去,而是将该字符对应的 ASCII 编码放到变量的存储单元中。char的本质就是一个1字节大小的整型。
#include <stdio.h>
int main()
{
char ch = 'a';
printf("sizeof(ch) = %u\n", sizeof(ch));
printf("ch[%%c] = %c\n", ch); //打印字符
printf("ch[%%d] = %d\n", ch); //打印‘a’ ASCII的值
char A = 'A';
char a = 'a';
printf("a = %d\n", a); //97
printf("A = %d\n", A); //65
printf("A = %c\n", 'a' - 32); //小写a转大写A
printf("a = %c\n", 'A' + 32); //大写A转小写a
ch = ' ';
printf("空字符:%d\n", ch); //空字符ASCII的值为32
printf("A = %c\n", 'a' - ' '); //小写a转大写A
printf("a = %c\n", 'A' + ' '); //大写A转小写a
return 0;
}
ASCII表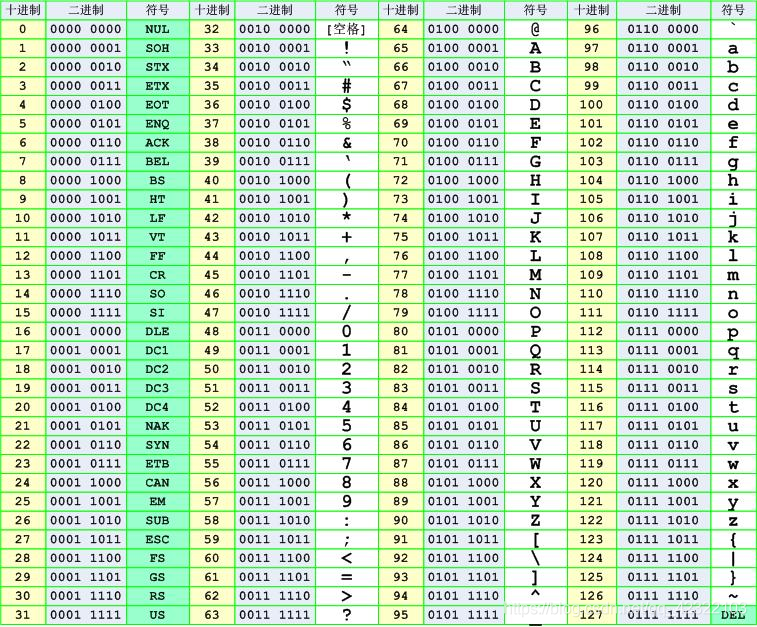
ASCII 码大致由以下两部分组成:
- ASCII 非打印控制字符: ASCII 表上的数字 0-31 分配给了控制字符,用于控制像打印机等一些外围设备。
- ASCII 打印字符:数字 32-126 分配给了能在键盘上找到的字符,当查看或打印文档时就会出现。数字 127 代表 Del 命令。
转义字符
| 转义字符 | 含义 | ASCII码值(十进制) |
|---|---|---|
| \a | 警报 | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \ | 代表一个反斜线字符"" | 092 |
| ’ | 代表一个单引号(撇号)字符 | 039 |
| " | 代表一个双引号字符 | 034 |
| ? | 代表一个问号 | 063 |
| \0 | 数字0 | 000 |
| \ddd | 8进制转义字符,d范围0~7 | 3位8进制 |
| \xhh | 16进制转义字符,h范围0~9,a~f,A~F | 3位16进制 |
数值溢出
当超过一个数据类型能够存放最大的范围时,数值会溢出。
有符号位最高位溢出的区别:符号位溢出会导致数的正负发生改变,但最高位的溢出会导致最高位丢失。
| 数据类型 | 占用空间 | 取值范围 |
|---|---|---|
| Char | 1字节 | -128到 127 |
| unsigned char | 1字节 | 0 到 255 |
#include <stdio.h>
int main()
{
char ch;
//符号位溢出会导致数的正负发生改变
ch = 0x7f + 2; //127+2
printf("%d\n", ch);
// 0111 1111
//+2后 1000 0001,这是负数补码,其原码为 1111 1111,结果为-127
//最高位的溢出会导致最高位丢失
unsigned char ch2;
ch2 = 0xff+1; //255+1
printf("%u\n", ch2);
// 1111 1111
//+1后 10000 0000, char只有8位最高位的溢出,结果为0000 0000,十进制为0
ch2 = 0xff + 2; //255+1
printf("%u\n", ch2);
// 1111 1111
//+1后 10000 0001, char只有8位最高位的溢出,结果为0000 0001,十进制为1
return 0;
}
实型(浮点型):float、double
实型变量也可以称为浮点型变量,浮点型变量是用来存储小数数值的。在C语言中, 浮点型变量分为两种: 单精度浮点数(float)、 双精度浮点数(double), 但是double型变量所表示的浮点数比 float 型变量更精确。
| 数据类型 | 占用空间 | 有效数字范围 |
|---|---|---|
| float | 4字节 | 7位有效数字 |
| double | 8字节 | 15~16位有效数字 |
由于浮点型变量是由有限的存储单元组成的,因此只能提供有限的有效数字。在有效位以外的数字将被舍去,这样可能会产生一些误差。
不以f结尾的常量是double类型,以f结尾的常量(如3.14f)是float类型。
这点很重要哈,我都忘了。
类型限定符
| 限定符 | 含义 |
|---|---|
| extern | 声明一个变量,extern声明的变量没有建立存储空间。extern int a; |
| const | 定义一个常量,常量的值不能修改。const int a = 10; |
| volatile | 防止编译器优化代码 |
| register | 定义寄存器变量,提高效率。register是建议型的指令,而不是命令型的指令,如果CPU有空闲寄存器,那么register就生效,如果没有空闲寄存器,那么register无效。 |
字符串常量
字符串是内存中一段连续的char空间,以’\0’(数字0)结尾。
字符串常量是由双引号括起来的字符序列,如“china”、“C program”,“$12.5”等都是合法的字符串常量。
字符串常量与字符常量的不同:
每个字符串的结尾,编译器会自动的添加一个结束标志位’\0’,即 “a” 包含两个字符’a’和’\0’。
C语言常见函数
system函数
system函数的使用
#include <stdlib.h>
int system(const char *command);
功能:在已经运行的程序中执行另外一个外部程序
参数:外部可执行程序名字
返回值:
成功:不同系统返回值不一样
失败:通常是 - 1
演示:
#include <stdio.h>
#include <stdlib.h>
int main()
{
//system("calc"); //windows平台
system("ls"); //Linux平台, 需要头文件#include <stdlib.h>
return 0;
}
system返回值不同系统结果不一样
C语言所有的库函数调用,只能保证语法是一致的,但不能保证执行结果是一致的,同样的库函数在不同的操作系统下执行结果可能是一样的,也可能是不一样的。
Linux的发展离不开POSIX标准,只要符合这个标准的函数,在不同的系统下执行的结果就可以一致。
Unix和linux很多库函数都是支持POSIX的,但Windows支持的比较差。
如果将Unix代码移植到Linux一般代价很小,如果把Windows代码移植到Unix或者Linux就比较麻烦。
printf函数和putchar函数
printf是输出一个字符串,putchar输出一个char。
printf格式字符:
| 打印格式 | 对应数据类型 | 含义 |
|---|---|---|
| %d | int | 接受整数值并将它表示为有符号的十进制整数 |
| %hd | short int | 短整数 |
| %hu | unsigned short | 无符号短整数 |
| %o | unsigned int | 无符号8进制整数 |
| %u | unsigned int | 无符号10进制整数 |
| %x,%X | unsigned int | 无符号16进制整数,x对应的是abcdef,X对应的是ABCDEF |
| %f | float | 单精度浮点数 |
| %lf | double | 双精度浮点数 |
| %e,%E | double | 科学计数法表示的数,此处"e"的大小写代表在输出时用的"e"的大小写 |
| %c | char 字符型。 | 可以把输入的数字按照ASCII码相应转换为对应的字符 |
| %s | char * | 字符串。输出字符串中的字符直至字符串中的空字符(字符串以’\0‘结尾,这个’\0’即空字符) |
| %p | void * | 以16进制形式输出指针 |
| %% | % | 输出一个百分号 |
printf附加格式:
| 字符 | 含义 |
|---|---|
| l(字母l) | 附加在d,u,x,o前面,表示长整数 |
| - | 左对齐 |
| m(代表一个整数) | 数据最小宽度 |
| 0(数字0) | 将输出的前面补上0直到占满指定列宽为止不可以搭配使用- |
| m.n(代表一个整数) | m指域宽,即对应的输出项在输出设备上所占的字符数。n指精度,用于说明输出的实型数的小数位数。对数值型的来说,未指定n时,隐含的精度为n=6位。 |
scanf函数与getchar函数
getchar是从标准输入设备读取一个char。
scanf通过%转义的方式可以得到用户通过标准输入设备输入的数据。
随机数相关
当调用函数时,需要关心5要素:
- 头文件:包含指定的头文件
- 函数名字:函数名字必须和头文件声明的名字一样
- 功能:需要知道此函数能干嘛后才调用
- 参数:参数类型要匹配
- 返回值:根据需要接收返回值
#include <time.h>
time_t time(time_t *t);
功能:获取当前系统时间
参数:常设置为NULL
返回值:当前系统时间, time_t 相当于long类型,单位为毫秒
#include <stdlib.h>
void srand(unsigned int seed);
功能:用来设置rand()产生随机数时的随机种子
参数:如果每次seed相等,rand()产生随机数相等
返回值:无
#include <stdlib.h>
int rand(void);
功能:返回一个随机数值
参数:无
返回值:随机数
这里贴一个demo
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
int main()
{
time_t tm = time(NULL);//得到系统时间
srand((unsigned int)tm);//随机种子只需要设置一次即可
int r = rand();
printf("r = %d\n", r);
return 0;
}
字符串处理函数
gets()
#include <stdio.h>
char *gets(char *s);
功能:从标准输入读入字符,并保存到s指定的内存空间,直到出现换行符或读到文件结尾为止。
参数:
s:字符串首地址
返回值:
成功:读入的字符串
失败:NULL
gets(str)与scanf(“%s”,str)的区别:
- gets(str)允许输入的字符串含有空格
- scanf(“%s”,str)不允许含有空格
注意:由于scanf()和gets()无法知道字符串s大小,必须遇到换行符或读到文件结尾为止才接收输入,因此容易导致字符数组越界(缓冲区溢出)的情况。
fgets()
#include <stdio.h>
char *fgets(char *s, int size, FILE *stream);
功能:从stream指定的文件内读入字符,保存到s所指定的内存空间,直到出现换行字符、读到文件结尾或是已读了size - 1个字符为止,最后会自动加上字符 '\0' 作为字符串结束。
参数:
s:字符串
size:指定最大读取字符串的长度(size - 1)
stream:文件指针,如果读键盘输入的字符串,固定写为stdin
返回值:
成功:成功读取的字符串
读到文件尾或出错: NULL
fgets()在读取一个用户通过键盘输入的字符串的时候,同时把用户输入的回车也做为字符串的一部分。通过scanf和gets输入一个字符串的时候,不包含结尾的“\n”,但通过fgets结尾多了“\n”。fgets()函数是安全的,不存在缓冲区溢出的问题。
puts()
#include <stdio.h>
int puts(const char *s);
功能:标准设备输出s字符串,在输出完成后自动输出一个'\n'。
参数:
s:字符串首地址
返回值:
成功:非负数
失败:-1
fputs()
#include <stdio.h>
int fputs(const char * str, FILE * stream);
功能:将str所指定的字符串写入到stream指定的文件中, 字符串结束符 '\0' 不写入文件。
参数:
str:字符串
stream:文件指针,如果把字符串输出到屏幕,固定写为stdout
返回值:
成功:0
失败:-1
fputs()是puts()的文件操作版本,但fputs()不会自动输出一个’\n’。
strlen()
#include <string.h>
size_t strlen(const char *s);
功能:计算指定指定字符串s的长度,不包含字符串结束符‘\0’
参数:
s:字符串首地址
返回值:字符串s的长度,size_t为unsigned int类型
strcpy()
#include <string.h>
char *strcpy(char *dest, const char *src);
功能:把src所指向的字符串复制到dest所指向的空间中,'\0'也会拷贝过去
参数:
dest:目的字符串首地址
src:源字符首地址
返回值:
成功:返回dest字符串的首地址
失败:NULL
注意:如果参数dest所指的内存空间不够大,可能会造成缓冲溢出的错误情况。
strncpy()
#include <string.h>
char *strncpy(char *dest, const char *src, size_t n);
功能:把src指向字符串的前n个字符复制到dest所指向的空间中,是否拷贝结束符看指定的长度是否包含'\0'。
参数:
dest:目的字符串首地址
src:源字符首地址
n:指定需要拷贝字符串个数
返回值:
成功:返回dest字符串的首地址
失败:NULL
strcat()
#include <string.h>
char *strcat(char *dest, const char *src);
功能:将src字符串连接到dest的尾部,‘\0’也会追加过去
参数:
dest:目的字符串首地址
src:源字符首地址
返回值:
成功:返回dest字符串的首地址
失败:NULL
strncat()
#include <string.h>
char *strncat(char *dest, const char *src, size_t n);
功能:将src字符串前n个字符连接到dest的尾部,‘\0’也会追加过去
参数:
dest:目的字符串首地址
src:源字符首地址
n:指定需要追加字符串个数
返回值:
成功:返回dest字符串的首地址
失败:NULL
strcmp()
#include <string.h>
int strcmp(const char *s1, const char *s2);
功能:比较 s1 和 s2 的大小,比较的是字符ASCII码大小。
参数:
s1:字符串1首地址
s2:字符串2首地址
返回值:
相等:0
大于:>0
小于:<0
strncmp()
#include <string.h>
int strncmp(const char *s1, const char *s2, size_t n);
功能:比较 s1 和 s2 前n个字符的大小,比较的是字符ASCII码大小。
参数:
s1:字符串1首地址
s2:字符串2首地址
n:指定比较字符串的数量
返回值:
相等:0
大于: > 0
小于: < 0
sprintf()
#include <stdio.h>
int sprintf(char *_CRT_SECURE_NO_WARNINGS, const char *format, ...);
功能:根据参数format字符串来转换并格式化数据,然后将结果输出到str指定的空间中,直到出现字符串结束符 '\0' 为止。
参数:
str:字符串首地址
format:字符串格式,用法和printf()一样
返回值:
成功:实际格式化的字符个数
失败: - 1
sscanf()
#include <stdio.h>
int sscanf(const char *str, const char *format, ...);
功能:从str指定的字符串读取数据,并根据参数format字符串来转换并格式化数据。
参数:
str:指定的字符串首地址
format:字符串格式,用法和scanf()一样
返回值:
成功:参数数目,成功转换的值的个数
失败: - 1
strchr()
#include <string.h>
char *strchr(const char *s, int c);
功能:在字符串s中查找字母c出现的位置
参数:
s:字符串首地址
c:匹配字母(字符)
返回值:
成功:返回第一次出现的c地址
失败:NULL
strstr()
#include <string.h>
char *strstr(const char *haystack, const char *needle);
功能:在字符串haystack中查找字符串needle出现的位置
参数:
haystack:源字符串首地址
needle:匹配字符串首地址
返回值:
成功:返回第一次出现的needle地址
失败:NULL
strtok()
#include <string.h>
char *strtok(char *str, const char *delim);
功能:来将字符串分割成一个个片段。当strtok()在参数s的字符串中发现参数delim中包含的分割字符时, 则会将该字符改为\0 字符,当连续出现多个时只替换第一个为\0。
参数:
str:指向欲分割的字符串
delim:为分割字符串中包含的所有字符
返回值:
成功:分割后字符串首地址
失败:NULL
在第一次调用时:strtok()必需给予参数s字符串
往后的调用则将参数s设置成NULL,每次调用成功则返回指向被分割出片段的指针
char a[100] = "adc*fvcv*ebcy*hghbdfg*casdert";
char *s = strtok(a, "*");//将"*"分割的子串取出
while (s != NULL)
{
printf("%s\n", s);
s = strtok(NULL, "*");
}
atoi()
#include <stdlib.h>
int atoi(const char *nptr);
功能:atoi()会扫描nptr字符串,跳过前面的空格字符,直到遇到数字或正负号才开始做转换,而遇到非数字或字符串结束符('\0')才结束转换,并将结果返回返回值。
参数:
nptr:待转换的字符串
返回值:成功转换后整数
类似的函数有:
- atof():把一个小数形式的字符串转化为一个浮点数。
- atol():将一个字符串转化为long类型
char str1[] = "-10";
int num1 = atoi(str1);
printf("num1 = %d\n", num1);
char str2[] = "0.123";
double num2 = atof(str2);
printf("num2 = %lf\n", num2);
C语言运算符与表达式
常用运算符分类
| 运算符类型 | 作用 |
|---|---|
| 算术运算符 | 用于处理四则运算 |
| 赋值运算符 | 用于将表达式的值赋给变量 |
| 比较运算符 | 用于表达式的比较,并返回一个真值或假值 |
| 逻辑运算符 | 用于根据表达式的值返回真值或假值 |
| 位运算符 | 用于处理数据的位运算 |
| sizeof运算符 | 用于求字节数长度 |
算术运算符与赋值运算符,比较运算符以及逻辑运算符详细信息略
运算符优先级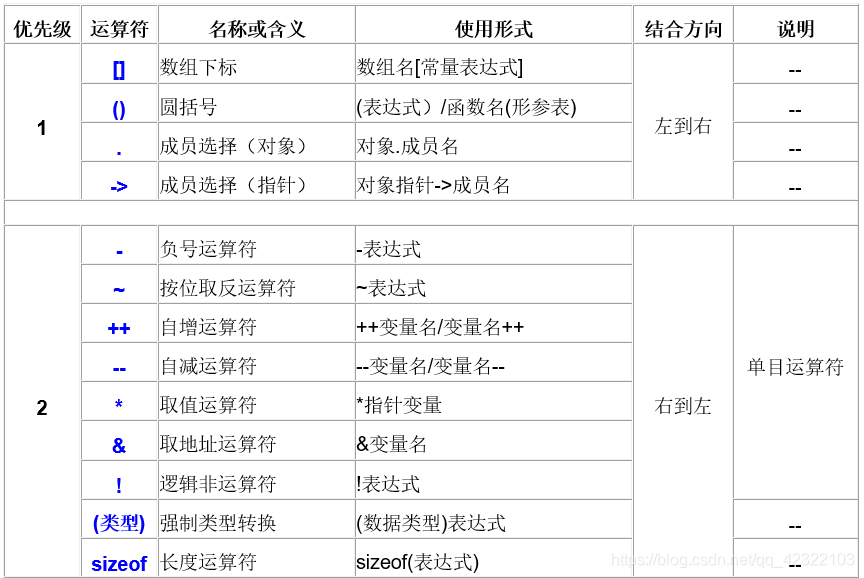
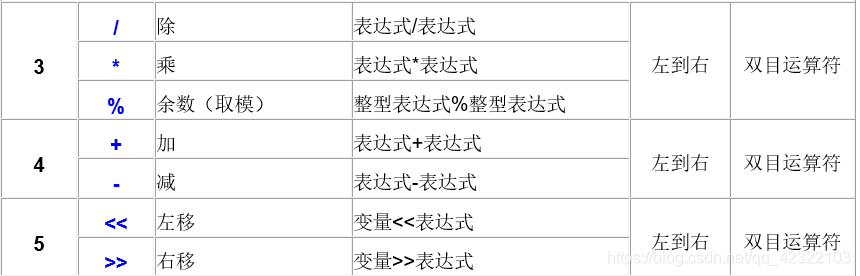
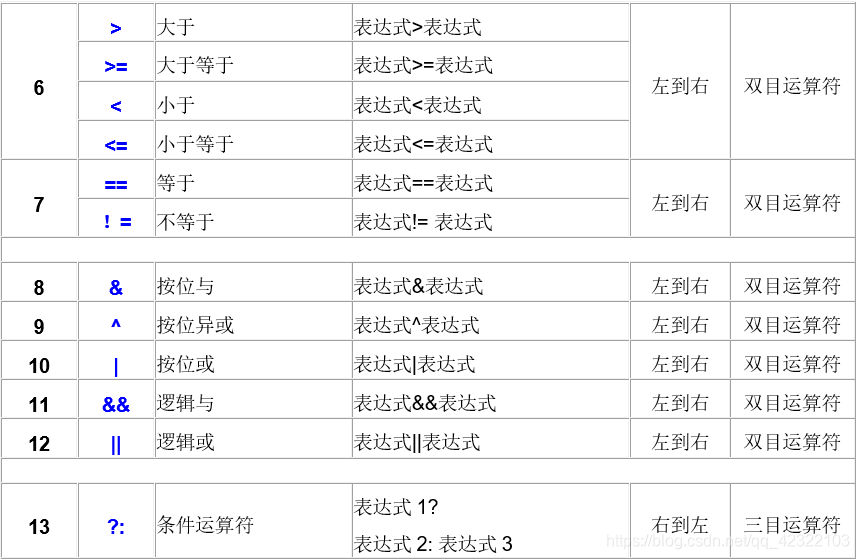

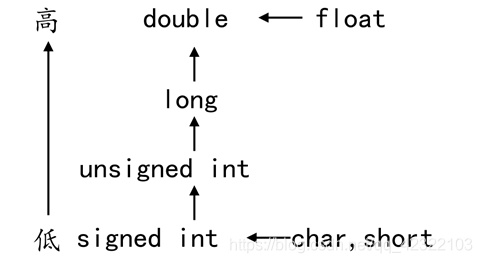
类型转换
数据有不同的类型,不同类型数据之间进行混合运算时必然涉及到类型的转换问题。
转换的方法有两种:
- 自动转换(隐式转换):遵循一定的规则,由编译系统自动完成。
- 强制类型转换:把表达式的运算结果强制转换成所需的数据类型。
类型转换的原则:占用内存字节数少(值域小)的类型,向占用内存字节数多(值域大)的类型转换,以保证精度不降低。
C语言的数组和字符串
数组相关
数组就是在内存中连续的相同类型的变量空间。 同一个数组所有的成员都是相同的数据类型,同时所有的成员在内存中的地址是连续的。
数组属于构造数据类型:
一个数组可以分解为多个数组元素:这些数组元素可以是基本数据类型或构造类型。
int a[10];
struct Stu boy[10];
按数组元素类型的不同,数组可分为:数值数组、字符数组、指针数组、结构数组等类别。
int a[10];
char s[10];
char *p[10];
通常情况下,数组元素下标的个数也称为维数,根据维数的不同,可将数组分为一维数组、二维数组、多维数组。
在定义数组的同时进行赋值,称为初始化。全局数组若不初始化,编译器将其初始化为零。局部数组若不初始化,内容为随机值。
数组名是一个地址的常量,代表数组中首元素的地址。
关于二维数组:
- 二维数组在概念上是二维的:其下标在两个方向上变化,对其访问一般需要两个下标。
- 在内存中并不存在二维数组,二维数组实际的硬件存储器是连续编址的,也就是说内存中只有一维数组,即放完一行之后顺次放入第二行,和一维数组存放方式是一样的。
字符数组与字符串
字符数组与字符串区别
- C语言中没有字符串这种数据类型,可以通过char的数组来替代;
- 字符串一定是一个char的数组,但char的数组未必是字符串;
- 数字0(和字符‘\0’等价)结尾的char数组就是一个字符串,但如果char数组没有以数字0结尾,那么就不是一个字符串,只是普通字符数组,所以字符串是一种特殊的char的数组。
C语言函数部分
从函数定义的角度看,函数可分为系统函数和用户定义函数两种:
- 系统函数,即库函数:这是由编译系统提供的,用户不必自己定义这些函数,可以直接使用它们,如我们常用的打印函数printf()。
- 用户定义函数:用以解决用户的专门需要。
如果使用用户自己定义的函数,而该函数与调用它的函数(即主调函数)不在同一文件中,或者函数定义的位置在主调函数之后,则必须在调用此函数之前对被调用的函数作声明。
所谓函数声明,就是在函数尚在未定义的情况下,事先将该函数的有关信息通知编译系统,相当于告诉编译器,函数在后面定义,以便使编译能正常进行。
注意:一个函数只能被定义一次,但可以声明多次。
函数定义和声明的区别:
1)定义是指对函数功能的确立,包括指定函数名、函数类型、形参及其类型、函数体等,它是一个完整的、独立的函数单位。
2)声明的作用则是把函数的名字、函数类型以及形参的个数、类型和顺序(注意,不包括函数体)通知编译系统,以便在对包含函数调用的语句进行编译时,据此对其进行对照检查(例如函数名是否正确,实参与形参的类型和个数是否一致)。
C语言的多文件编程
分文件编程
- 把函数声明放在头文件xxx.h中,在主函数中包含相应头文件
- 在头文件对应的xxx.c中实现xxx.h声明的函数

防止头文件重复包含
当一个项目比较大时,往往都是分文件,这时候有可能不小心把同一个头文件 include 多次,或者头文件嵌套包含。
为了避免同一个文件被include多次,C/C++中有两种方式,一种是 #ifndef 方式,一种是 #pragma once 方式。
方法一:
#ifndef __SOMEFILE_H__
#define __SOMEFILE_H__
// 声明语句
#endif
方法二:
#pragma once
// 声明语句
C语言的指针
C语言的内存管理
C语言的复合类型(自定义类型)
C语言的文件
共同学习,写下你的评论
评论加载中...
作者其他优质文章



