
词向量模型下载地址:http://nlp.stanford.edu/projects/glove/
数据集下载地址:http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/data/news20.html
完整代码:
详情参见注释
from __future__ import print_function
import os
import sys
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from keras.layers import Dense,Input,GlobalMaxPooling1D
from keras.layers import Conv1D,MaxPooling1D,Embedding
from keras.models import Model
from keras.initializers import Constant
BASE_DIR = './'
#glove模型路径
GLOVE_DIR = os.path.join(BASE_DIR,'glove.6B')
#文本语料路径
TEXT_DATA_DIR = os.path.join(BASE_DIR,'20_newsgroup')
max_sequence_length = 1000
max_words_num = 20000
embedding_dim = 100
validation_split = 0.2
#1.准备glove词向量和它们对应的字典映射
print('Indexing word vectors.')
embeddings_index = {}
with open(os.path.join(GLOVE_DIR,'glove.6B.100d.txt'),encoding = 'utf-8') as f:
for line in f:
word,coefs = line.split(maxsplit = 1)
#maxsplit = 1,只对第一个出现的空格进行分割
#对所有的情况都分割时,maxsplit = -1
coefs = np.fromstring(coefs,'f',sep = ' ')
#fromstring:将字符串按分隔符解码成矩阵
embeddings_index[word] = coefs
print('Found %s word vectors.' % len(embeddings_index))
"""
查看词向量
print('was')
print(embeddings_index['was'])
运行结果见figure1
"""
#2.准备训练文本和标签
print('Processing text dataset')
texts = []
labels = []
#dictionary mapping label name to numeric id
labels_index = {}
for name in sorted(os.listdir(TEXT_DATA_DIR)):
path = os.path.join(TEXT_DATA_DIR,name)
if os.path.isdir(path):
label_id = len(labels_index)
labels_index[name] = label_id
for fname in sorted(os.listdir(path)):
if fname.isdigit():
fpath = os.path.join(path,fname)
args = {} if sys.version_info < (3,) else {'encoding':'latin-1'}
#print('args:',args)
#args: {'encoding': 'latin-1'}
with open(fpath,**args) as f:
t = f.read()
i = t.find('\n\n') #skip header
if 0 < i:
t = t[i:]
texts.append(t)
labels.append(label_id)
#这个label_id的生成方式比较有意思
print('Found %s texts.' % len(texts))
#3.将文本向量化为 2D integer tensor
tokenizer = Tokenizer(num_words = max_words_num)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences,maxlen = max_sequence_length)
labels = to_categorical(np.asarray(labels))
print('Shape of data tensor:',data.shape)
print('Shape of label tensor:',labels.shape)
#4.分割训练集和验证集
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
num_validation_samples = int(validation_split * data.shape[0])
x_train = data[:-num_validation_samples]
y_train = labels[:-num_validation_samples]
x_val = data[-num_validation_samples:]
y_val = labels[-num_validation_samples:]
#5.生成词嵌入矩阵
print('Preparing embedding matrix.')
num_words = min(max_words_num,len(word_index) + 1)
embedding_matrix = np.zeros((num_words,embedding_dim))
for word,i in word_index.items():
if i >= max_words_num:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
#从预训练模型的词向量到语料库的词向量映射
embedding_matrix[i] = embedding_vector
#load pre-trained word embeddings into an Embedding layer
#note that we set trainable = False so as to keep the embeddings fixed
embedding_layer = Embedding(
num_words,
embedding_dim,
embeddings_initializer = Constant(embedding_matrix),
input_length = max_sequence_length,
trainable = False
)
print('Training model.')
#6.搭建CNN模型,开始训练
sequence_input = Input(shape = (max_sequence_length,),dtype = 'int32')
embedded_sequences = embedding_layer(sequence_input)
x = Conv1D(128,5,activation = 'relu')(embedded_sequences)
x = MaxPooling1D(5)(x)
x = Conv1D(128,5,activation = 'relu')(x)
x = MaxPooling1D(5)(x)
x = Conv1D(128,5,activation = 'relu')(x)
x = GlobalMaxPooling1D()(x)
x = Dense(128,activation = 'relu')(x)
preds = Dense(len(labels_index),activation = 'softmax')(x)
model = Model(sequence_input,preds)
model.compile(
loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['acc']
)
model.fit(
x_train,y_train,
batch_size = 128,
epochs = 5,
validation_data = (x_val,y_val)
)
词向量模型:
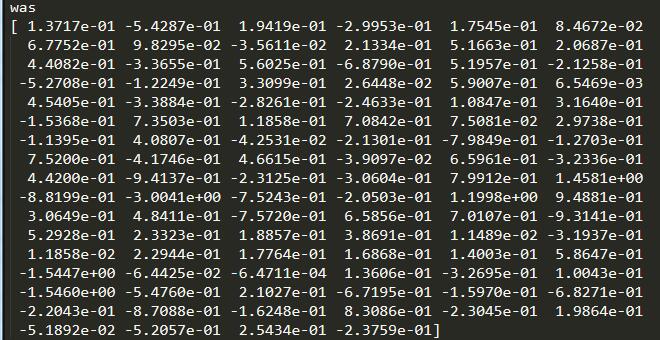
figure1
运行结果: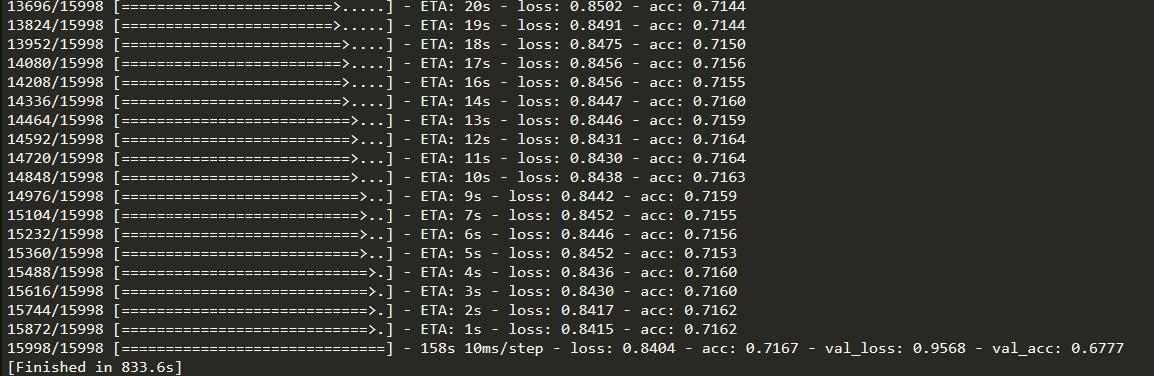
figure2
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦