
sed命令有两个空间,一个叫pattern space,一个叫hold space。这两个空间能够证明人类的脑瓜容量是非常小的,需要经过大量的训练和烧脑的理解,才能适应一些非常简单的操作。
不信看下面简单的命令,作用是,删除文件中最后两行。
sed 'N; $!P;$!D;$d' file
在《Linux生产环境上,最常用的一套“Sed“技巧》一文中,我们介绍了常用的sed命令和操作,而且使用了两张图来作为辅助。但可惜的是,这两张图,严格来说是不准确的 (比如s命令,只是其中的一个子集),即使它能够帮助初学者快速入门。
本篇属于sed的中级用法,常见在一些sed脚本中,在日常中应用并不多,但往往能够获得意想不到的效果。
原理
工作模式
这要从sed的工作模式来说起。
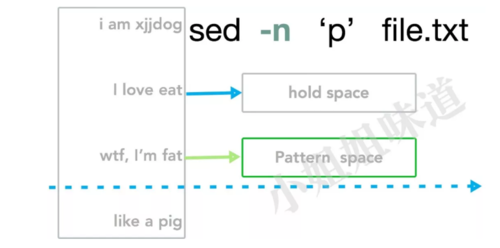
按照我们读取一个文件的尿性,一般是持续循环读取。比如下面的python代码,print代表p命令。
with open('file', 'r') as f:
for line in f.readlines():
print(line)sed命令在这之上,还缓冲了另外一个东西。那就是“上一行的内容” ,叫做hold space。而当前行,叫做patter space。用python简单表现一下:
hold_space = ""
with open('file', 'r') as f:
for pattern_space in f.readlines():
print(hold_space,pattern_space)
hold_space = pattern_space具体过程,大体与上面的代码类似,以上面的图为例。在这个例子中,hold space不参与运算,是全程无感的:
1、 读取当前行
wtf..到 Pattern space2、 执行命令
p,这会打印出当前行3、 把Pattern space的内容,赋值给Hold space
4、 继续下一行的处理,循环这个过程
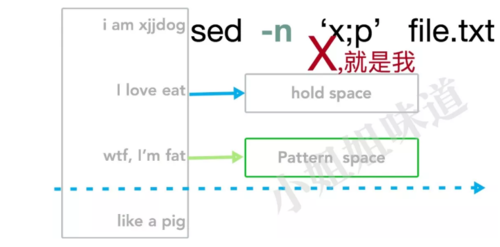
一个例子:x
但我想稍微操作一下这两个缓冲区。这个操作就是swap,使用x表示,这也是一些文本编辑器的一贯尿性。
也就是,在p之前,我们加上了个x。表示先将这两个缓冲区进行置换,然后再往下走。
hold_space = ""
with open('file', 'r') as f:
for pattern_space in f.readlines():
swap(hold_space,pattern_space)
print(hold_space,pattern_space)
hold_space = pattern_space让我我们来想象一下这个过程。
1、 刚开始,hold_space的内容是空。然鹅,还没被填充,它就被使用了,和当前行进行了置换
2、 p命令用在了置换后的缓冲区上,第一次打印出了空行,fuck
3、 继续嘟嘟嘟,现在到了最后一行,马上进行了置换,没机会打印就到了hold_space中了
4、 当前行,存放的是倒数第二行的数据,最后一行见光死,就永远没有机会面世了
我们当然有办法把它搞出来,比如,我执行偶数次的交换x。
sed -n 'x;x;x;x;p' file
有木有一股骑着羊驼走天下的的感觉?
应用
举个栗子
你可能会想,我对这两个缓冲区交换,有什么用?接下来看这个文件。
小姐姐味道公众号
CEO
加菲猫经理
IT Manager
系统毁灭师
Sysadmin
小哥哥味道
Developer
爱卖东西的经理
Sales Manager
风清扬
Dog文件奇数行是名称,偶数行是职位。我们想要输出所有Manager的名字。就可以使用下面的命令。
sed -n -e 'x;n' -e '/Manager/{x;p}' file命令分为两个部分。
x;n 表示将偶数行保存在pattern space,那么奇数行就保存在hold space中。
/Manager/{x;p} 命令将在pattern space上执行对Manager关键字的查找。如果符合条件,则再次交换p和h缓冲区,输出奇数行对应的名字。
上面的x和n,就是针对这两个缓冲区的命令。这样的命令有很多。
命令
这些命令,如果多了,可以使用{}包围起来,就像上面的命令一样。这些命令的位置与我们上一篇所说的,在同一个地方。
常用的:
x 请容许我用英文装个b:Exchange the contents of the hold and pattern spaces.
d 清空当前的pattern space,然后进入下一个循环
D 删除pattern space的第一行(multiline pattern)
h 复制pattern space到hold space
H 追加pattern spaced到hold space
g 复制hold space到pattern space
G 追加hold space到pattern space
n 读取下一个输入行到pattern space
N 追加下一个输入行到pattern space,同时将两行看做一行,但是两行之间依然含有\n换行符
p 打印当前的pattern space
P 打印当前的pattern space中的第一行
不常用的
上次提到的推箱子游戏,就用了很多这种东西。为了使使用者在书写sed脚本的时候真正的”自由”,sed还允许在脚本中用”:”设置记号。标签,有种类似编程语言的特性了。
q 退出sed,可以增加执行速度
l 列出当前行,包含不可打印字符
l width 列出当前行,使用一个
width characters结尾b label 跳到相应的标签,分之命令。
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。测试命令。
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
当然还有其他更不常用的,可以使用man命令查看
man sed
一些命令:开启训练模式
看着一行行进行处理,好像很简单是不是?不可能的,看下面几个简单的命令,训练一下生锈的脑子。
一个流水线一样的命令
sed -n '2{h;n;x;H;x};p' file交换第2行和第3行的内容
输出最后一行
sed 'N;D' file
输出文件中最后两行
sed '$!N; $!D' file
删除文件中最后两行
sed 'N; $!P;$!D;$d' file
打印偶数行的另一种写法
sed –n 'n;p' file
每隔5行加入一个空行。
sed 'n;n;n;n;G' file
输出含AAA和BBB和CCC(任意顺序)的段落
sed -e '/./{H; $!d;}' -e 'x;/AAA/!d; /BBB/!d; /CCC/!d' file颠倒行序(使末行变首行,首行变末行)
sed -n '1!G; h; $p' file
这个命令有点绕,首先,
1!G对除了第一行的其他行进行了G操作,然后反向复制回去,到了最后一行,就直接打印Pattern Space。$表示到了最后一行执行下面的命令,也可以是${p}
一个带标签的用法
sed -e :a -e '$q;N;11,$D;ba'
打印最后10行。a是标签。语法就是单独的行,使用:分隔。
End
为了提高你在公司的竞争力,你是可以弄一堆sed脚本唬人(埋雷)的。和某些perl脚本一样,即使是有相关经验的开发着,理解起来也要下点功夫,就不要说其他人了。
这就是sed,简约但不简单的命令,本文算是一个中级入门。中级入门也有点烧脑,因为你的脑瓜里,需要一直维护着这两个缓冲区。又是置换,又是清空,相当于人肉状态机。当然,怎么把这个过程讲的尽量简单一点,还是浪费了作者不少脑细胞的。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



