
恕我直言,牛逼哄哄的MongoDB你可能只会30%
MongoDB闪亮登场
自我介绍
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
MongoDB最大的特点就是无Schema限制,灵活度很高。数据格式是BSON,BSON是一种类似JSON的二进制形式的存储格式,简称Binary JSON 它和JSON一样,支持内嵌的文档对象和数组对象。
跟关系型数据库概念对比
| Mysql | MongoDB |
|---|---|
| Database(数据库) | Database(数据库) |
| Table(表) | Collection(集合) |
| Row(行) | Document(文档) |
| Column(列) | Field(字段) |
数据格式
MongoDB 将数据存储为一个文档,BSON格式。由key 和 value组成。
{
"_id" : ObjectId("5e141148473cce6a9ef349c7"),
"title" : "批量更新",
"url" : "http://cxytiandi.com/blog/detail/8",
"author" : "yinjihuan",
"tags" : [
"java",
"mongodb",
"spring"
],
"visit_count" : NumberLong(10),
"add_time" : ISODate("2019-02-11T07:10:32.936+0000")
}
使用场景
- 大数据量存储场景
MongoDB自带副本集和分片,天生就适用于大数量场景,无需开发人员通过中间件去分库分表,非常方便。
- 操作日志存储
很多时候,我们需要存储一些操作日志,可能只需要存储比如最近一个月的,一般的做法是定期去清理,在MongoDB中有固定集合的概念,我们在创建集合的时候可以指定大小,当数据量超过大小的时候会自动移除掉老数据。
- 爬虫数据存储
爬下来的数据有网页,也有Json格式的数据,一般都会按照表的格式去存储,如果我们用了MongoDB就可以将抓下来的Json数据直接存入集合中,无格式限制。
- 社交数据存储
在社交场景中使用 MongoDB 存储存储用户地址位置信息,通过地理位置索引实现附近的人,附近的地点等。
- 电商商品存储
不同的商品有不同的属性,常见的做法是抽出公共的属性表,然后和SPU进行关联,如果用MongoDB的话那么SPU中直接就可以内嵌属性。
自我陶醉
MongoDB的功能点很多,但是大部分场景下我们只用了最简单的CRUD操作。下面隆重的介绍下MongoDB的功能点,就像你去相亲一样,不好好介绍自己的优点又怎能让你对面的菇凉心动呢?
CRUD
CRUD也就是增删改查,这是数据库最基本的功能,查询还支持全文检索,GEO地理位置查询等。
- db.collection.insertOne()
单个文档插入到集合中
- db.collection.insertMany()
多个文档插入到集合中
- db.collection.insert()
单个或者多个文件插入到集合中
- db.collection.find( )
查询数据
- db.inventory.updateOne()
更新单条
- db.inventory.updateMany()
更新多条
- db.inventory.deleteOne( )
删除单条文档
- db.inventory.deleteMany()
删除多条文档
Aggregation
聚合操作用于数据统计方面,比如Mysql中会有count,sum,group by等功能,在MongoDB中相对应的就是Aggregation聚合操作。
聚合下面有两种方式来实现我们需要对数据进行统计的需求,一个是aggregate,一个是MapReduce。
下图展示了aggregate的执行原理:
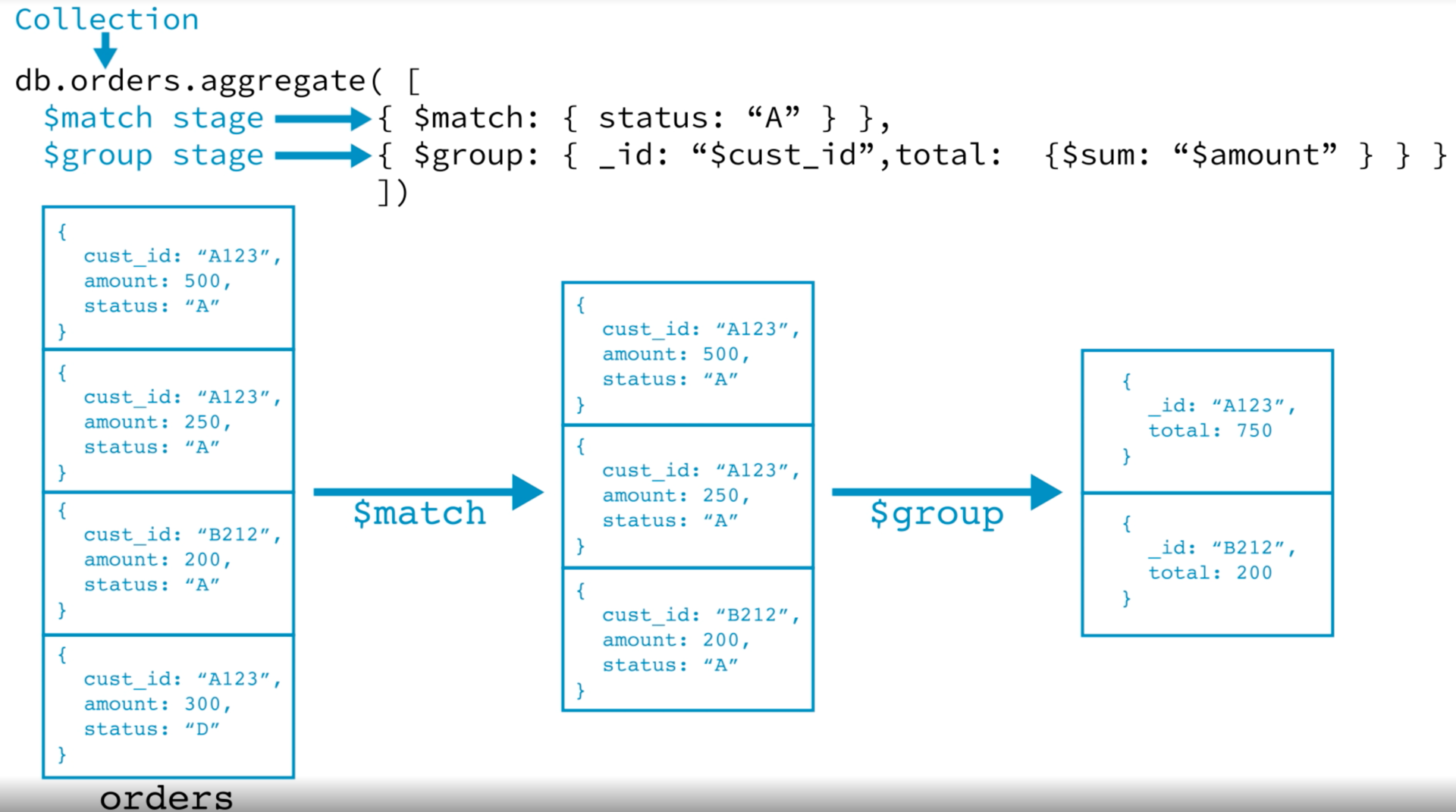
聚合内置了很多函数,使用好了这些函数我们就可以统计出我们想要的数据。
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
KaTeX parse error: Expected 'EOF', got ':' at position 6: match:̲用于过滤数据,只输出符合条件的…match使用MongoDB的标准查询操作。
$limit:用来限制MongoDB聚合管道返回的文档数。
$skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
$group:将集合中的文档分组,可用于统计结果。
$sort:将输入文档排序后输出。
$geoNear:输出接近某一地理位置的有序文档。
$unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
下图展示了MapReduce的执行原理:
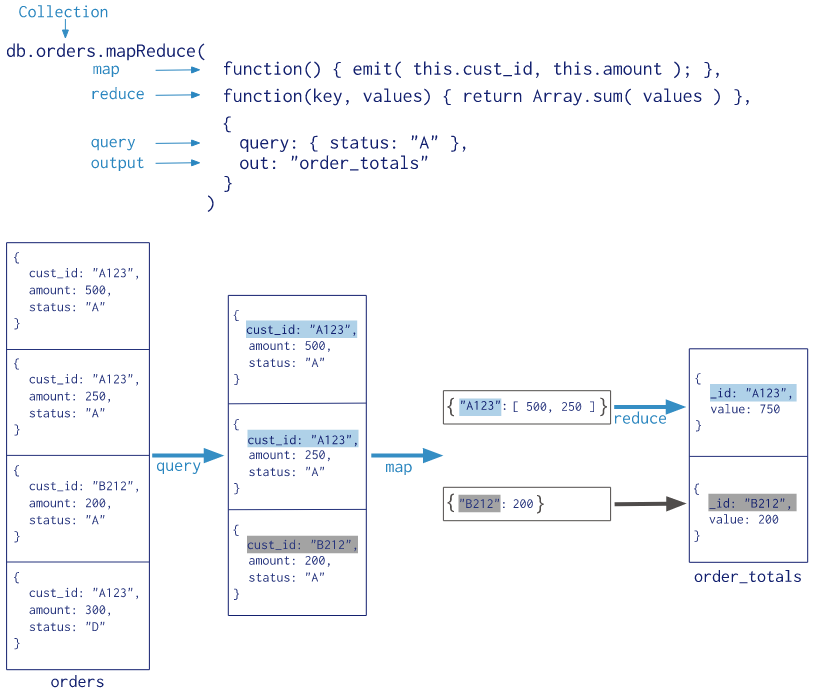
总共4条数据,query指定了查询条件,只处理status=A的数据。
map阶段对数据进行分组聚合,也就是形成了第三部分的效果,根据cust_id去重统计。
reduce中的key也就是cust_id, values也就是汇总的amount集合。然后进行sum操作,最终的结果通过out输出到一个集合中。
Transactions
MongoDB最开始是不支持事务的,在MongoDB中,对单个文档的操作是原子性操作。所以再设计的时候可以使用嵌入的文档和数组来描述数据之间的关系,这样就不用跨多个文档和集合进行操作,也就通过了单文档原子性消除了许多实际用例对多文档事务的需要。
任何事物都是有限制的,某些场景还是不能完全通过内嵌的方式来描述数据的关系,还是会存在多个集合,对于使用MongoDB的用户来说,如果能支持事务就很方便了。
不负众望,MongoDB 4.0 版本的发布,为我们带来了原生的事务操作。
Indexes
索引不用我多说了,作用大家都知道。单索引,组合索引,全文索引,Hash索引等。
db.collection.createIndex({user_id: 1, add_time: 1}, {background: true})
创建索引特别要注意的是将background设置为true,在建索引的过程会阻塞其它数据库操作,background可指定以后台方式创建索引,默认为false。这可是血的教训呀,切记切记。
Security
MongoDB中的安全需要重视,目前启动不知道有没有强制的限制,以前启动的时候可以不指定认证的方式,也就是不需要密码即可访问,然后很多人都直接用的默认端口,暴露在公网上,给不法分子有机可乘,出现了数据被删,需要用比特币来找回数据的案例比比皆是。
还是要开启安全认证,内置了很多角色,不同的角色可操作的内容不一样,控制的比较细。
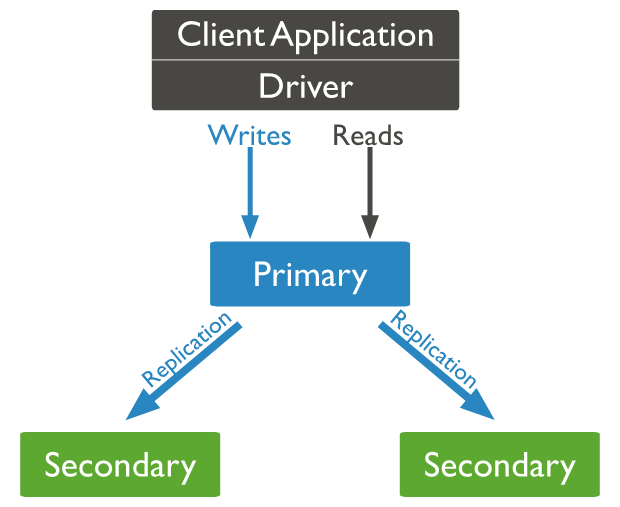
Replication
副本集是一组相同数据集的MongoDB实例,同时在多个节点存储数据,提高了可用性。主节点负责写入,从节点负责读取,提高整体性能。
副本集由下面的组件构成:
Primary:主节点接收所有的写操作。
Secondaries:从节点会从主节点进行数据的复制,维护跟主节点相同的数据。用于查询操作。
Arbiter:仲裁节点本身不存储数据,只参与选举。
Sharding
分片是MongoDB绝对的亮点,将数据水平拆分到多个节点。MongoDB的分片是全自动的,我们只需要配置好分片的规则,它就能自动维护数据并存储到不同节点。MongoDB使用分片来支持大数据量的存储和高吞吐量的操作。
下图是Mongodb的分片集群架构图:
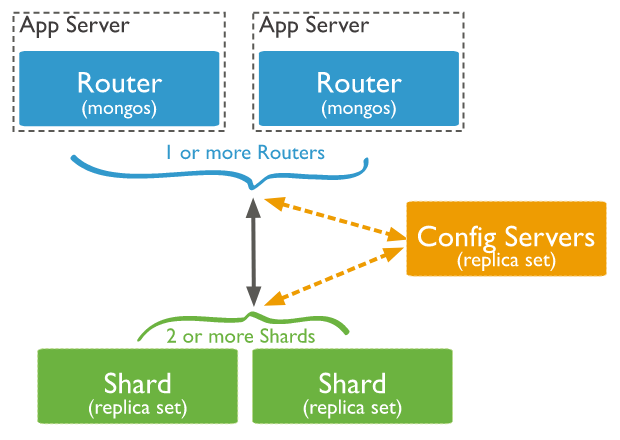
MongoDB分片集群由以下组件够成:
Shard:每个shard的数据都是独立完整的一份。并且可以作为副本集部署。
mongos:mongos是查询路由器,在客户端和服务端中间的一层,请求会直接到mongos,由mongos路由到具体的Shard。
Config Servers:存储集群所有节点、分片数据路由信息。
GridFS
GridFS是MongoDB的一个子模块,主要用于在MongoDB中存储文件,相当于MongoDB内置的一个分布式文件系统。
本质上还是讲文件的数据分块存储在集合中,默认的文件集合分为fs.files和fs.chunks。
fs.files是存储文件的基本信息,比如文件名,大小,上传时间,md5等。fs.chunks是存储文件真正数据的地方,一个文件会被分割成多个chunk块进行存储,一般为256k/个。
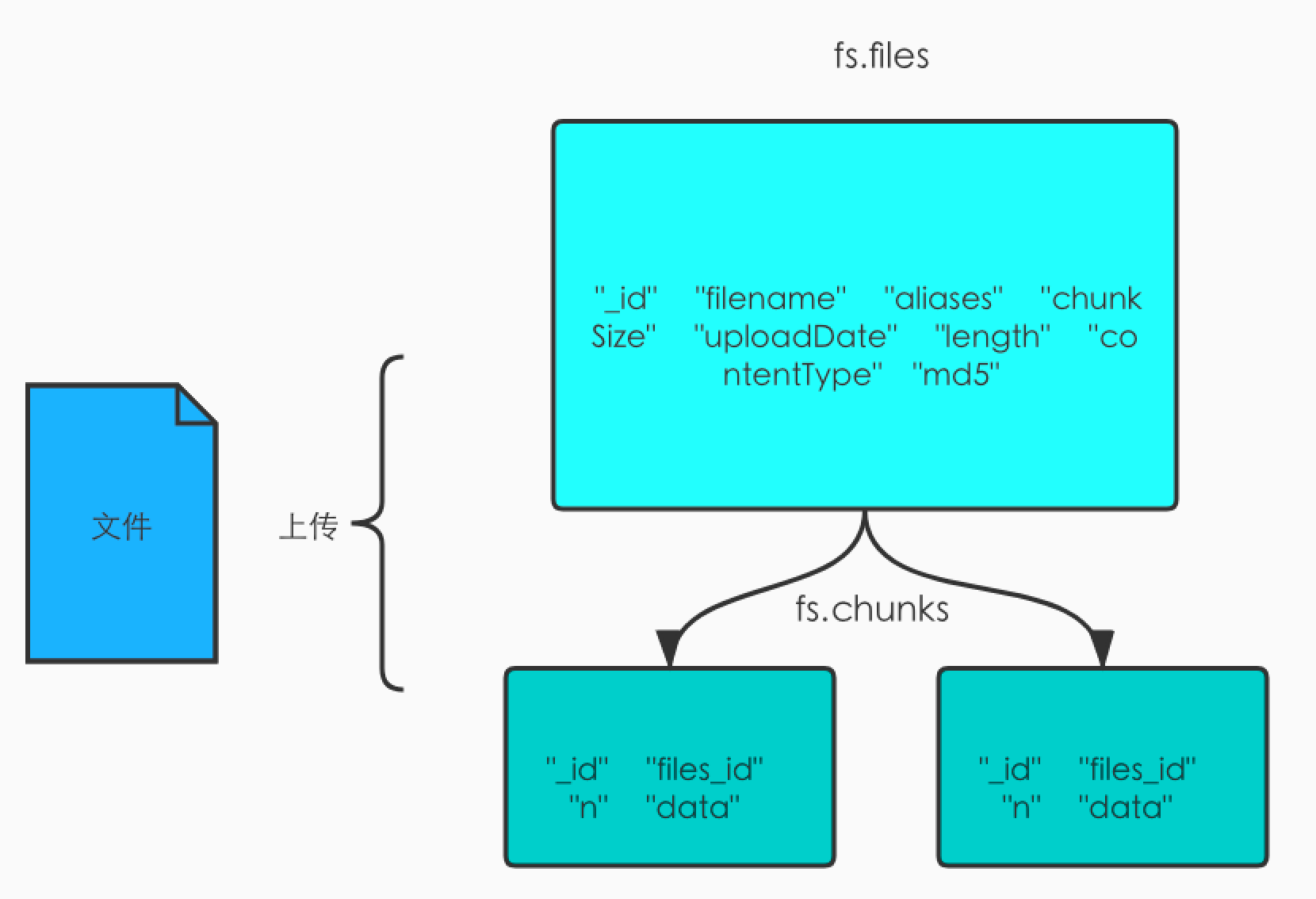
如果你的项目中用到了MongoDB,那么你可以使用GridFS来构建一个文件系统,这样就不用去购买第三方的存储服务了。
GridFS的好处是你不用单独去搭建一个文件系统,直接使用Mongodb自带的即可,备份,分片都依赖MongoDB,维护起来也方便。
知识点总结
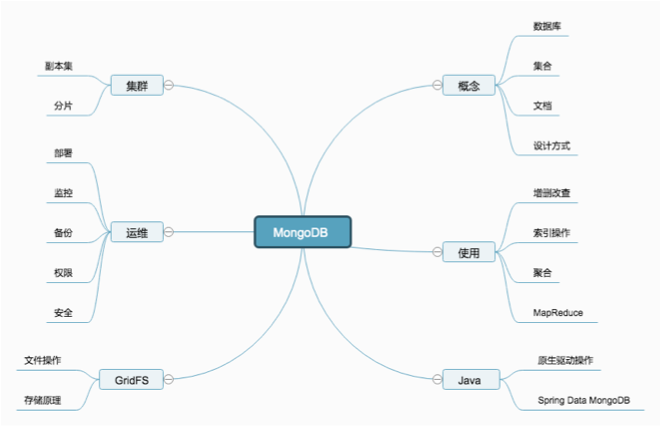
下图是我自己总结的一些知识点,作为一个后端开发来说,能掌握下面的内容就已经不错了,毕竟我们又不是要去抢DBA的饭碗,如果大家业余时间要学习的话可以按照下面的点进行学习,几年前我录制了一套视频,在我的网站上,大部分内容都覆盖到了。
工作必用
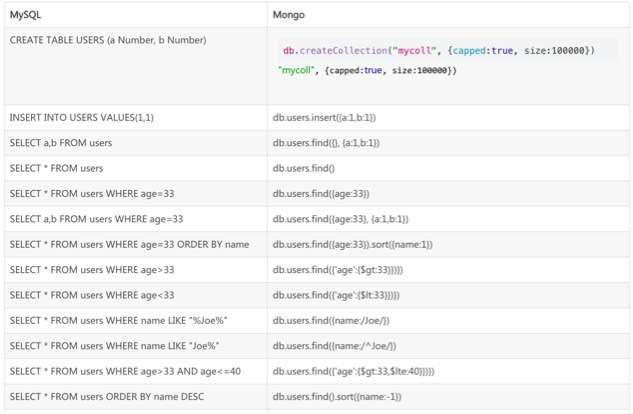
MongoDB跟Mysql的语法对比

Spring Boot中集成MongoDB
加入MongoDB的依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
配置MongoDB的信息:
spring.data.mongodb.database=test
spring.data.mongodb.host=localhost
spring.data.mongodb.port=27017
// 用户名,密码省略.......
直接注入MongoTemplate就可以操作MongoDB:
@Autowired
private MongoTemplate mongoTemplate;
使用示列
创建一个实体类,对应MongoDB的集合
@Data
@Document(collection = "article_info")
public class Article {
@Id
@GeneratedValue
private Long id;
@Field("title")
private String title;
@Field("url")
private String url;
@Field("author")
private String author;
@Field("tags")
private List<String> tags;
@Field("visit_count")
private Long visitCount;
@Field("add_time")
private Date addTime;
}
最终存储到数据中的格式如下:
{
"_id" : ObjectId("5e141148473cce6a9ef349c7"),
"title" : "批量更新",
"url" : "http://cxytiandi.com/blog/detail/8",
"author" : "yinjihuan",
"tags" : [
"java",
"mongodb",
"spring"
],
"visit_count" : NumberLong(10),
"add_time" : ISODate("2019-02-11T07:10:32.936+0000")
}
插入数据
Article article = new Article();
article.setTitle("MongoTemplate 的基本使用 ");
article.setAuthor("yinjihuan");
article.setUrl("http://cxytiandi.com/blog/detail/1");
article.setTags(Arrays.asList("java", "mongodb", "spring"));
article.setVisitCount(0L);
article.setAddTime(new Date());
mongoTemplate.save(article);
数据库语法
db.article_info.save({
"title": "批量更新",
"url": "http://cxytiandi.com/blog/detail/8",
"author": "yinjihuan",
"tags": [
"java",
"mongodb",
"spring"
],
"visit_count": NumberLong(10),
"add_time": ISODate("2019-02-11T07:10:32.936+0000")
})
更新数据
Query query = Query.query(Criteria.where("author").is("yinjihuan"));
Update update = Update.update("title", "MongoTemplate")
.set("visitCount", 10);
mongoTemplate.updateMulti(query, update, Article.class);
数据库语法
db.article_info.updateMany(
{"author":"yinjihuan"},
{"$set":
{
"title":"MongoTemplate",
"visit_count": NumberLong(10)
}
}
)
删除数据
Query query = Query.query(Criteria.where("author").is("yinjihuan"));
mongoTemplate.remove(query, Article.class);
数据库语法
db.article_info.remove({"author":"yinjihuan"})
查询数据
Query query = Query.query(Criteria.where("author").is("yinjihuan"));
List<Article> articles = mongoTemplate.find(query, Article.class);
数据库语法
db.article_info.find({"author":"yinjihuan"})
存储文件
File file = new File("/Users/yinjihuan/Downloads/logo.png");
InputStream content = new FileInputStream(file);
// 存储文件的额外信息,比如用户ID,后面要查询某个用户的所有文件时就可以直接查询
DBObject metadata = new BasicDBObject("userId", "1001");
ObjectId fileId = gridFsTemplate.store(content, file.getName(), "image/png", metadata);
源码参考
客户端推荐
下载地址:
spring-boot-starter-mongodb-pool
最后推荐一个我自己写的小框架:Spring Boot中增强Mongodb的配置,多数据源,连接池
感兴趣的可以关注下我的微信公众号 猿天地,更多技术文章第一时间阅读。我的GitHub也有一些开源的代码 https://github.com/yinjihuan
共同学习,写下你的评论
评论加载中...
作者其他优质文章


