

千里之行始于足下,学习大数据我们首先就要先接触Hadoop,上节介绍到Hadoop分为Hadoop-HDFS,Hadoop-YARN,Hadoop-Mapreduce组成,分别负责分布式文件存储,任务调度,计算处理,本机我们在单机模式下把Hadoop运行起来并且简单的使用接触Hadoop相关的机制.
附上:
Hadoop的官网:hadoop.apache.org
喵了个咪的博客:w-blog.cn
1.环境准备
这里所有的系统统一使用Centos7.X 64位系统 其他系统未经过测试
创建install目录存放各项包,使用oneinstack更新基础组件(按照提示选择即可)
> mkdir -p /app/install && cd /app/install
# 使用oneinstack更新一下环境基础组件 全部选择N即可
> wget http://mirrors.linuxeye.com/oneinstack-full.tar.gz
> tar -zxvf oneinstack-full.tar.gz
> cd oneinstack && ./install.sh
创建hadoop用户并设置密码(如果暴露外网IP务必使用复杂密码避免攻击)
useradd -m hadoop -s /bin/bash
passwd hadoop
为 hadoop 用户增加管理员权限,方便使用sudo来以root权限来进行操作
visudo
# 找到root复制一条改为hadoop
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
添加SSH免密登录
# 先切换到hadoop用户
su hadoop
ssh-keygen -t rsa # 会有提示,都按回车就可以
cd ~/.ssh/
cat id_rsa.pub >> authorized_keys # 加入授权
chmod 600 ./authorized_keys # 修改文件权限
ssh localhost # 此时使用ssh首次需要yes以下不用密码即可登录
2.Hadoop安装
这里使用的Hadoop版本为2.7.3版本可以自行在官网下载
统一安装目录均为**/usr/local/XX**
2.1 环境配置
需要准备好JAVA安装包和Hadoop安装包,我们把以下两个文件放到我们创建好的install目录下
hadoop-2.7.3.tar.gz
jdk-8u101-linux-x64.tar.gz
JAVA环境
cd /app/install
sudo tar -zxvf jdk-8u101-linux-x64.tar.gz
sudo mv jdk1.8.0_101/ /usr/local/jdk1.8
环境变量增加如下内容
sudo vim /etc/profile
# JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8
export JRE_HOME=/usr/local/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
# 使环境变量生效
source /etc/profile
如下结果为Java安装成功输出
java -version
java version "1.8.0_101"
Java(TM) SE Runtime Environment (build 1.8.0_101-b13)
Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
Hadoop环境
> sudo tar -zxvf hadoop-2.7.3.tar.gz
> sudo mv hadoop-2.7.3 /usr/local/
> sudo chown -R hadoop:hadoop /usr/local/hadoop-2.7.3
环境变量增加如下内容
> sudo vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 使环境变量生效
> source /etc/profile
查看hadoop版本信息验证是否安装成功
hadoop version
# 如下结构为安装成功
Hadoop 2.7.3
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff
Compiled by root on 2016-08-18T01:41Z
Compiled with protoc 2.5.0
From source with checksum 2e4ce5f957ea4db193bce3734ff29ff4
This command was run using /usr/local/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar
2.1 测试Hadoop是否正常
Hadoop 默认模式为非分布式模式,无需进行其他配置即可运行。非分布式即单 Java 进程,方便进行调试。
现在我们可以执行例子来感受下 Hadoop 的运行。Hadoop 附带了丰富的例子运行如下命令可以看到所有例子 包括 wordcount、terasort、join、grep 等。
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar
在此我们选择运行 grep 例子来验证搭建的hadoop是否可以正常运行,我们将 input 文件夹中的所有文件作为输入,筛选当中符合正则表达式 dfs[a-z.]+ 的单词并统计出现的次数,最后输出结果到 output 文件夹中。
cd $HADOOP_HOME
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
# 如果运行成功结果如下
1 dfsadmin
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
3.Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 $HADOOP_HOME/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件hadoop-env.sh 更新JAVA_HOME环境变量
export JAVA_HOME=/usr/local/jdk1.8
修改配置文件 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
这里配置namenode和datanode的目录,namenode和datanode是什么东西呢??
NameNode:管理文件系统的元数据,所有的数据读取工作都会先经过NameNode获取源数据在哪个DataNode里面在进行获取操作
DataNode:实际数据存储节点,具体的映射关系会存储在NameNode下
修改配置文件vim :
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.3/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.3/tmp/dfs/data</value>
</property>
</configuration>
配置完成后,执行 NameNode 的格式化:
hdfs namenode -format
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若为 “Exitting with status 1” 则是出错。
接着开启 NaneNode 和 DataNode 守护进程:
start-dfs.sh
若出现如下 SSH 的提示 “Are you sure you want to continue connecting”,输入 yes 即可。
启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode”和SecondaryNameNode(如果 SecondaryNameNode 没有启动,请运行 sbin/stop-dfs.sh 关闭进程,然后再次尝试启动尝试)。如果没有 NameNode 或 DataNode ,那就是配置不成功,请仔细检查之前步骤,或通过查看启动日志排查原因。
16035 Jps
15748 DataNode
15621 NameNode
15911 SecondaryNameNode
成功启动后,可以访问 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录:
hdfs dfs -mkdir -p /user/hadoop
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input:
hdfs dfs -mkdir input
hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml input
复制完成后,可以通过如下命令查看 HDFS 中的文件列表:
hdfs dfs -ls input
伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
查看运行结果的命令(查看的是位于 HDFS 中的输出结果):
hdfs dfs -cat output/*
1 dfsadmin
1 dfs.replication
1 dfs.namenode.name.dir
1 dfs.datanode.data.dir
Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹:
hdfs dfs -rm -r output
若要关闭 Hadoop-HDFS,则运行
stop-dfs.sh
4.YARN
(伪分布式不启动 YARN 也可以,一般不会影响程序执行)
有的读者可能会疑惑,怎么启动 Hadoop 后,见不到书上所说的 JobTracker 和 TaskTracker,这是因为新版的 Hadoop 使用了新的 MapReduce 框架(MapReduce V2,也称为 YARN,Yet Another Resource Negotiator)。
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运行于 MapReduce 之上,提供了高可用性、高扩展性,YARN 的更多介绍在此不展开,有兴趣的可查阅相关资料。
上述通过 start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
首先修改配置文件 mapred-site.xml
mv $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
接着修改配置文件 yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
然后就可以启动 YARN 了
start-yarn.sh $ 启动YARN
mr-jobhistory-daemon.sh start historyserver # 开启历史服务器,才能在Web中查看任务运行情况
在使用jps查看可以看到多了几项
16707 ResourceManager
15748 DataNode
15621 NameNode
15911 SecondaryNameNode
16811 NodeManager
17199 Jps
17151 JobHistoryServer
启动 YARN 之后,运行实例的方法还是一样的,仅仅是资源管理方式、任务调度不同。观察日志信息可以发现,不启用 YARN 时,是 “mapred.LocalJobRunner” 在跑任务,启用 YARN 之后,是 “mapred.YARNRunner” 在跑任务。启动 YARN 有个好处是可以通过 Web 界面查看任务的运行情况:ur,如下图所示。但 YARN 主要是为集群提供更好的资源管理与任务调度,然而这在单机上体现不出价值,反而会使程序跑得稍慢些。因此在单机上是否开启 YARN 就看实际情况了。
不启动 YARN 需重命名 mapred-site.xml
如果不想启动 YARN,务必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template,需要用时改回来就行。否则在该配置文件存在,而未开启 YARN 的情况下,运行程序会提示 “Retrying connect to server: 0.0.0.0/0.0.0.0:8032” 的错误,这也是为何该配置文件初始文件名为 mapred-site.xml.template。
同样的,关闭 YARN 的脚本如下:
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
YARN webui
启动yarn之后可以通过web界面查看执行进度等,访问hadoop-1:8080会获得如下界面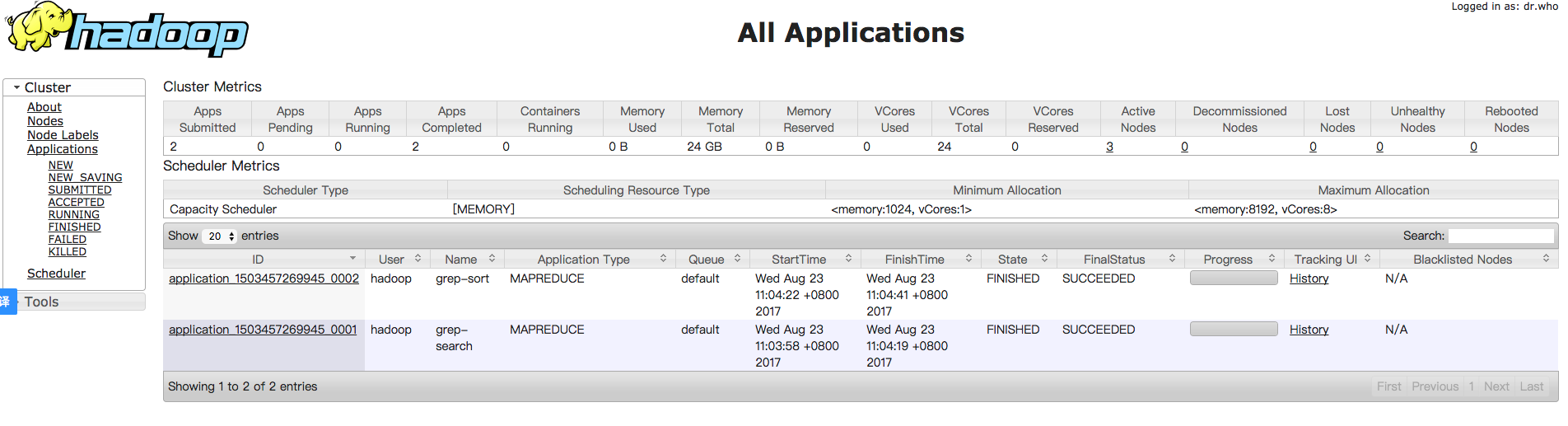
5 总结
本节我们先简单了解了一下Hadoop大家应该对Hadoop有了一个简单的概念,HDFS是什么,怎么配置环境,怎么测试运行情况,但是这仅仅是一个开始后面还有很长的路要走,那么大家要是有问题可以在博文下留言,有好的想法可以来和喵咪来沟通交流哦!
注:笔者能力有限有说的不对的地方希望大家能够指出,也希望多多交流!
共同学习,写下你的评论
评论加载中...
作者其他优质文章



