
苍茫大地一剑尽挽破,何处繁华笙歌落。 难道这普天之下尽没我容纳之处?为何这面试官总要与我争风相对,这不是难为人吗?
每次经历痛领悟,总会悠然南山下,独自愁楚。记录心中一片大海,唯有独自努力,方能实现行业之俊杰。
前言
一个阳光明媚得上午,迎面走来了一位身着雪白雪白得的白色衬衣,灰白色相间的休闲短裤,还给我露出了彰显男儿本色的黑色腿毛。手拿银色金属质感得 MacBook Pro,外加一双小白鞋。看着那稀少的发量,在灯光的照耀下,甚至还有点反光。透过那从容不迫的脸色。
我内心不忍一颤,今天怕是要遇到人了。整整一个架构师的大叔呀。
果不其然,他手里拿着我的简历,快速的扫了一下,然后用眼角余光看了一下我,像是在掂量着什么。上来开口即问。
事务简介和原理
面试官: 看你简历描述精通 Mysql 优化方法,那你先说说你对Mysql的事务的了解吧。
我吒吒辉内心独自平静了一些,这个不难,就是一个事务定义和执行得调用的方法。殊不知后面的内容都是对我得严刑拷打。
吒吒辉: 好呢,数据库的事务是指一组sql语句访问各种数据项的数据库逻辑处理单元,在这组 SQL 操作中,要么全部执行成功,要么全部执行失败。
举个经典的例子就是转账,事务 A 要进行转账,那么,转出的账号要扣钱,转入的账号要加钱,这两操作要么同时执行成功,要么都全部执行失败。为得就是确保数据的一致性。
吒吒辉: 一般请求进入MySQL,都是根据不同请求类型先在服务层内部做数据处理,然后在由后台线程把数据刷到磁盘中。从而避免频繁的读写磁盘。
回答完毕后,自己笑笑的模一下头发,打理一下自己的发型,整理了一下脖子上得领结。
面试官:吆喝,这小子还有点料啊,敢在太岁头上动土,你还要反了天呀你。还在这欺负我头上的没头发。个小崽子。
面试官: 刚你提到了 MySQL 内部的工作,那你知道事务的特性吗? 数据是如何刷盘? 服务层数据如何修改? 这样得工作模式有什么好处? 怎么避免频繁写入? 读请求和写请求在服务层工作是一样的吗?
我内心一钝,这老秃驴,不要命啦,逮到这么问我。看来自己得正经点,感觉空气中弥漫着杀气腾腾的气息。
尴尬的冲他笑了一笑。立马说到
吒吒辉: 在Mysql中事务的四大特性主要包含:
原子性(Atomicity)
一致性(Consistent)
隔离性(Isalotion)
持久性(Durable),简称为 ACID。由它们共同来保证数据的一致性。
面试官: 嗯,说说你对这四大特的理解?
吒吒辉:
- 原子性: 故名思议原子是最小的元素单位,所以一个事务是一个不可拆分的最小工作单元。整个事务操作要么全部执行成功,要么全部失败回滚。
因执行成功和失败都是状态的变化,如果只有执行效果只有一半,数据就会不完整,从而违背了原子的特点。
-
一致性: 指数据库从一个一致性的状态转换到另外一个一致性的状态。要保证事务前后的状态要一致
-
隔离性:一个事务所做的修改在最终提交以前,对其他事务是不可见的。
-
持久性:一旦事务提交,则其所做的修改就会永久保存到磁盘上。是执行结果一直生效。

面试官: 那数据库底层是如何实现这四大特性的?
顿时,我望向他那张有点油腻的大脸,可他确实气定神闲的望着我,面相是多么的随和。此刻内心不断策马崩腾,第一个问题就给我整了这么多,后面可咋办? 内心感觉悬了
吒吒辉:
- 原子性:由 undo log 保证,也称回滚日志,主要用于记录数据被修改前的信息
undo log 主要记录数据的逻辑变化。所以需要将之前的操作都记录下来,然后在发生错误或执行事务回滚时才能保证回滚到之前的操作。
面试官: 那这个请求过程是怎么实现的?
比如当写请求为 insert 操作进入到数据库服务层时,会先在缓冲池下面的写缓冲中进行数据的写入,然后先把写请求的物理语言写入到 read log中,并记录一条删除当前语句的逻辑语句到 undo log中。 最后由 MySQL 后台线程定期刷新数据到磁盘里面。
但是这个写缓冲在5.5之前叫 插入缓冲,只针对 insert 优化; 现在对 update 和 delete更新操作都有效。现在叫做:写缓冲
面试官: 这个写缓冲有什么好处呢?
吒吒辉:
避免频繁磁盘I/O的写操作,如果没得这玩意,需要在磁盘里面读到数据,然后才能数据上面的修改。
但大多数场景下都是读多写少,如果在高并发的场景下,通过打包批次处理就能有效避免,在写操作处理时资源开销而影响到大量得读请求。
-
一致性: 由 Redo log 日志保证,也叫重做日志,是用来实现事务的持久性。该日志文件由两部分组成:重做日志缓冲(redo log buffer)以及重做日志文件(redo log),前者是在内存中,后者在磁盘中。
当事务提交之后会把所有修改信息都会存到该日志中。假设有个表叫做t1(id,username) 现在要插入数据(3,‘吒吒辉’)。
start transaction;
//数据写入 写缓冲中
insert into t1 (id,username) values (3,'吒吒辉')
// 生成 重做日志 id =3 , username = '吒吒辉'
commit;
面试官: 那这 redo log 有什么作用?
为了提升性能,不会把每次的修改都实时同步到磁盘,而是会先存到Boffer Pool(缓冲池)里头,把这个当作缓存来用。然后使用后台线程去做缓冲池和磁盘之间的同步。
面试官: 那如果缓冲池的数据还没来得急同步就宕机或断电了怎么办? 这样可是会导致丢部分已提交事务的修改信息!
吒吒辉: 所以引入redo log来记录已成功提交事务的修改信息,并且会把redo log持久化到磁盘,系统重启之后在读取redo log恢复最新数据
面试官: 可以举一个场景,怎么应用它们呢?
吒吒辉: 假如某个时刻数据库崩溃,在崩溃之前有相关事务在执行,一半已经提交,一半还未提交。当数据库重启进行 crash-recovery 时,就会通过 Redo log将已经提交事务的更改先载入到内存,然后再写到数据文件,而还没有提交的就通过 Undo log 进行 roll back。
面试官: 嗯,继续

此时,内心发毛。回答到这个程度,还面不改色,就一个继续打发我了?你可真是深造。
吒吒辉:
- 隔离性 也叫多版本并发控制。
InnoDB的 MVCC ,是通过在每行记录的后面保存两个隐藏的列来实现的。这两个列, 一个保存了行的创建时间,一个保存了行的过期时间(或删除时间), 当然存储的并不是实际的时间值,而是系统版本号。
–摘自《高性能Mysql》这本书对MVCC的定义
面试官: 那不同的SQL请求,MySQL 是如何实现得?
吒吒辉:
- select 请求根据系统当前的事务版本号去和数据列中版本号做对比,先过滤存在过期时间的数据列。然后取出满足小于或者等于当前版本号的记录。
- insert innodb为每插入一行,就保留当前系统版本号为行版本
- delete innodb为删除每一行,就保存当前系统版本号作为行删除标识。
- update innodb为insert 插入一行新记录,保存当前系统版本号作为行版本号,同时保存当前系统版本号到原来的行作为行删除标识。

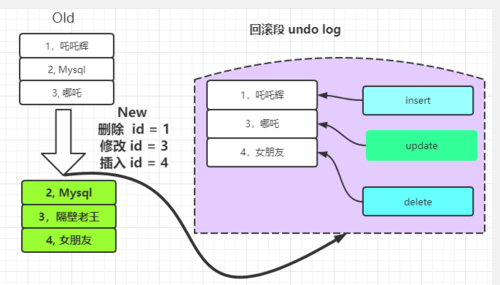
面试官: 那这个机制有什么好处?
吒吒辉:
它主要实现思想是通过数据多版本来做到读写分离。每个请求给到不同版数据来执行。从而实现不加锁读进而做到读写并行。
MVCC机制实现还需要依赖于 undo log与read view
undo log: undo log 中记录某行记录的多个版本的数据。
read view: 用来判断当前版本数据的可读性
面试官: 那你给我画个图看看
什么鬼,这玩意还画图。我用那水汪汪的大眼睛,直勾勾的看着他。只见他看口说到。
** 面试官:没明白吗? 就是用白板笔画出原理图解
吒吒辉: 我急忙应和到。额额额,好

吒吒辉: 就这样,每个请求修改时就会对应一个版本。
面试官: 那这 MVCC 是如何保证多个版本数据得最终一致呢?
吒吒辉: 因数据操作为多个版本,所以它支持读写并行。
在请求进行事务操作前,会先入到读、写队列里面,然后再分别执行读写请求。若第一个写请求执行事务但未提交,但这时它就会拿到最新版本。
如果此时读请求进入也会直接执行,只不过读取数据时得系统版本就为未执行写请求的版本号,根据它来进行数据的读取。
这样在事务未进行提交前,所有读操作读取到的数据是一样的,因为它受系统当前版本控制。读取的都是同一个版本数据。
面试官: MySQL是多线程, 那同时有多个线程修改同一行数据,这种情况怎么处理的?
吒吒辉: 一般如果系统达到并发执行的情况,对用户请求得要求是很高的,每秒至少得几万请求,如有并发问题产生。
假如事务 A、B 都要执行 update 操作,事务A先 update 数据时,会先获取行锁,锁定数据,当事务 B 要进行 update 操作时,也会尝试获取该数据行的行锁,但此时已经被事务A占有,故事务B只能 wait。
吒吒辉: 如事务A,是个很费时的大SQL,长时间没释放锁。那么事务 B 就会等待超时。
查询全局等待事务锁超时时间
SHOW GLOBAL VARIABLES LIKE ‘innodb_lock_wait_timeout’;
面试官: 这个是在 update 的where后的条件是在有索引的情况下吧?
吒吒辉: 嗯,是的,因为 innodb 的行数只有索引才会触发,锁定的是行锁
面试官: 那没有索引的条件下,就没办法快速定位到数据行呀?
吒吒辉: 若是没有索引的条件下,就会退化为表锁。 然后获取所有行后,Mysql 再过滤符合条件的的行并释放锁。往后只有符合条件的行才持有锁。
吒吒辉: 这样就降低了并发度,并且性能开销也会很大。
吒吒辉: 而最后的一致性,实际上是通过原子性、持久性、隔离性来实现的
此刻,感觉自己多少放松了一些,内心有点小得意,感觉达到了巅峰时刻。然后再拿着面前的矿泉水,饮了一口,顺便擦了下汗水。一切是那么得行云流水。然而面试官那脸还是一沉不变,像是在酝酿着什么,这不又开始了。
MySQL 内核工作原理
面试官: 那请继续数据是如何刷盘? 这样得工作模式是怎么避免频繁读写得?
吒吒辉: 说到数据刷盘,首先得谈下 innodb 缓冲池。
buffer pool 主要由数据、索引、插入缓冲、自适应哈希索引、锁等组成。
不同请求会根据 buffer pool里面对应部分数据来执行相关的操作。buffer pool中的数据会根据配置参数定期同步到磁盘中;只是这里刷盘的数据主要由 数据和日志 组成。
数据
* 由 innodb_max_dirty_pages_pct 参数决定。在说到这个之前,得说说脏页。
脏页指存在于内存中的数据,但未同步到持久化存储里面,因为数据库的数据用页来读取,故此称之为脏页。
innodb_max_dirty_pages_pct 参数可动态调整,最小值为0, 最大值为99.99,默认值为 75。
根据缓冲池的大小和存储脏页的数量计算比例,如果满足了就调用后台线程把数据刷新到持久层当中里面。
这样做的好处就是合并其它数据页,从而提高写入的效率。
日志
由 innodb_flush_log_at_trx_commit 变量来控制日志缓冲刷新频繁程度。
-
0:把日志缓冲写到日志文件,并且每秒钟刷新一次持久化存储,但是事务提交时不做任何事。
-
1: 将日志缓冲写到日志文件,并且每次事务提交都刷新到持久化存储。这是默认的(并且是最安全的)设置,该设置能保证不会丢失任何已经提交的事务,除非磁盘或者操作系统是“伪”刷新,即写入到磁盘缓冲。
-
2: 每次提交时把日志缓冲写到日志文件,但是并不刷新到持久化存储。InnoDB 每秒做一次刷新到持久化存储。一般也会选2,如果MySQL进程“挂了”,2 不会丢失任何事务。如果整个服务器“挂了”或者断电了,则还是可能会丢失 1s 的事务。
为什么上面把日志缓冲写到日志文件,还没到持久化存储呢?
因为在大部分操作系统中,把日志缓冲写到日志文件只是简单地把数据从 InnoDB 的内存缓冲转移到了操作系统的缓存,也是在内存里,并没有真的把数据写到了持久化存储。所以还需要进行数据磁盘同步的刷写。
吒吒辉: 缓冲池是降低频繁得读写请求,这个得分情况来看:
- 读请求: 请求首先在缓冲池下面找缓存的数据,从而避免每次访问都进行磁盘IO。
- 写请求:事务请求执行时,先根据日志缓冲配置的方式把数据记录到日志文件中,等数据的脏页达到一定比例或内存不够时,就会把数据落地磁盘上。
从而把大量磁盘的随机I/O改写为顺序I/O。
每次更新相关请求都基于 MVCC 特性拿到当前操作数据最新版本,从而并发执行多个版本。

面试官: 嗯嗯
瞬间感觉被榨干了,怎么都这样出招,幸好以前多少有点准备。忽然感觉自己身后开始滑落着汗滴。只见面试官看了看简历,脸上表情祥和,感觉在端详着什么。。。。
面试官: 小伙,这今天就面到这里,我看你好像有点热呀,先回去等通知吧
感情你老这才开胃呀!还能这样整。行不行你到是给句花呗。让我流这么多汗,我得喝多少水才补得回来,这不虚都被你搞虚。瞬间炸裂开来
吒吒辉: 这样啊,那好吧。。。。
我命由我不由天,只为那不甘心的,如有帮助,关注分享额
共同学习,写下你的评论
评论加载中...
作者其他优质文章


