
@[toc]
ElasticSearch 系列教程我们前面已经连着发了两篇了,今天第三篇,我们来聊一聊 Es 中的文档并发处理和文档路由问题。
本文是松哥所录视频教程的一个笔记,笔记简明扼要,完整内容小伙伴们可以参考视频,视频下载链接:pan.baidu.com/s/1TwyOm2i28fDZh7rkNF-jww 提取码: aee2

1. ElasticSearch 文档基本操作
1.1 新建文档
首先新建一个索引。
然后向索引中添加一个文档:
PUT blog/_doc/1
{
"title":"6. ElasticSearch 文档基本操作",
"date":"2020-11-05",
"content":"微信公众号**江南一点雨**后台回复 **elasticsearch06** 下载本笔记。首先新建一个索引。"
}
1 表示新建文档的 id。
添加成功后,响应的 json 如下:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
- _index 表示文档索引。
- _type 表示文档的类型。
- _id 表示文档的 id。
- _version 表示文档的版本(更新文档,版本会自动加 1,针对一个文档的)。
- result 表示执行结果。
- _shards 表示分片信息。
_seq_no和_primary_term这两个也是版本控制用的(针对当前 index)。
添加成功后,可以查看添加的文档:

当然,添加文档时,也可以不指定 id,此时系统会默认给出一个 id,如果不指定 id,则需要使用 POST 请求,而不能使用 PUT 请求。
POST blog/_doc
{
"title":"666",
"date":"2020-11-05",
"content":"微信公众号**江南一点雨**后台回复 **elasticsearch06** 下载本笔记。首先新建一个索引。"
}
1.2 获取文档
Es 中提供了 GET API 来查看存储在 es 中的文档。使用方式如下:
GET blog/_doc/RuWrl3UByGJWB5WucKtP
上面这个命令表示获取一个 id 为 RuWrl3UByGJWB5WucKtP 的文档。
如果获取不存在的文档,会返回如下信息:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "2",
"found" : false
}
如果仅仅只是想探测某一个文档是否存在,可以使用 head 请求:
如果文档不存在,响应如下:

如果文档存在,响应如下:

当然也可以批量获取文档。
GET blog/_mget
{
"ids":["1","RuWrl3UByGJWB5WucKtP"]
}
这里可能有小伙伴有疑问,GET 请求竟然可以携带请求体?
某些特定的语言,例如 JavaScript 的 HTTP 请求库是不允许 GET 请求有请求体的,实际上在 RFC7231 文档中,并没有规定 GET 请求的请求体该如何处理,这样造成了一定程度的混乱,有的 HTTP 服务器支持 GET 请求携带请求体,有的 HTTP 服务器则不支持。虽然 es 工程师倾向于使用 GET 做查询,但是为了保证兼容性,es 同时也支持使用 POST 查询。例如上面的批量查询案例,也可以使用 POST 请求。
1.3 文档更新
1.3.1 普通更新
注意,文档更新一次,version 就会自增 1。
可以直接更新整个文档:
PUT blog/_doc/RuWrl3UByGJWB5WucKtP
{
"title":"666"
}
这种方式,更新的文档会覆盖掉原文档。
大多数时候,我们只是想更新文档字段,这个可以通过脚本来实现。
POST blog/_update/1
{
"script": {
"lang": "painless",
"source":"ctx._source.title=params.title",
"params": {
"title":"666666"
}
}
}
更新的请求格式: POST {index}/_update/{id}
在脚本中,lang 表示脚本语言,painless 是 es 内置的一种脚本语言。source 表示具体执行的脚本,ctx 是一个上下文对象,通过 ctx 可以访问到 _source、_title 等。
也可以向文档中添加字段:
POST blog/_update/1
{
"script": {
"lang": "painless",
"source":"ctx._source.tags=[\"java\",\"php\"]"
}
}
添加成功后的文档如下:

通过脚本语言,也可以修改数组。例如再增加一个 tag:
POST blog/_update/1
{
"script":{
"lang": "painless",
"source":"ctx._source.tags.add(\"js\")"
}
}
当然,也可以使用 if else 构造稍微复杂一点的逻辑。
POST blog/_update/1
{
"script": {
"lang": "painless",
"source": "if (ctx._source.tags.contains(\"java\")){ctx.op=\"delete\"}else{ctx.op=\"none\"}"
}
}
1.3.2 查询更新
通过条件查询找到文档,然后再去更新。
例如将 title 中包含 666 的文档的 content 修改为 888。
POST blog/_update_by_query
{
"script": {
"source": "ctx._source.content=\"888\"",
"lang": "painless"
},
"query": {
"term": {
"title":"666"
}
}
}
1.4 删除文档
1.4.1 根据 id 删除
从索引中删除一个文档。
删除一个 id 为 TuUpmHUByGJWB5WuMasV 的文档。
DELETE blog/_doc/TuUpmHUByGJWB5WuMasV
如果在添加文档时指定了路由,则删除文档时也需要指定路由,否则删除失败。
1.4.2 查询删除
查询删除是 POST 请求。
例如删除 title 中包含 666 的文档:
POST blog/_delete_by_query
{
"query":{
"term":{
"title":"666"
}
}
}
也可以删除某一个索引下的所有文档:
POST blog/_delete_by_query
{
"query":{
"match_all":{
}
}
}
1.5 批量操作
es 中通过 Bulk API 可以执行批量索引、批量删除、批量更新等操作。
首先需要将所有的批量操作写入一个 JSON 文件中,然后通过 POST 请求将该 JSON 文件上传并执行。
例如新建一个名为 aaa.json 的文件,内容如下:

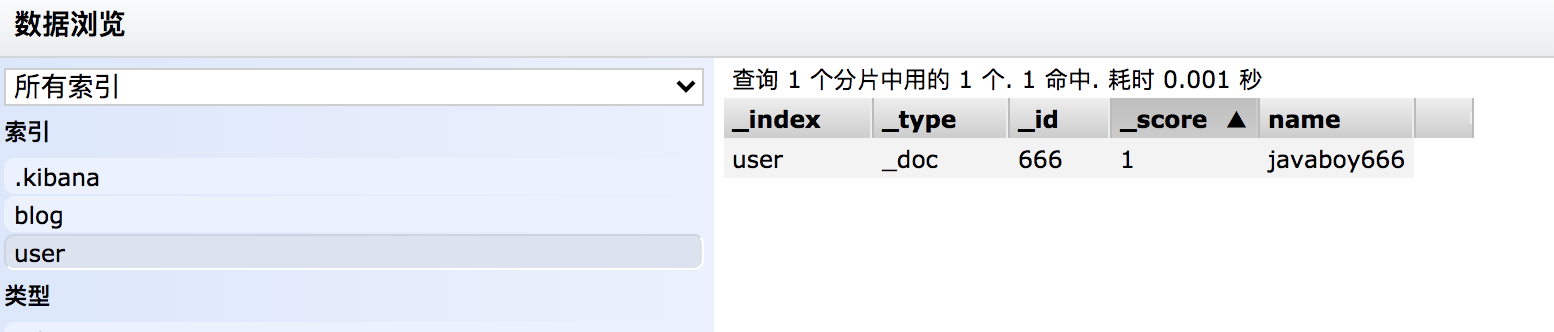
首先第一行:index 表示要执行一个索引操作(这个表示一个 action,其他的 action 还有 create,delete,update)。_index 定义了索引名称,这里表示要创建一个名为 user 的索引,_id 表示新建文档的 id 为 666。
第二行是第一行操作的参数。
第三行的 update 则表示要更新。
第四行是第三行的参数。
注意,结尾要空出一行。
aaa.json 文件创建成功后,在该目录下,执行请求命令,如下:
curl -XPOST "http://localhost:9200/user/_bulk" -H "content-type:application/json" --data-binary @aaa.json
执行完成后,就会创建一个名为 user 的索引,同时向该索引中添加一条记录,再修改该记录,最终结果如下:
2. ElasticSearch 文档路由
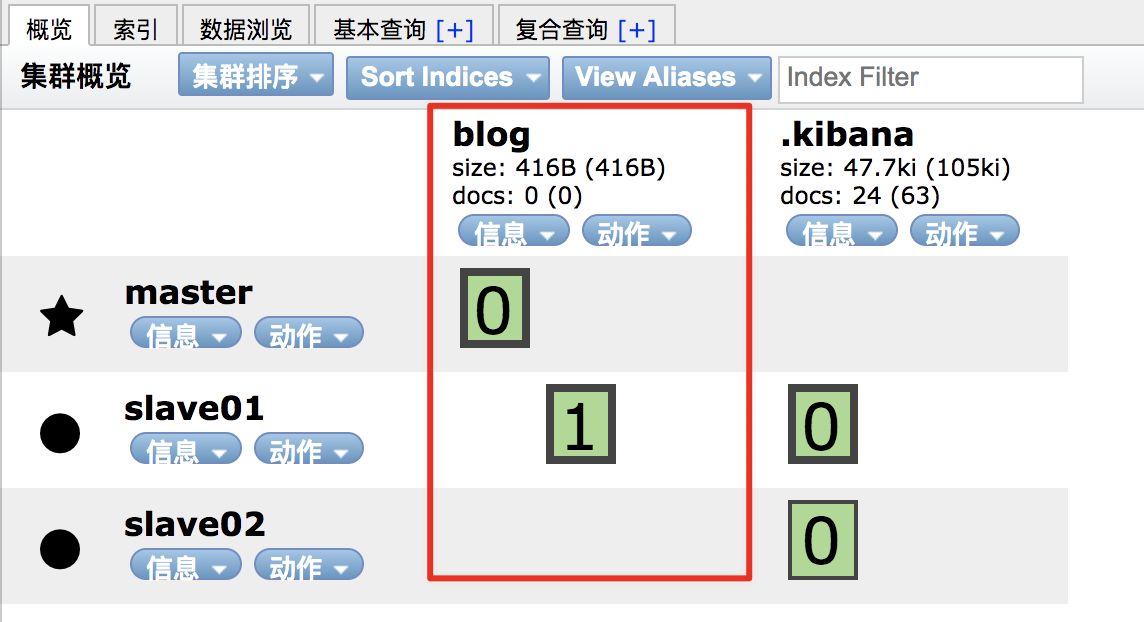
es 是一个分布式系统,当我们存储一个文档到 es 上之后,这个文档实际上是被存储到 master 节点中的某一个主分片上。
例如新建一个索引,该索引有两个分片,0个副本,如下:
接下来,向该索引中保存一个文档:
PUT blog/_doc/a
{
"title":"a"
}
文档保存成功后,可以查看该文档被保存到哪个分片中去了:
GET _cat/shards/blog?v
查看结果如下:
index shard prirep state docs store ip node
blog 1 p STARTED 0 208b 127.0.0.1 slave01
blog 0 p STARTED 1 3.6kb 127.0.0.1 master
从这个结果中,可以看出,文档被保存到分片 0 中。
那么 es 中到底是按照什么样的规则去分配分片的?
es 中的路由机制是通过哈希算法,将具有相同哈希值的文档放到一个主分片中,分片位置的计算方式如下:
shard=hash(routing) % number_of_primary_shards
routing 可以是一个任意字符串,es 默认是将文档的 id 作为 routing 值,通过哈希函数根据 routing 生成一个数字,然后将该数字和分片数取余,取余的结果就是分片的位置。
默认的这种路由模式,最大的优势在于负载均衡,这种方式可以保证数据平均分配在不同的分片上。但是他有一个很大的劣势,就是查询时候无法确定文档的位置,此时它会将请求广播到所有的分片上去执行。另一方面,使用默认的路由模式,后期修改分片数量不方便。
当然开发者也可以自定义 routing 的值,方式如下:
PUT blog/_doc/d?routing=javaboy
{
"title":"d"
}
如果文档在添加时指定了 routing,则查询、删除、更新时也需要指定 routing。
GET blog/_doc/d?routing=javaboy
自定义 routing 有可能会导致负载不均衡,这个还是要结合实际情况选择。
典型场景:
对于用户数据,我们可以将 userid 作为 routing,这样就能保证同一个用户的数据保存在同一个分片中,检索时,同样使用 userid 作为 routing,这样就可以精准的从某一个分片中获取数据。
3. ElasticSearch 版本控制
当我们使用 es 的 API 去进行文档更新时,它首先读取原文档出来,然后对原文档进行更新,更新完成后再重新索引整个文档。不论你执行多少次更新,最终保存在 es 中的是最后一次更新的文档。但是如果有两个线程同时去更新,就有可能出问题。
要解决问题,就是锁。
3.1 锁
悲观锁
很悲观,每一次去读取数据的时候,都认为别人可能会修改数据,所以屏蔽一切可能破坏数据完整性的操作。关系型数据库中,悲观锁使用较多,例如行锁、表锁等等。
乐观锁
很乐观,每次读取数据时,都认为别人不会修改数据,因此也不锁定数据,只有在提交数据时,才会检查数据完整性。这种方式可以省去锁的开销,进而提高吞吐量。
在 es 中,实际上使用的就是乐观锁。
3.2 版本控制
es6.7之前
在 es6.7 之前,使用 version+version_type 来进行乐观并发控制。根据前面的介绍,文档每被修改一个,version 就会自增一次,es 通过 version 字段来确保所有的操作都有序进行。
version 分为内部版本控制和外部版本控制。
3.2.1 内部版本
es 自己维护的就是内部版本,当创建一个文档时,es 会给文档的版本赋值为 1。
每当用户修改一次文档,版本号就回自增 1。
如果使用内部版本,es 要求 version 参数的值必须和 es 文档中 version 的值相当,才能操作成功。
3.2.2 外部版本
也可以维护外部版本。
在添加文档时,就指定版本号:
PUT blog/_doc/1?version=200&version_type=external
{
"title":"2222"
}
以后更新的时候,版本要大于已有的版本号。
- vertion_type=external 或者 vertion_type=external_gt 表示以后更新的时候,版本要大于已有的版本号。
- vertion_type=external_gte 表示以后更新的时候,版本要大于等于已有的版本号。
3.2.3 最新方案(Es6.7 之后)
现在使用 if_seq_no 和 if_primary_term 两个参数来做并发控制。
seq_no 不属于某一个文档,它是属于整个索引的(version 则是属于某一个文档的,每个文档的 version 互不影响)。现在更新文档时,使用 seq_no 来做并发。由于 seq_no 是属于整个 index 的,所以任何文档的修改或者新增,seq_no 都会自增。
现在就可以通过 seq_no 和 primary_term 来做乐观并发控制。
PUT blog/_doc/2?if_seq_no=5&if_primary_term=1
{
"title":"6666"
}
最后,松哥还搜集了 50+ 个项目需求文档,想做个项目练练手的小伙伴不妨看看哦~



需求文档地址:github.com/lenve/javadoc
共同学习,写下你的评论
评论加载中...
作者其他优质文章


