
往 Kafka 写入消息的场景 :
- 记录用户的活动(用于审计和分析)、
- 记录度量指标、
- 保存日志消息、
- 记录智能家电的信息、
- 与其他应用程序进行异步通信、
- 缓冲即将写入到数据库的数据,等等。
多样的使用场景意味着多样的需求:
- 是否每个消息都很重要?
- 是否允许丢失一小部分消息?
- 偶尔出现重复消息是否可以接受?
- 是否有严格的延迟和吞吐量要求?
场景举例:
- 在之前提到的信用卡事务处理系统里,消息丢失或消息重复是不允许的,可以接受的延迟最大为 500ms ,对吞吐量要求较高我们希望每秒钟可以处理一百万个消息。
- 保存网站的点击信息是另一种使用场景。在这个场景里,允许丢失少量的消息或出现少量的消息重复,延迟可以高一些,只要不影响用户体验就行。换句话说,只要用户点击链接后可以马上加载页面,那么我们并不介意消息要在几秒钟之后才能到达 Kafka 服务器。 吞吐量则取决于网站用户使用网站的频度。
1 使用kafka自带工具发送和接收消息
kafka-console-producer.sh 发送消息
[root@docker01 ~]# /usr/local/kafka_2.13-2.6.0/bin/kafka-console-producer.sh --bootstrap-server 192.168.8.31:9092 --topic test
>hello1
>hello test
>
kafka-console-consumer.sh 接收消息
[root@docker01 kafka_2.13-2.6.0]# /usr/local/kafka_2.13-2.6.0/bin/kafka-console-consumer.sh --bootstrap-server 192.168.8.31:9092 --topic test
hello1
hello test
2 Java应用程序创建Kafka 生产者
2.1 应用程序向Kafka 发送消息的主要步骤
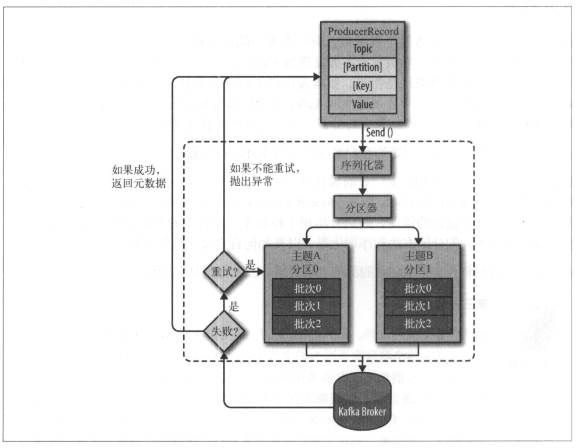
- 我们从创建一个
ProducerRecord对象开始,ProducerRecord对象需要包含目标主题和要发送的内容。我们还可以指定 键 或 分区 。在发送ProducerRecord对象时,生产者要先把 键 和 值对象序列化成字节数组,这样它们才能够在网络上传输。 - 接下来,数据被传给分区器。
- 如果之前在
ProducerRecord对象里指定了分区,那么分区器就不会再做任何事情,直接把指定的分区返回。 - 如果没有指定分区 ,那么分区器会根据
ProducerRecord对象的键来选择一个分区 。
选好分区以后 ,生产者就知道该往哪个主题和分区发送这条记录了。
- 紧接着,这条记录被 添加到一个记录批次 里,这个批次里的所有消息会被发送到相同的主题和分区上。
- 有一个独立的线程负责 把这些记录批次发送到相应的broker 上 。
- 服务器在收到这些消息时会返回一个响应。
- 如果消息 成功 写入 Kafka ,就返回 一 个
RecordMetaData对象,它包含了主题和分区信息,以及记录在分区里的偏移量。 - 如果写入 失败 , 则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败就返回错误信息。
新建 maven 工程,并添加依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>2.7.0</version>
</dependency>
要往 Kafka 写入消息,首先要创建一个生产者对象,并设置一些属性。
生产者可配置项,请参考 org.apache.kafka.clients.producer.ProducerConfig
public class ProducerConfig extends AbstractConfig {
private static final ConfigDef CONFIG;
public static final String BOOTSTRAP_SERVERS_CONFIG = "bootstrap.servers";
public static final String CLIENT_DNS_LOOKUP_CONFIG = "client.dns.lookup";
public static final String METADATA_MAX_AGE_CONFIG = "metadata.max.age.ms";
private static final String METADATA_MAX_AGE_DOC = "The period of time in milliseconds after which we force a refresh of metadata even if we haven't seen any partition leadership changes to proactively discover any new brokers or partitions.";
public static final String METADATA_MAX_IDLE_CONFIG = "metadata.max.idle.ms";
private static final String METADATA_MAX_IDLE_DOC = "Controls how long the producer will cache metadata for a topic that's idle. If the elapsed time since a topic was last produced to exceeds the metadata idle duration, then the topic's metadata is forgotten and the next access to it will force a metadata fetch request.";
...
...
}
2.2 3个必选属性
-
bootstrap.servers
该属性指定 broker 的地址清单,地址的格式为 host:port。清单里不需要包含所有的broker 地址,生产者会从给定的 broker 里查找到其他 broker 的信息。不过建议至少要提供两个 broker 的信息, 一旦其中一个宕机,生产者仍然能够连接到集群上。 -
key.serializer
broker 希望接收到的消息的键和值都是字节数组。 key.serializer 必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer接口的类,生产者会使用这个类把键对象序列化成字节数组。 Kafka 客户端默认提供了ByteArraySerializer、StringSerializer和IntegerSerializer,要注意,key.serializer是必须设置的,就算你打算只发送值内容。 -
value.serializer
与key.serializer一样,value.serializer指定的类会将值序列化。
下面的代码片段演示了如何创建一个新的生产者,这里只指定了必要的属性,其他使用默认设置。
Properties p = new Properties();
// 定义 Kafka 生产者有 3个必选的属性
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "docker01:9092");// broker 的地址清单
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//创建生产者
Producer<String, String> pd = new KafkaProducer<>(p);
- 新建一个 Properties 对象。
- 使用内置的 StringSerializer作为键和值的序列化器 。
- 创建一个新的生产者对象,并为键和值设置了恰当的类型,然后把 Properties 对象传给它。
2.3 发送消息。
-
发送并忘记
我们把消息发送给服务器,但并不关心它是否正常到达。大多数情况下,消息会正常到达,因为 Kafka 是高可用的,而且生产者会自动尝试重发。不过,使用这种方式有时候也会丢失一些消息。 -
同步发送
我们使用 send() 方法 发送消息 , 它会返回一个 Future 对象,调用 get() 方法进行等待 ,就可以知道消息是否发送成功。 -
异步发送
我们调用 send() 方法,并指定一个回调函数, 服务器在返回响应时调用该函数。
在下面的几个例子中 , 我们会介绍如何使用上述几种方式来发送消息。
3 发送消息到 Kafka
3.1 发送并忘记(fire-and-forget)
发送并忘记:
Properties p = new Properties();
// 定义 Kafka 生产者有 3个必选的属性
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "docker01:9092");// broker 的地址清单
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//创建生产者
Producer<String, String> pd = new KafkaProducer<>(p);
//定义一个消息,指定 topic、key、value
// key可以设置,也可以不设置
// 如果主题不存在,默认情况下 server.properties 中 auto.create.topics.enable为true,会自动创建主题
ProducerRecord<String, String> rec = new ProducerRecord<>("test", "SendAndForgetKey", "SendAndForgetMsg1");
// 发送并忘记
// send() 方法会返回一个包含 RecordMetadata 的 Future 对象,
// 不过因为我们会忽略返回值,所以无法知道消息是否发送成功。如果不关心发送结果,那么可以使用这种发送方式
pd.send(rec);
-
生产者的 send() 方法将 ProducerRecord 对象作为参数,所以我们要先创建一个 ProducerRecord 对象。 ProducerRecord 有多个构造函数,这里使用其中一个构造函数,它需要目标主题的名字和要发送的键和值对象,它们都是字符串。
-
我们使用生产者的 send() 方法发送 ProducerRecord 对象。从生产者的架构图里可以看到,消息先是被放进缓冲区,然后使用单独的线程发送到服务器端。
send() 方法会返回一个包含 RecordMetadata 的 Future 对象,不过因为我们会忽略返回值,所以无法知道消息是否发送成功。如果不关心发送结果,那么可以使用这种发送方式。比如,记录不太重要的应用程序日志。
3.2 同步发送消息
同步发送消息:
Properties p = new Properties();
// 定义 Kafka 生产者有 3个必选的属性
p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "docker01:9092");// broker 的地址清单
p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//创建生产者
Producer<String, String> pd = new KafkaProducer<>(p);
//定义一个消息,指定 topic、key、value
// key可以设置,也可以不设置
// 如果主题不存在,默认情况下 server.properties 中 auto.create.topics.enable为true,会自动创建主题
ProducerRecord<String, String> rec = new ProducerRecord<>("test", "syncKey", "syncMsg1");
// 同步发送,并等待响应
try {
// RecordMetaData包含了主题和分区信息,以及记录在分区里的偏移量
RecordMetadata recordMetadata = pd.send(rec).get();
System.out.println(recordMetadata.topic() + "--" + recordMetadata.partition() + "---" + recordMetadata.offset());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
在这里, Producer.send() 方法先返回一个 Future 对象,然后调用 Future 对象的 get() 方法等待 Kafka 响应。如果服务器返回错误, get() 方法会抛出异常。如果没有发生错误,我们会得到一个 RecordMetadata 对象,可以用它获取消息的偏移量。
运行结果:
test--0---1
3.3 异步发送消息
同步发送消息中 Kafka会把目标主题、分区信息和消息的偏移量发送回来,但对于发送端的应用程序来说不是必需的,不过在遇到消息发送失败时,我们需要抛出异常、记录错误日志,这时我们可以使用异步发送消息方式,在异步发送消息方式中生产者提供了回调支持,可以在回调中处理异常。
异步发送消息:
// 异步发送回调
class MyCallback implements Callback {
public void onCompletion(RecordMetadata recordMetadata, Exception exception) {
if (exception != null)//发送失败
exception.printStackTrace();
else {//发生成功
System.out.println("Message posted call back success");
System.out.println(recordMetadata.topic() + "--" + recordMetadata.partition() + "---" + recordMetadata.offset());
}
}
}
// 异步发送,并设置回调
pd.send(rec, new MyCallback());
pd.close();
为了使用回调,需要一个实现了 org.apache.kafka.clients.producer.Callback 接口的类,在回调方法中,如果发送成功则得到一个 RecordMetadata 对象和 发送失败则得到一个Exception 信息。
运行结果:
Message posted call back success
test--0---2
4. 生产者的配置
生产者还有很多可配置的参数,在 Kafka 文档里都有说明,它们大部分都有合理的默认值,所以没有必要去修改它们 。不过有几个参数在内存使用、性能和可靠性方面对生产者影响比较大。
4.1. acks 有多少个分区副本收到消息,生产者才会认为消息写入是成功的
这个参数对消息丢失的可能性有重要影响。 该参数有如下选项。
- 如果
acks=0, 生产者在成功写入消息之前 不会等待任何来自服务器的响应 。这种模式下,因为生产者不需要等待服务器的响应,发送速度最快,吞吐量最高,但是如果出现了问题,导致服务器没有收到消息,那么生产者就无从得知,消息也就丢失了。 - 如果
acks=1,只要集群的 首领节点 收到消息,生产者就会收到一个来自服务器的成功响应。如果首领节点崩溃,新的首领还没有被选举出来,生产者会收到一个错误响应,为了避免数据丢失,生产者会重发消息。不过,如果一个没有收到消息的节点成为新首领,消息还是会丢失。 - 如果
acks=all, 只有当所有同步副本全部收到消息时,生产者才会收到一个来自服务器的成功响应 。这种模式是 最安全的 ,不过,它的 延迟比 acks=1 时更高 ,因为我们要等待不只一个服务器节点接收消息。
4.2. buffer.memory 生产者内存缓冲区的大小
该参数用来设置生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。如果应用程序发送消息的速度超过发送到服务器的速度,会导致生产者空间不足。这个时候,send() 方法调用取决于如何设置 max.block.ms参数,表示在抛出异常之前可以阻塞一段时间。
4.3. compression.type 消息的压缩算法
默认情况下是 none,消息发送时不会被压缩。 该参数可以设置为 none, gzip, snappy, lz4, zstd 。
snappy占用较少的 CPU ,却能提供较好的性能和相当可观的压缩比,如果比较关注性能和网络带宽,可以使用这种算法。gzip一般会占用较多的CPU,但会提供更高的压缩比,如果网络带宽比较有限,可以使用这种算法。使用压缩可以降低网络传输开销和存储开销。
4.4. retries 重试次数
生产者从服务器收到的错误有可能是临时性的错误(比如分区找不到首领),生产者可以重发消息 ,如果达到次数 retries,生产者会放弃重试并返回错误。
默认情况下,生产者会在每次重试之间等待 100 ms ,不过可以通过 retry.backoff.ms 参数来改变这个时间间隔。一般情况下,因为生产者会自动进行重试,所以就没必要在代码逻辑里处理那些可重试的错误。
4.5. batch.size 批次大小,按照字节数计算
发送到同一个分区的消息,生产者会把它们放在同一个批次里。
4.6. linger.ms 发送批次之前等待更多消息加入批次的时间
生产者会在批次 填满 batch.size 或 linger.ms 达到上限时把批次发送出去。默认情况下,只要有可用的线程, 生产者就会把消息发送出去,就算批次里只有一个消息。
4.7. max.in.flight.requests.per.connection 在收到服务器响应之前可以发送多少个消息
它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为 1 可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。
4.8. timeout.ms 、request.timeout.ms 和 metadata.fetch.timeout.ms
request.timeout.ms 在发送数据时等待服务器返回响应的时间,metadata.fetch.timeout.ms 在获取元数据(比如目标分区的首领是谁)时等待服务器返回响应的时间。如果等待响应超时,那么生产者要么重试发送数据,要么返回一个错误(抛出异常或执行回调)。timeout.ms 指定了 broker 等待同步副本返回消息确认的时间,与 asks 的配置相匹配一一如果在指定时间内没有收到同步副本的确认,那么 broker 就会返回一个错误。
4.9. max.block.ms 缓冲区满时的最大阻塞时间
在调用 send() 方法或使用 partitionFor() 方能获取元数据时,如果当生产者的发送缓冲区已满,或者没有可用的元数据时,这些方法就会阻塞。在阻塞时间达到 max.block.ms 时,生产者会抛出超时异常。
4.10 . max.request.size 单个请求里所有消息总的大小
broker 对可接收的消息最大值也有自己的限制(message.max.bytes),max.request.size 和 message.max.bytes 的配置最好可以匹配,避免生产者发送的消息被 broker 拒绝。
5 顺序保证
如果把 retries 设为非零整数,同时把 max.in.flight.requests.per.connection设为比 1 大的数,那么,如果第一个批次消息写入失败,而第二个批次写入成功, broker 会重试写入第一个批次。如果此时第一个批次也写入成功,那么两个批次的顺序就反过来了。
一般来说,如果某些场景要求消息是有序的,那么消息是否写入成功也是很关键的,所以不建议把 retries 设为 0 。可以把 max.in.flight.requests.per.connection 设为 1 ,这样在生产者尝试发送第一批消息时,就不会有其他的消息发送给 broker 。不过这样会严重影响生产者的吞吐量 ,所以只有在对消息的顺序有严格要求的情况下才能这么做。
6 键和分区
在之前的例子里,ProducerRecord 对象包含了目标主题、键和值。 Kafka 的消息是一个个键值对, ProducerRecord 对象可以只包含目标主题和值,键可以设置为默认的 null ,不过大多数应用程序会用到键。
键有两个用途 :
- 可以作为消息的附加信息,
- 也可以用来决定消息该被写到主题的哪个分区。拥有相同键的消息将被写到同一个分区。
也就是说,如果一个进程只从一个主题的分区读取数据,那么具有相同键的所有记录都会被该进程读取。
要创建一个包含键值的记录,只需像下面这样创建 ProducerRecord 对象:
ProducerRecord<String, String> rec = new ProducerRecord<>("test", "key", "value");
如果要创建键为 null 的消息,不指定键就可以了:
ProducerRecord<String, String> rec = new ProducerRecord<>("test", "value");
这里的键被设为 null 。
- 如果键值为 null , 并且使用了默认的分区器,那么记录将被随机地发送到主题内各个可用的分区上。分区器使用 轮询(Round Robin )算法 将消息均衡地分布到各个分区上。
- 如果键不为空,并且使用了默认的分区器,那么 Kafka 会 对键进行散列(使用 Kafka 自己的散列算法,即使升级 Java 版本,散列值也不会发生变化),然后根据散列值把消息映射到特定的分区上。这里的关键之处在于 ,同一个键总是被映射到同一个分区上 ,所以在进行映射时,我们会使用主题所有的分区,而不仅仅是可用的分区 。这也意味着,如果写入数据的分区是不可用的,那么就会发生错误。但这种情况很少发生。
只有在不改变主题分区数量的情况下,键与分区之间的映射才能保持不变。
举个例子,在分区数量保持不变的情况下,可以保证用户 045189 的记录总是被写到分区 34 。不过,一旦主题增加了新的分区,这些就无法保证了——旧数据仍然留在分区 34 ,但新的记录可能被写到其他分区上。 如果要使用键来映射分区,那么最好在创建主题的时候就把分区规划好,而且永远不要增加新分区。
代码:
github.com/wengxingxia/004Kafka.git
共同学习,写下你的评论
评论加载中...
作者其他优质文章


