
项目场景:
近些时间,在和老师做关于基于深度学习的医学影像的语义分割实验,但在模型训练的过程中发现了模型无法收敛的问题,为了解决这个问题,真可谓焦头烂额,每天爆肝,为了使得其他热爱深度学习的小伙伴在训练模型的过程中也出现这种错误,所以在此想跟大家填一下坑,发现模型不收敛后应该做的几件事,一定要按顺序来

上图是不是很契合你在查找模型不收敛的问题时的情况
代码分析:
如果训练中发现模型不收敛,首先第一件事要考虑的就是你的代码在编写过程中是否有不合理的地方,而这种不合理不是指代码有bug,而是指你的代码在逻辑方面出现了问题,比如,在模型的反向传播过程中,梯度无法进行传播,,更比如,在源码中没有加上梯度更新,导致梯度不发生变化等等,这些都是值得考虑的,都是要检查的地方,每一个细节都要考虑到位

数据分析:
人工智能发展至今,用在各个领域的神经网络模型层出不穷,然而,训练一个神经网络最关键的就是数据,没有输入,何来的输出呢对吧,然而,在将代码方面的逻辑问题排除后,就应该去检查数据问题,你的数据是否存在有原始数据跟目标对不上的情况,由于在制作数据的时候都是人工进行的,所以导致很多时候会有些差错是难免,或者是数据中插入了一些其他的不相干的数据,比如你是要分割一种牵牛花的图像,而在数据中不小心存在了玫瑰花的图像,这个会对训练也会造成影响,所以数据的预处理的分析,是一个重中之重
超参数的设置:
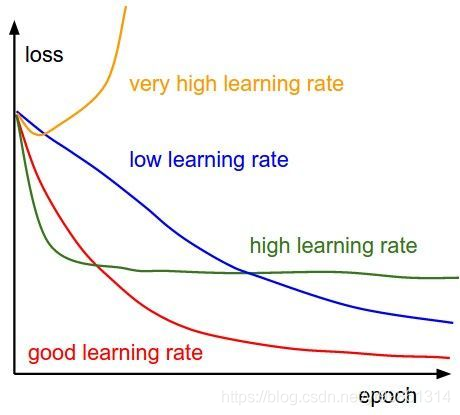
如果以上两点都没有问题,那接下来就是超参数的设置了,其中,学习率以及batch_size和epoch的次数设置都尤为重要,或者甚至是说损失函数还有梯度下降算法中的一些超参数设置,都是值得注意的,但大部分情况都应该将注意力首先考虑在学习率以及batch_size和epoch上,首先可以去考虑去试试学习率的改变,是否需要插手学习率优化策略或者是梯度裁剪,这些都是可以去尝试的,学习率的尝试,最好是从大到小,从0.01开始,往下依次试,最好是0.01,0.005,0.001,0.0005,0.0001以这样的规律去尝试,但不要以为0.0001往后就不去试了,这个谁都说不准的,但有人会说,数据量太大了,每次这样训练岂不是很浪费时间吗,是的,全部都来尝试肯定是不行的,时间上耗费太久,在这里,我建可以采用小样本数据集先去进行尝试,如果小样本上可以收敛,比方说在设置为0.001发现不收敛,设置为0.0005竟然收敛了,那么就以0.0005为中心向两边去进行小量的变化去尝试看效果怎么样,batch_size以及epoch的话和上面的学习率的调整方法是一样的。大家可以都去尝试一下。
算法分析:
好了,如果说以上的情况都进行了检查以及实验,那么最后一步那就应该考虑是否是自己选择的梯度下降算法或者损失函数不正确导致的模型不收敛,这个是值得去考虑的,尤其是在正负标签不平衡的情况下,采用什么损失函数去训练,什么梯度下降算法比较契合我们的数据,或者是否是梯度爆炸或者梯度消失,这些都是要去考虑的,这一块的分析显得尤为重要。
————————————————
版权声明:本文为CSDN博主「热爱DL的全国顶尖学渣」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yr99861314/article/details/115835641
共同学习,写下你的评论
评论加载中...
作者其他优质文章



