
关于前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容中的一个知识点-上采样。
一、基于unet神经网络上采样中的的三种方式的理解
1.上采样的三种方式
在网上查阅大量资料后,以下是结合unet,对于上采样的三种方式的理解,上采样的三种方式,可以分为1、插值法(最近零插值算法,双线性插值算法,双三次插值算法),2、反池化,3、转置卷积(可学习)。
其中转置卷积是主要讨论内容。
2.转置卷积的主要定义
转置卷积,顾名思义是也是一个卷积操作,其与普通卷积的不同点在于普通卷积根据padding,来进行图片的特征提取,也就是对图片大小进行特征化处理,当然,在图片进行完卷积后的size会变小或者不变,很少有变大,(我没遇见过)在转置卷积中,也就是对输入的图片通过卷积的方式进行一个放大,在直接卷积过程中,可以将卷积过程看作convolution kernel转换成稀疏矩阵C,将input转换成列向量,得到行向量output,,而转置卷积中转置一词所对应的即是将稀疏矩阵C,通过转置后变成C^T,和output相乘,得到input的size,注意!是size。并不能还原其中的像素值。(这段只是对转置卷积的文字理解,有不理解的可以去看我文章最下面备注的参考资料)
3.转置神经的一些细节问题
在直接卷积中,设input_size = i,output_size= o,kernel_size = k,padding = p,stride = s,相对应的转置卷积过程input_size=i’,output_size = o’,kernel_size = k’,padding=p’,stride=s’
在直接卷积中我们能够知道o=[i + 2 ∗p − ( k − 1 ) ] / s,所以反过来i=os+(k-1)-2p,在转置卷积中尺寸转换公式就为o’=[i’+2∗p’+(k’−1)]/s’,对应起来,就是i’=o*s ,k’=k, p’=-p。S’=1
在进行转置卷积时,他时先将输入进行一个扩大,比如输入时3×3,他先会扩大到5×5,然后通过卷积核错位扫描,将其变成7×7,之后再通过步长消融(p’=-p),最后得到5×5的size
比方o=3,p=1,s=2,k=3,在经过转置卷积后,他的大小会变成i’=5×5,为什么会变成5×5而不是其他大小呢,这个就跟s步长有关系,这个步长stride并不是之前所说的转置卷积中扩大图像后进行的错位扫描的步长时一个性质,错位扫描中的步长始终时1,这个stride步长,仅仅只是i->o时的卷积操作的步长,这个步长只跟o->i’这个过程中图片的放大有关系,它是根据步数S对输入的内部进行填充,这里可以理解成输入放大的倍数,即在的每个元素之间填充的个数与步长之间的关系为N=S’-1,所以回到之前所说的i’=3,p’=1,s’=2,k’=3,因为步长s’=2,所以i’首先会被扩充到size=5×5,但因为之前有一个公式,i’=o×s,在这里,按照公式所说,i’应该是等于6的,但为什么不等于6而等于5,这里可以先得到一个由i’=o×s的修改,i’=(o-1)*s+1,这个在结尾说。
在此,我们先把i’=5,k=k’=3,p’=-p,这里的-p是指padding消融,之前的padding都是增加一圈像素值,这里的-p则是消去一圈像素值,步长这里已经通过s’=2将图像扩大到了55,之后由33的convolution kernel对图像进行错位扫描,得到一个77的大小的扩大后的特征图,但由于之前所说,p’=-p的,所以他会消融一圈,将size变成了5×5,所以最终的结果就是为5×5的size,将这个过程放在unet上,在上采样过程中*,他的input需要变大一倍,*所以s=2,而这里需要注意的是,unet中所要求的是扩大一倍,所以这里我们需要将converlution kernel的大小变为2×2,(在此默认输入的通道数都为1),这样才能是图片的大小刚好放大一倍,而之前所说的i和o这个只是用来进行对比,也就是通过对比得出公式,以此来进行对比,当然,既然是转置卷积,他是可以通过直接卷积的结果来进行转置卷积得出直接卷机的输入的‘大小’,这里注意,仅仅只是还原大小,像素值并不能还原,当然,这是对于转置卷积的转换的一种理解方法,还有另一种方法去理解,在此文就不再进行讲解,这里只说明另一种理解方法的一个转换公式H’=(H-1)stride-2padding+kernel size,宽度W也是一样的,这两种理解方式都行都是换汤不换药,只是一些细节上的处理,变换一下就是一样的思路了关于另一种理解方法的文章我就放在文章最后的链接处有,但其实只需要知道函数怎样使用就行了,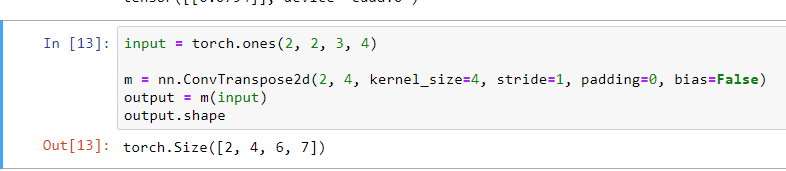
就比如这个pytorch中的转置卷积函数,前面的也就是通道数的变化了,后面kernel size为4,而padding是指直接卷积中的padding为0,所以不进行消融,stride为1,也不用扩大,直接进行错位扫描,即可以得到结果
4.转置神经在unet中的应用
而在unet中,在上采样部分的输入,他是上一层的卷积部分的输出,而卷积部分的输入的size跟上采样之后的size并不是一样的,因为这时的上采样是增大两倍,而不是还原直接卷积部分的输入的大小,所以最终得到的这是卷积输出的两倍size的特征图,这是在uent中的一个网络结构的一个过程说明。
再回到之前的转置卷积过程,有一个问题,就是为什么i’=5×5,而不是o×s=6×6,(o=3),因为在上采样的时候,他会经过以下三个步骤,1、resize input and insertion,2、dislocation scanning,3、melted padding,从而得到最终的output,我们的问题也就是在步骤一后的结果为什么是5×5而不是6×6,在上采样的 步骤1时他会有一个input的判断公式,[i’+2∗p’−(k’−1)]%s’!=0,因为此时的i’是5×5的话在代入公式中(p’=1,k’=3,s’=2),他最后的值不为1,所以他会让size=5×5继续padding,将其变成6×6,他会在input的外层补上半圈为0的像素值,再进行卷积,当然,最后得到的大小也会是6×6,这里有一点,按照运算推出,确实结果是6,再将其通过s=2,p=1,k=3×3将其直接卷积,最后的结果如果采用的是valid的方法,最后的值确实是3,也就是转置卷积的输入的size,但如果采用的是same,最后的处理的出来的size却会是4×4,当然,我们用5 ×5最后得出来的却同样也是3×3,不需要考虑valid或是same,这个也更符合我么对于卷积的输入输出的size的感觉,所以,input的size如果是3×3,计算机他会有两个解,5×5或6×6,计算机他会优先选择小的size,所以会选择5×5进行input,所以i’=o×s,可以改成i’=(o-1)*s+1。
Ps:对于为什么计算机需要这样做,这也是我也没有理解的,但这个问题不大,只需要知道 i’=(o-1)*s+1 就好了,对于unet的网络结构中上采样部分,我们需要上采样增大两倍,所以convolution kernel’s size=2,stride=2。以上就是对unet神经网络中的上采样部分的一个理解。
有不对的希望指出,谢谢
参考资料:
1、https://blog.csdn.net/w55100/article/details/106467776
2、https://zhuanlan.zhihu.com/p/48501100
版权声明:本文为CSDN博主「热爱DL的全国顶尖学渣」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yr99861314/article/details/113607849
共同学习,写下你的评论
评论加载中...
作者其他优质文章



