
Hadoop文件安装时的问题
- 在Hadoop安装时,要配置JAVA环境变量,注意要下载与之后操作相对应的版本,否则会出现很多问题。
- 下载Hadoop文件,注意要如同1一样,要下载与JAVA版本相对于的版本,否则会出现不可以调用的问题。
Hadoop伪分布式时的问题
1.<configuration> </configuration>
按照安装教程进行伪分布式配置的修改配置文件时,要注意<configuration> </configuration>这个标签只有一个,而原文件中以有这个标签,只需将教程中的其他内容复制到里面就行了,否则将会如下的错误报告。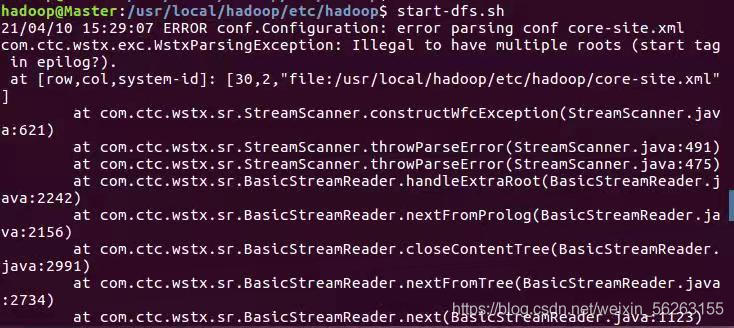
其次,在修改配置文件中如果不是复制内容,而是手打的话,就需要完完全全按照教程中输入相应代码。以下是容易打错的地方:1.data >>> date 2.**<property> </property>**每一段的完成都需要有这样的格式3.**<name></name>**也是如此 4.`也是如此。
Hadoop集群配置时出现的常见问题
为方便起见,我们可以对先前的hadoop虚拟机进行复制,克隆出两个相同的虚拟机,来作为Master节点和Slave节点。但要注意两者要有用不同的MAC地址,同时要修改sudo vim /etc/hostname中的主机名,改为Master和Slave。在进行集群配置的时候,要注意将两个节点(Master和Slave)两个虚拟机同时打开,两者才能互通,这是最基本的前提。
在配置集群环境的时候,如修改配置core-site.xml文件的时候,也要注意Hadoop伪分布式出现的相关问题。
最容易但也很简单出现的问题(我因此忽略这个小细节,调试了很多时间在其他没有错误的地方,浪费了很多时间):slaves文件的配置,注意在集群配置中,这个文件中只需要留存一个主机名,将Master节点中的slaves文件里面的内容改为Slave,这样才能将数据节点赋予Slave节点,让其拥有datanode,否则如下图的情况。
在集群配置时,可能会因为一些原因,而多次使用hdfs namenode -format 多次初始化会让Slave节点启动datanode失败,因为多次初始化,使得Namenode会产生新的clusterid,导致与datanode上的culsterid不一致,使得Slave节点启动datanode失败。对此我采用了两种方法去解决:1 .删除hadoop目录下的data和logs文件夹,重新初始化。 2. 找到Slave节点上的clusterid和Master上的clusterid,将Slave节点上的clusterid改成与Master上的一致即可。
这些就是我在使用hadoop时出现的常见问题。
————————————————
版权声明:本文为CSDN博主「HHHH756」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_56263155/article/details/115818387
共同学习,写下你的评论
评论加载中...
作者其他优质文章



