
混合云下的 Kubernetes 多集群管理与应用部署
本文是上海站 Meetup 中讲师李宇根据其分享内容梳理成的文章
大家好,很高兴来到今天下午的 Meetup。我先简单做个自我介绍,我叫李宇,目前是 KubeSphere 的一名研发,主要负责多集群方向的工作,我今天带来的分享是混合云下的 Kubernetes 多集群管理与应用部署。
KubeSphere 在开始做 v3.0之前,曾发起了一个社区用户调研,发现呼声最高的是支持多集群管理和跨云的应用部署,因此 KubeSphere 3.0 重点支持了多集群管理。
单集群下的 Kubernetes 架构
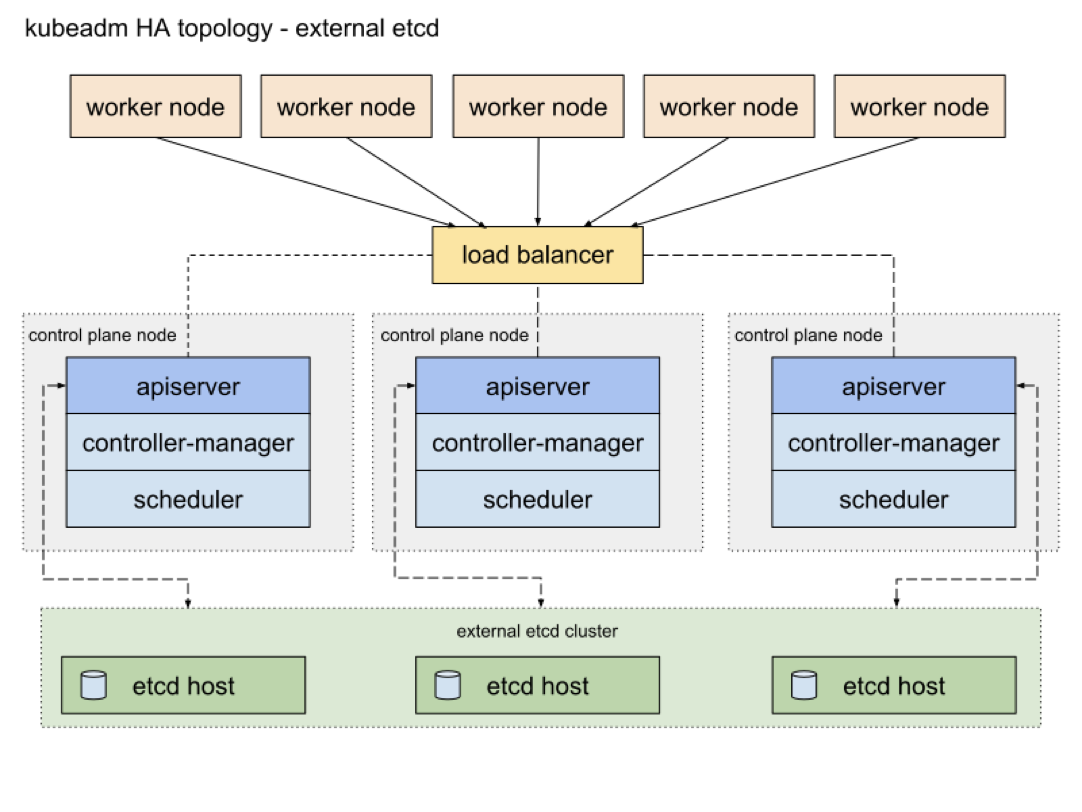
Kubernetes 内部分为 Master 和 Worker 两个角色。Master 上面有 API Server 负责 API 请求,Controller Manager 负责启动多个controller,持续协调声明式的 API 从 spec 到 status 的转换过程,Scheduler 则负责 Pod 的调度,Etcd负责集群数据的存储。Worker 则作为工作节点主要负责 Pod 的启动。
单集群下有许多场景是无法满足企业需求的,主要分为以下几点。
-
物理隔离。尽管 Kubernetes 提供了 ns 级别的隔离,你可以设置每个 Namespace 各自使用的 cpu 内存,甚至可以使用 Network Policy 配置不同 Namespace 的网络连通性,企业仍然需要一个更加彻底的物理隔离环境,以此避免业务之间的互相影响。
-
混合云。混合云场景下,企业希望可以选择多个公有云厂商和私有云解决方案,避免受限于单一云厂商,降低一定成本。
-
应用异地多活。部署业务多个副本到不同 region 集群,避免单个 region 的断电造成应用的不可用情况,实现不把鸡蛋放在同一个篮子目的。
-
开发/测试/生产环境 。为了区分开发测试生产环境,把这些环境部署到不同的集群。
-
可拓展性。提高集群的拓展性,突破单一集群的节点上限。
其实最简单的方式就是使用多个 Kubeconfig 文件来分别管理不同的集群,前端调动多次 API 即可同时部署业务,包括其他一些现有的其他产品也是这么做的,但是 KubeSphere 还是想以一种更加 Cloud Native 的方式去管理多个集群,于是 KubeSphere 先调研了一些已有的解决方案。
总体来说分为两个方向:
第一个是偏向控制层的资源分发,比如 Kubernetes 社区的 Federation v1 和 Federation v2 , Argo CD/Flux CD (流水线中实现应用的分发)
第二个是致力于实现多集群之间的 Pod 网络可达。例如 Cilium Mesh,Istio Multi-Cluster,Linkerd Service Mirroring,由于这些项目同特定的 CNI 以及服务治理组件绑定了,因此接下来我会详细介绍一下 Federation v1 和 Federation v2 两个项目。
Federation v1
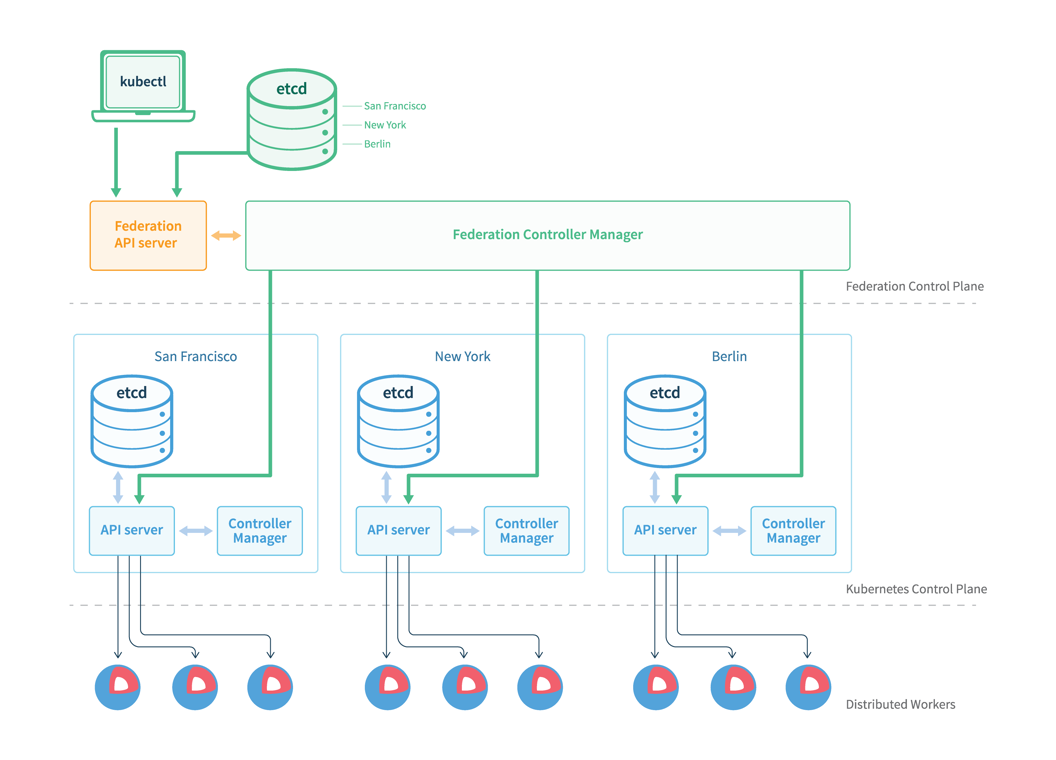
上面是 Federation v1 的架构图 可以看到有额外的 API Server (基于 Kube-Apiserver 开发) 和 Controller Manager (同 Kube-Controller-Manager 类似) ,下面是被管控的集群,多集群的资源分发需要在上面集群创建,然后最终被分发到下面的各个集群去。
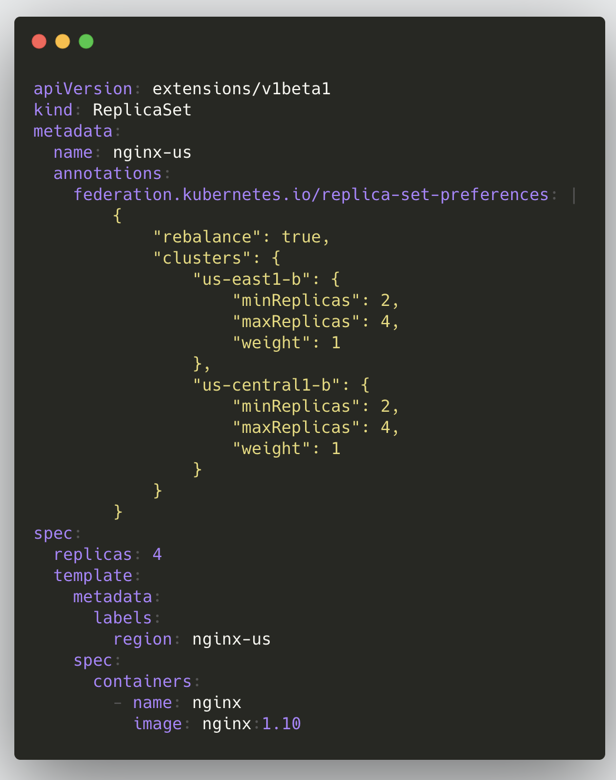
上面是一个 在Federation v1 里面创建 Replicaset 的示例,与普通的 Replicaset 区别就是多了一些 Annotation,里面主要存了一些分发资源的逻辑,从中我们也能看到 v1 的一些缺点。
- 其引入了单独开发的 API Server,带来了额外的维护成本。
- 在 Kubernetes 里一个 API 是通过 Group/Version/Kind 确定的,但是 Federation v1 里面对于K8s 原生 API、GVK 固定,导致对不同版本的集群 API 兼容性很差。
- 设计之初未考虑 RBAC,无法提供跨集群的权限控制
- 基于 Annotation 的资源分发让整个 API 过于臃肿,不够优雅,是最被诟病的一点。
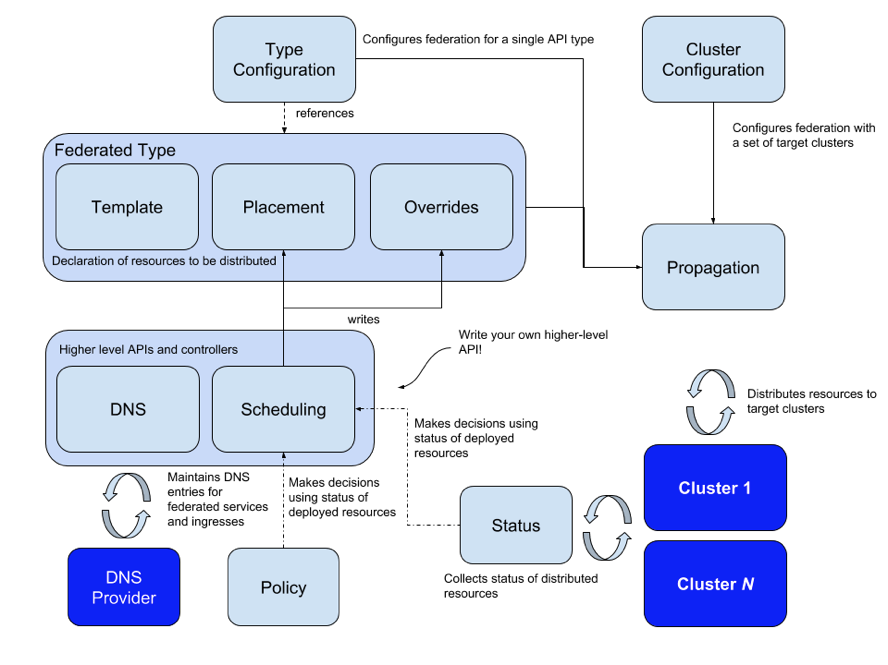
Federation v2
正是由于 v1 的这些缺点,Kubernetes 社区逐渐弃用了 v1 的设计,吸取了 v1 的一些教训,推出了 v2 也就是 Kubefed 这个项目。Kubefed 最大的特点就是基于 CRD 和 Controller 的方式替换掉了 v1 基于Annotation 分发资源的方案,没有侵入原生的 K8s API,也没有引入额外的 API Server。
上面是 v2 的架构图,可以看到一个 CRD 资源主要由 Template、Override、Placement 三部分组成,通过结合 Type Configuration,可以支持多个版本的API,大大提高了集群之间的版本兼容性,并且支持了所有资源的 Federation,包括 CRD 本身。同时 Kubefed 在设计之初也考虑到了多集群的服务发现、调度等。
下面是一个联邦资源的示例,Deployment 在 Kubefed 中对应 FederatedDeployment,其中 spec 里面的 template 就是原来的 Deployment 资源,placement 表示联邦资源需要被下放到哪几个集群去, override 可以通过不同的集群配置不同集群的字段,例如 deployment 的镜像的 tag 各个集群的副本数等。
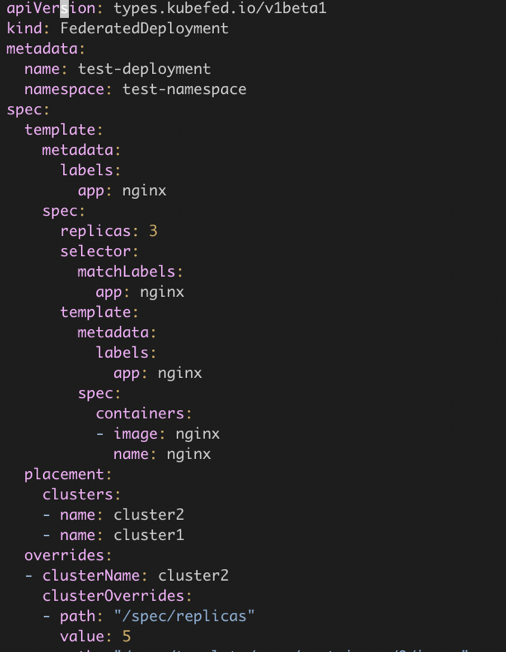
当然 Kubefed 也不是银弹,也有其一定的局限性。从前面可以看到,其 API 定义复杂,容易出错,也只能使用 kubefedctl 加入和解绑集群,没有提供单独的 SDK。再就是它要求控制层集群到管控集群必须网络可达,单集群到多集群需要改造 API,旧版本也不支持联邦资源的状态收集。
KubeShere On Kubefed
接下来我们看看 KubeSphere 基于 Kubefed 如何实现并简化了多集群管理。
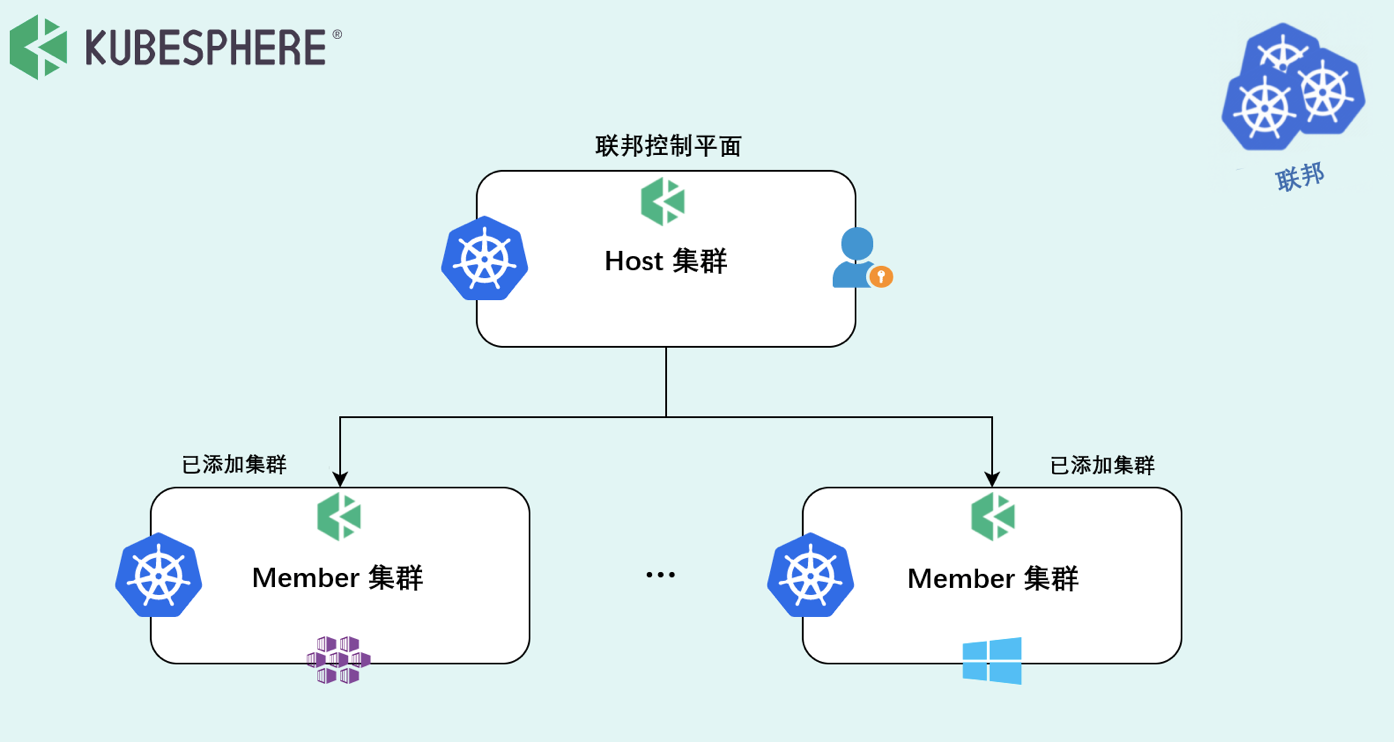
图片里面定义了两个概念,Host 集群指的是装了 Kubefed 的集群,属于 Control Plane,Member 集群指的是被管控集群,Host 集群与 Member 集群之间属于联邦关系。
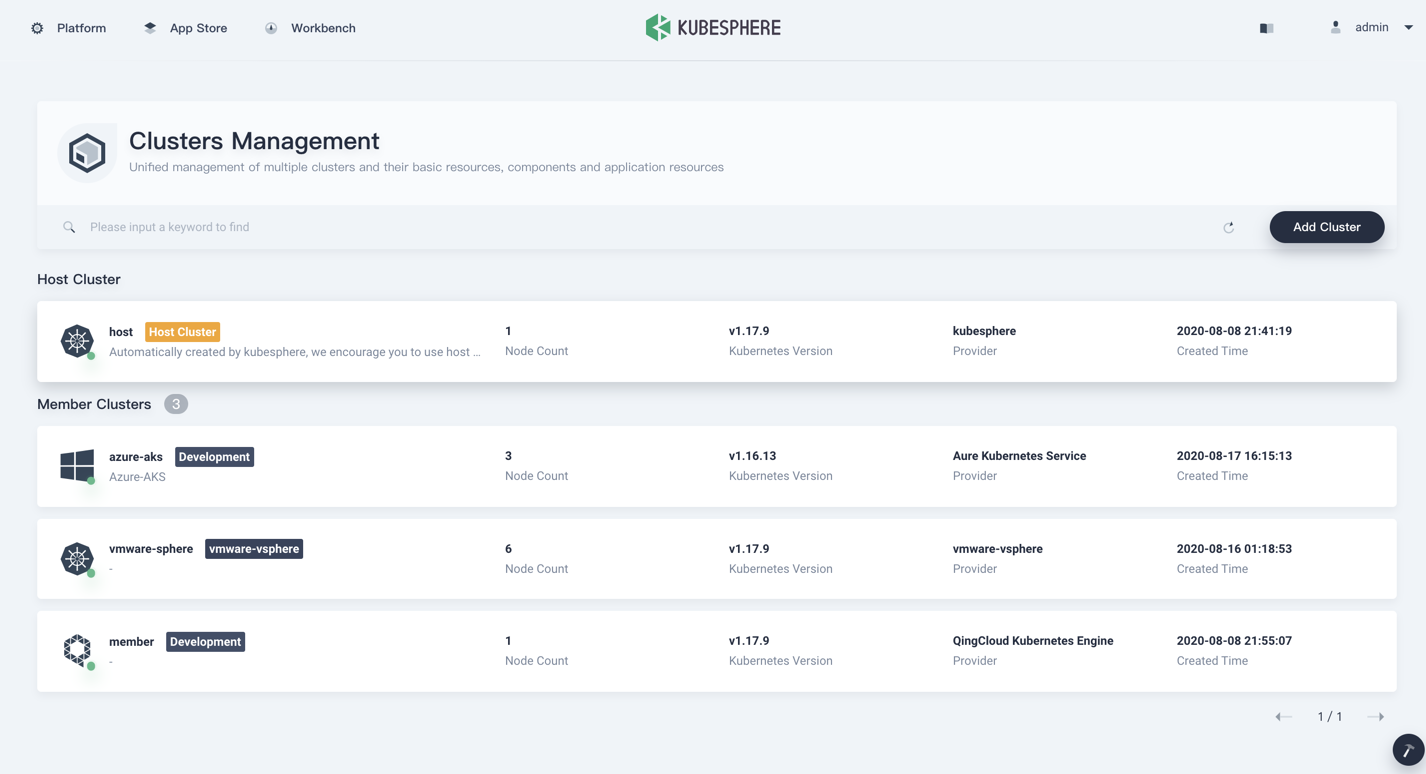
在图片这里用户可以统一管理多个集群,KubeSphere 单独定义了一个 Cluster Object,拓展了 Kubefed 里面的 Cluster 对象,包含了 region zone provider 等信息。
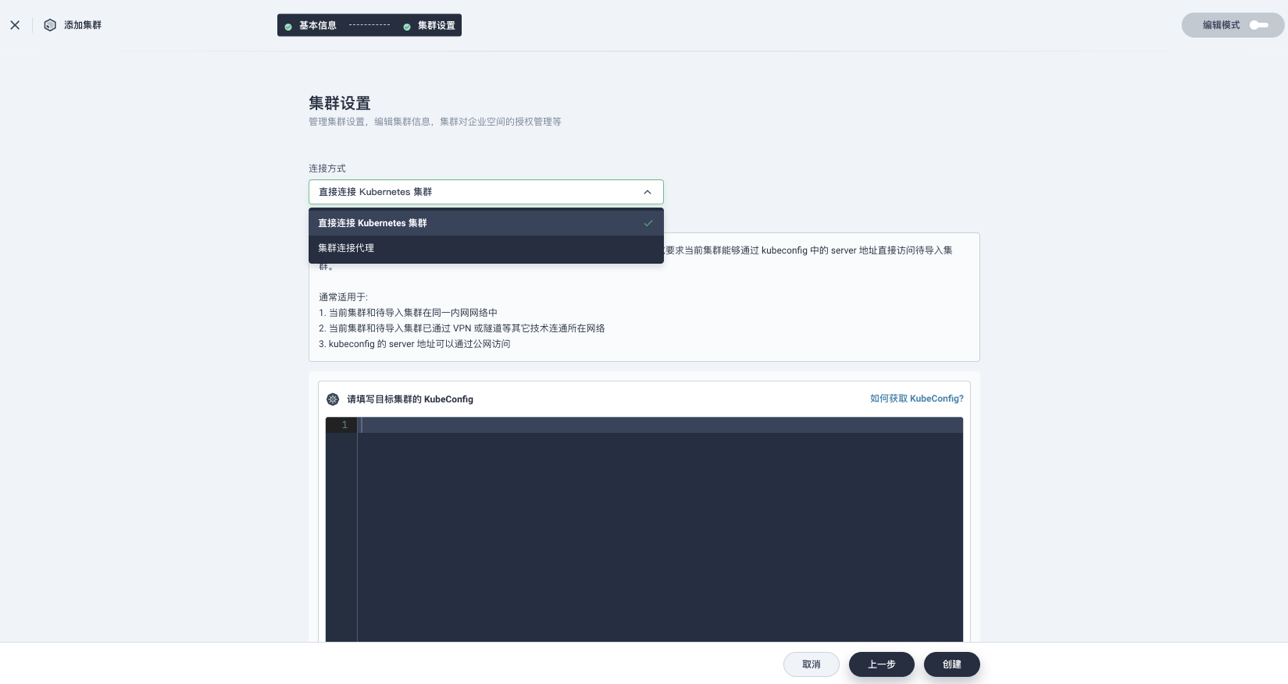
在导入集群的时候 KubeSphere 提供了两种方式:
- 直接连接。这种情况要求 Host 到 Member 集群网络可达,只需要提供一个 kubeconfig 文件可直接把集群加入进来,避免了之前提到的 kubefedctl 的复杂性 。
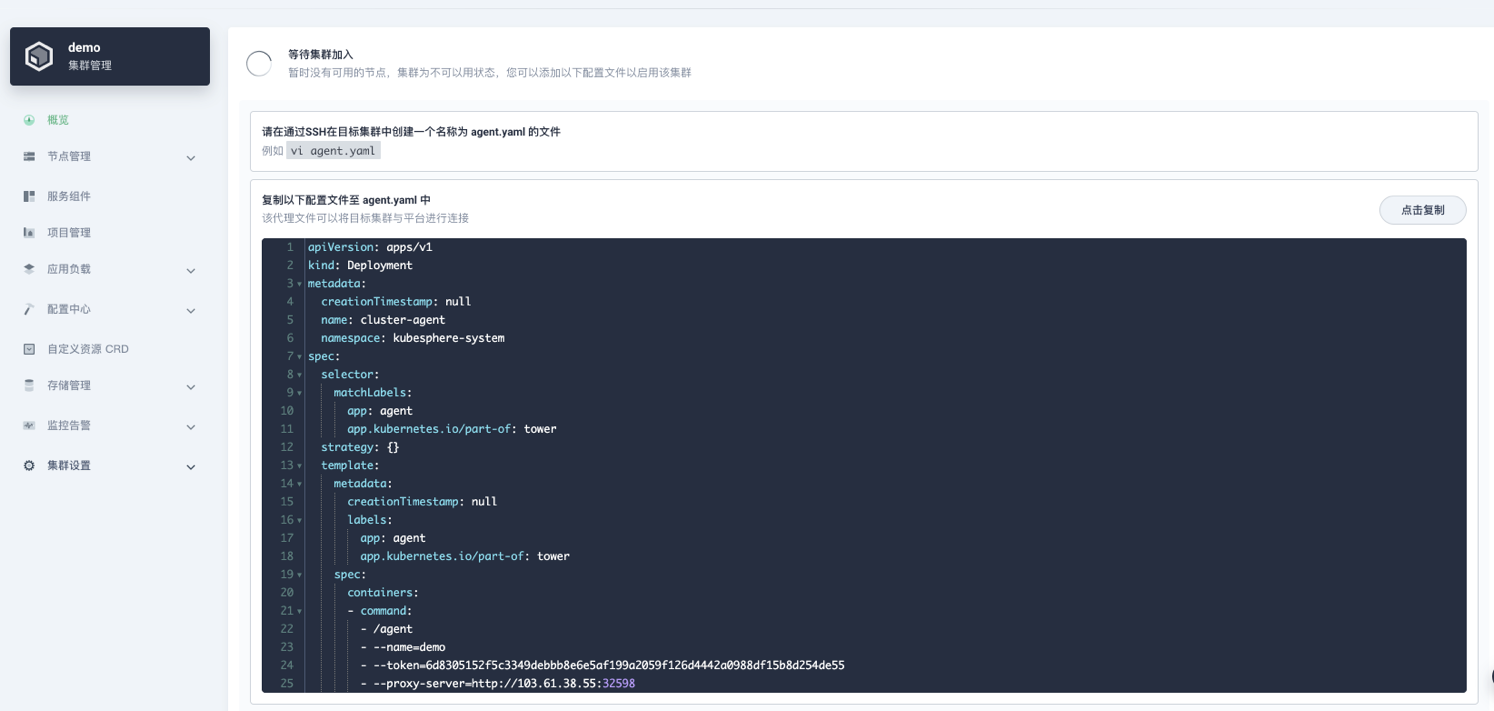
- 代理连接。
对于 Host 集群到 Member 集群网络不可达的情况,目前 Kubefed 还没有办法做到联邦。因此 KubeSphere 基于 chisel 开源了Tower,实现了私有云场景下集群联邦管理,用户只需要在私有集群创建一个 agent 就可以实现集群联邦。
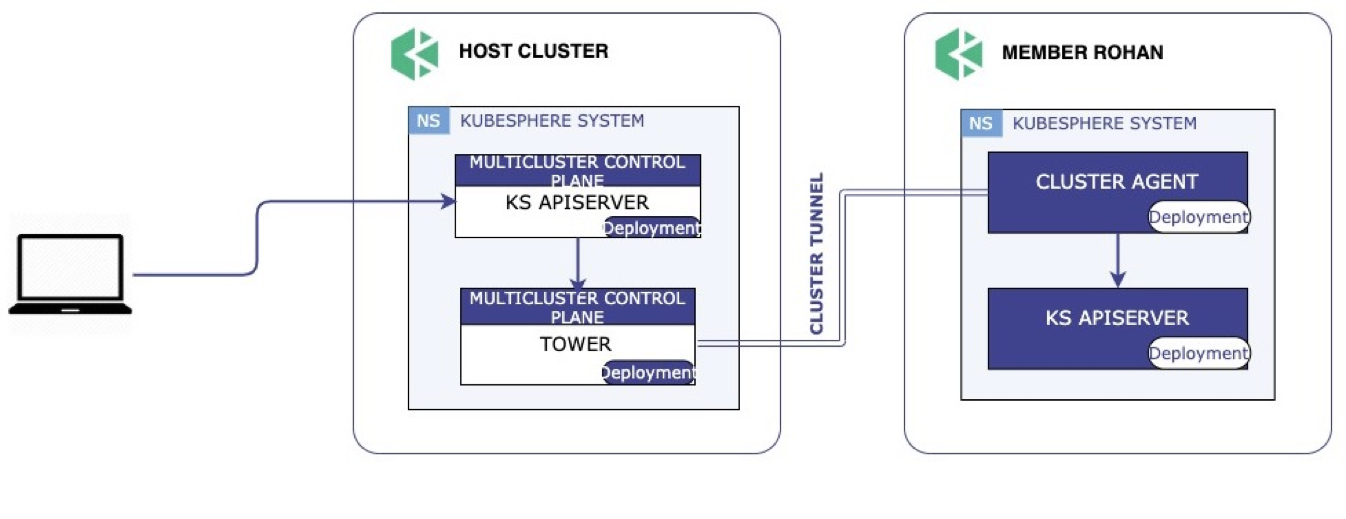
这里展示了 Tower 的工作流程。在 Member 集群内部起了一个 agent 以后,Member 集群会去连接 Host 集群的 Tower Server,Server 收到这个连接请求后会直接监听一个 Controller 预先分配好的端口,建立一个隧道,这样就可以通过这个隧道从 Host 往 Member 集群分发资源。
多集群下的多租户支持
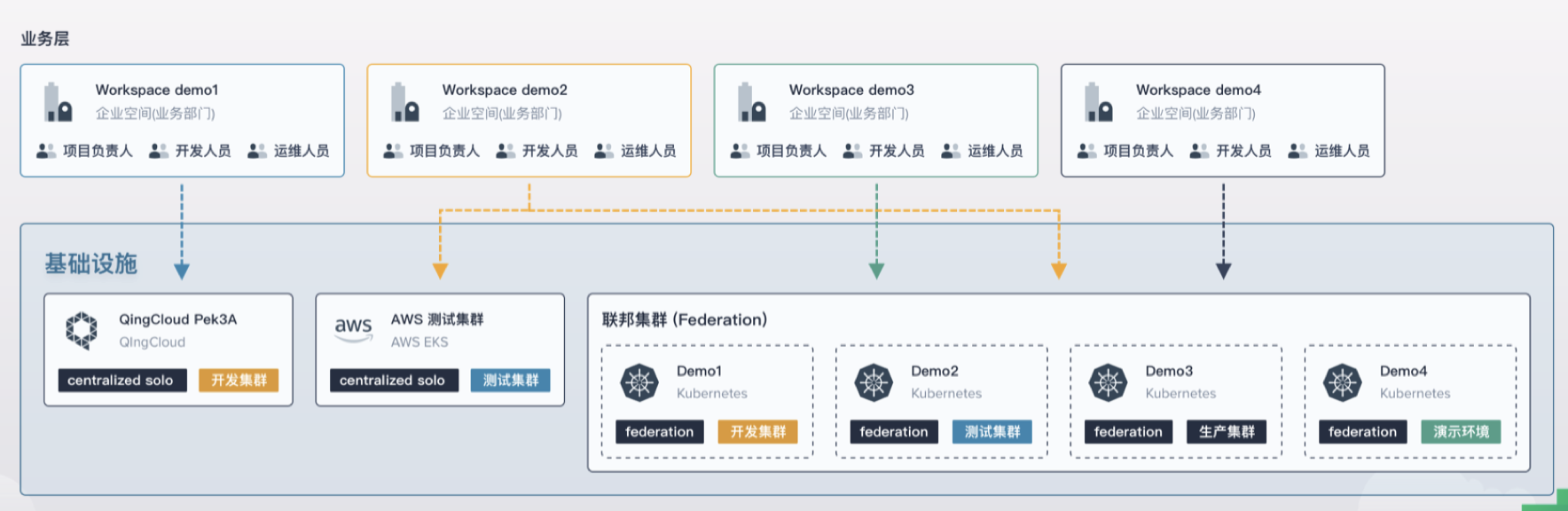
在 KubeSphere 里面,一个租户就是一个 Workspace,并且租户de授权认证都是通过 CRD 来实现的。为了减少 Kubefed 对 Control Plane 的依赖,KubeSphere 把这些 CRD 通过联邦层下放,在 Host 集群收到 API 请求后直接转发到 Member 集群,这样假如 Host 集群挂了,原来的租户信息在 Member 集群仍然存在,用户依然可以登陆 Member 集群的 Console 来部署业务。
多集群下的应用部署
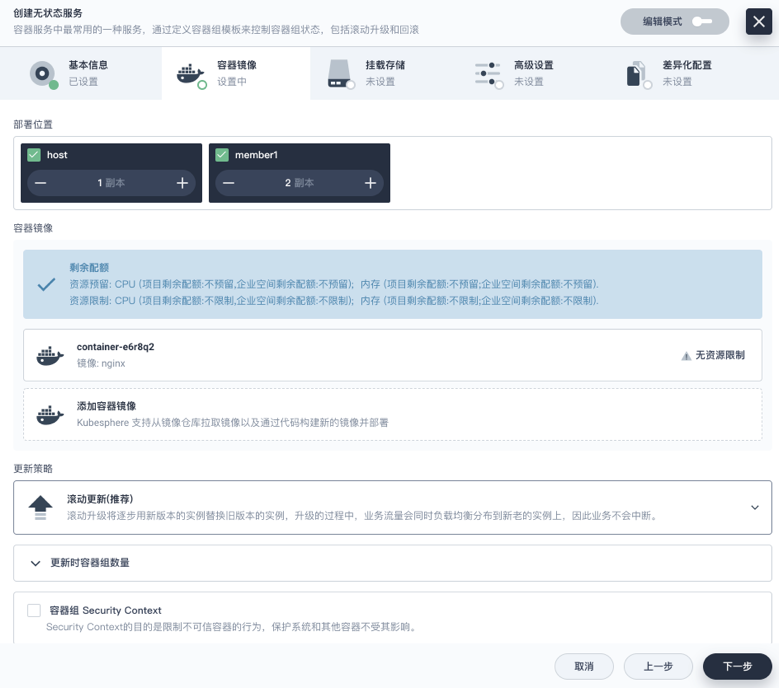
Kubefed 的 API 前面我们也看到过,手动去定义是十分复杂并且容易出错,因此 KubeSphere 在部署应用的时候,可以直接选择需要部署的集群名称以及各自集群的副本数,也可以在差异化配置里面配置不同集群的镜像地址以及环境变量,例如集群 A 位于国内,拉不到 gcr.io 的镜像,就可以配成 DockerHub 的。
联邦资源的状态收集
对于联邦资源的状态收集,前面我们提到 Kubefed 之前是没有实现的。因此 KubeSphere 自研了联邦资源的状态收集,在例如创建 Pod 失败的场景下可以很方便的去排查对应的 event 信息,另外 KubeSphere 也提供了联邦资源的监控,提高了其可观测性。
TODO
尽管 KubeSphere 基于 Kubefed 简化了多集群之间的联邦,未来也仍有一些需要改进的地方。
- 目前中心化的 Control Plane 导致资源分发只能 push,这对 Host 集群高可用有一定要求,这块 Kubefed 社区也在积极开发从 Member 集群 pull 资源到 Host 集群的 feature。
- KubeSphere 是一个非常开放的社区,我们希望有更过的社区用户加入进来,但是目前多集群的开发门槛较高,开发者需要定义一系列很多的 Types CRD,不够友好。
- 多集群的服务发现目前没有比较好的解决方案,这个本来一开始社区是有做的,但是后来为了更快的发 beta 版本,就弃用了。
- 多集群的 Pod 副本数调度,这个目前社区是有提供 RSP (Replica Scheduling Preference),KubeSphere 预计也会在下个版本加进去。
那么,有没有既不引入中心化的 Control Plane,又能够减少过多的 API 引入实现多集群呢。答案就是 Liqo。在介绍它之前,首先我们介绍一下 Virtual Kubelet。
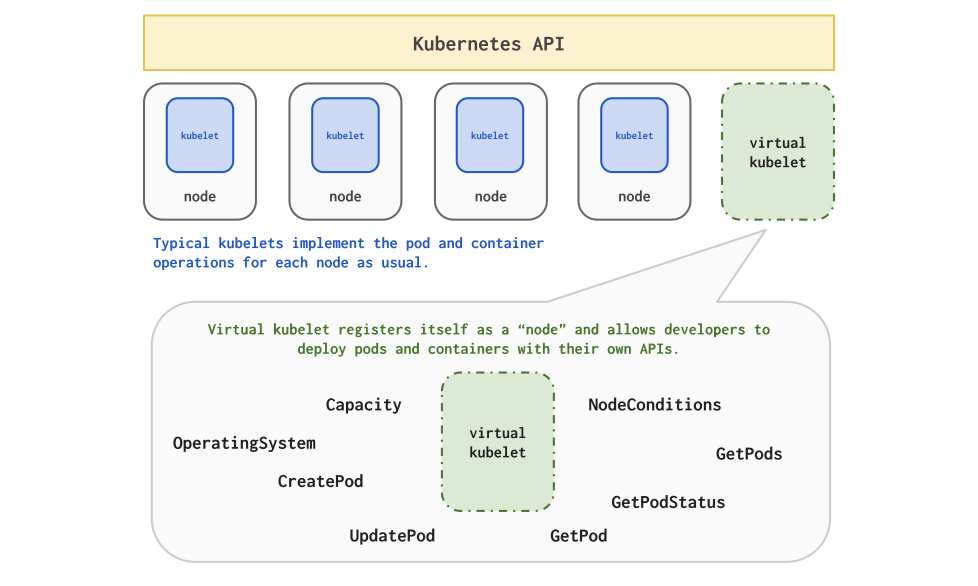
Virtual Kubelet 可以帮助你把自己的服务伪装成一个 Kubernetes 的节点,模拟 Kubelet 加入这个集群。这样就可以水平拓展 Kubernetes 集群。
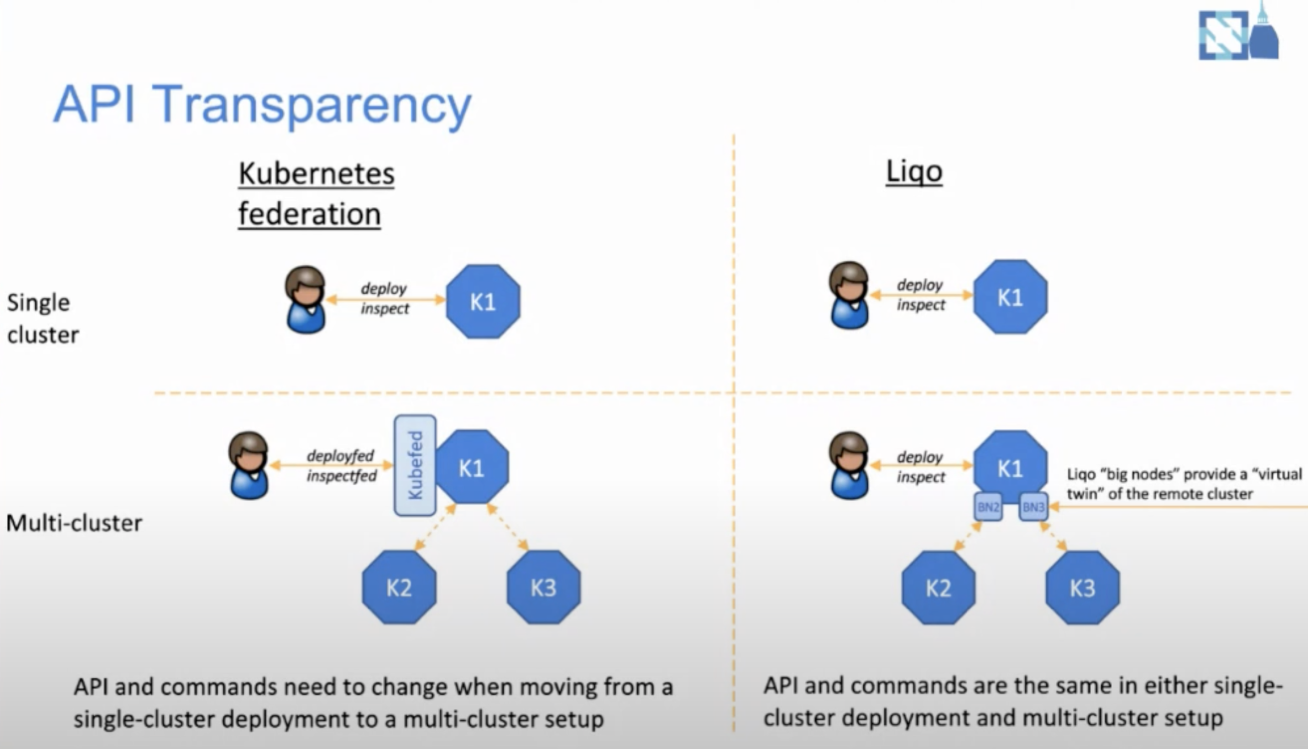
在 Liqo 里面,集群之间不存在联邦关系,左图里在 Kubefed 架构下 k2、k3 两个集群是 k1 的成员集群,资源下方需要经过一次 k1 的 push,而在右边的图里面,k2、k3 只是 k1 的一个节点,因此在部署应用的时候,完全不需要引入任何的 API,k2、k3 看起来就是 k1 的节点,这样业务就可以无感知的被部署到不同的集群上去,极大减少了单集群到多集群改造的复杂性。现在 Liqo 属于刚起步阶段,目前不支持两个集群以上的拓扑,在未来 KubeSphere 也会持续关注开源领域的一些其他的多集群管理方案。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



