
1. Flink Connectors 介绍
Flink 连接器包含数据源输入与汇聚输出两部分。Flink自身内置了一些基础的连接器,数据源输入包含文件、目录、Socket以及 支持从collections 和 iterators 中读取数据;汇聚输出支持把数据写入文件、标准输出(stdout)、标准错误输出(stderr)和 socket。
常用的是Kafka、ES、HDFS以及JDBC。
2. JDBC 连接方式的读取与写入
-
Flink Connectors JDBC 如何使用?
功能: 将集合数据写入数据库中
代码: JdbcConnectorApplication实现类:
public class JdbcConnectorApplication { public static void main(String[] args) throws Exception{ // 配置日志文件 System.setProperty("log4j.configurationFile", "log4j2.xml"); // 1. 创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 创建集合数据 List arrs = new ArrayList<String>(); arrs.add("10.10.20.101\t1601297294548\tPOST\taddOrder"); arrs.add("10.10.20.102\t1601297296549\tGET\tgetOrder"); // 3. 读取集合数据, 写入数据库 env.fromCollection(arrs).addSink(JdbcSink.sink( // 配置SQL语句 "insert into t_access_log (ip, time, type, api) values (?,?,?,?)", (ps, value) -> { System.out.println("receive ==> " + value); // 解析数据 String[] arrValue = String.valueOf(value).split("\t"); for(int i=0; i<arrValue.length; i++) { // 新增数据 ps.setString(i+1, arrValue[i]); } }, // JDBC 连接配置 new JdbcConnectionOptions.JdbcConnectionOptionsBuilder() .withUrl("jdbc:mysql://192.168.19.150:3306/flink?useSSL=false") .withDriverName("com.mysql.jdbc.Driver") .withUsername("root") .withPassword("654321") .build())); // 4. 执行任务 env.execute("job"); } }数据表:
DROP TABLE IF EXISTS `t_access_log`; CREATE TABLE `t_access_log` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID', `ip` varchar(32) NOT NULL COMMENT 'IP地址', `time` varchar(255) NULL DEFAULT NULL COMMENT '访问时间', `type` varchar(32) NOT NULL COMMENT '请求类型', `api` varchar(32) NOT NULL COMMENT 'API地址', PRIMARY KEY (`id`) ) ENGINE = InnoDB AUTO_INCREMENT=1; -
自定义写入数据源
功能:读取Socket数据, 采用流方式写入数据库中。
代码:
CustomSinkApplication实现类:
public class CustomSinkApplication { public static void main(String[] args) throws Exception{ // 配置日志文件 System.setProperty("log4j.configurationFile", "log4j2.xml"); // 1. 创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 读取Socket数据源 DataStreamSource<String> socketStr = env.socketTextStream("localhost", 9911, "\n"); // 3. 转换处理流数据 SingleOutputStreamOperator<AccessLog> outputStream = socketStr.map(new MapFunction<String, AccessLog>() { @Override public AccessLog map(String value) throws Exception { System.out.println(value); // 根据分隔符解析数据 String[] arrValue = value.split("\t"); // 将数据组装为对象 AccessLog log = new AccessLog(); log.setNum(1); for(int i=0; i<arrValue.length; i++) { if(i == 0) { log.setIp(arrValue[i]); }else if( i== 1) { log.setTime(arrValue[i]); }else if( i== 2) { log.setType(arrValue[i]); }else if( i== 3) { log.setApi(arrValue[i]); } } return log; } }); // 4. 配置自定义写入数据源 outputStream.addSink(new MySQLSinkFunction()); // 5. 执行任务 env.execute("job"); } }AccessLog:
@Data public class AccessLog { private String ip; private String time; private String type; private String api; private Integer num; }测试数据:
10.10.20.11 1603166893313 GET getOrder 10.10.20.12 1603166893314 POST addOrder -
自定义读取数据源
功能: 读取数据库中的数据, 并将结果打印出来。
代码: CustomSourceApplication实现类
public class CustomSourceApplication { public static void main(String[] args) throws Exception { // 1. 创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 配置自定义MySQL读取数据源 DataStreamSource<AccessLog> dataStream = env.addSource(new MySQLSourceFunction()); // 3. 设置并行度 dataStream.print().setParallelism(1); // 4. 执行任务 env.execute("custom jdbc source."); } }
3. HDFS 连接方式的读取与写入
-
通过Sink写入HDFS数据
功能: 将Socket接收到的数据, 写入至HDFS文件中。
代码:HdfsSinkApplication实现类
public class HdfsSinkApplication { public static void main(String[] args) throws Exception{ // 配置日志文件 System.setProperty("log4j.configurationFile", "log4j2.xml"); // 1. 创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 读取Socket数据源 DataStreamSource<String> socketStr = env.socketTextStream("localhost", 9911, "\n"); BucketingSink<String> sink = new BucketingSink<String>("d:/tmp/hdfs"); sink.setBucketer(new DateTimeBucketer<>("yyyy-MM-dd--HHmm")); sink.setWriter(new StringWriter()) .setBatchSize(5*1024) // 设置每个文件的大小 .setBatchRolloverInterval(5*1000) // 设置滚动写入新文件的时间 .setInactiveBucketCheckInterval(30*1000) // 30秒检查一次不写入的文件 .setInactiveBucketThreshold(60*1000); // 60秒不写入,就滚动写入新的文件 socketStr.addSink(sink).setParallelism(1); // 5. 执行任务 env.execute("job"); } }POM依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-filesystem_2.11</artifactId> <version>1.11.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.8.1</version> </dependency>数据源模拟实现, SocketSourceApplication实现类:
public class SocketSourceApplication { /** * 服务端的端口 */ private int port; /** * 初始化构造方法 * @param port */ public SocketSourceApplication(int port) { this.port = port; } /** * IP 访问列表 */ private static String[] accessIps = new String[]{"10.10.20.101", "10.10.20.102", "10.10.20.103"}; /** * 请求访问类型 */ private static String[] accessTypes = new String[] {"GET", "POST", "PUT"}; /** * 请求接口信息 */ private static String[] accessApis = new String[] {"addOrder", "getAccount", "getOrder"}; /** * Netty通讯服务启动方法 * @throws Exception */ public void runServer() throws Exception { // 1. 创建Netty服务 // 2. 定义事件Boss监听组 EventLoopGroup bossGroup = new NioEventLoopGroup(); // 3. 定义用来处理已经被接收的连接 EventLoopGroup workerGourp = new NioEventLoopGroup(); try { // 4. 定义NIO的服务启动类 ServerBootstrap sbs = new ServerBootstrap(); // 5. 配置NIO服务启动的相关参数 sbs.group(bossGroup, workerGourp) .channel(NioServerSocketChannel.class) // tcp最大缓存链接个数,它是tcp的参数, tcp_max_syn_backlog(半连接上限数量, CENTOS6.5默认是128) .option(ChannelOption.SO_BACKLOG, 128) //保持连接的正常状态 .childOption(ChannelOption.SO_KEEPALIVE, true) // 根据日志级别打印输出 .handler(new LoggingHandler(LogLevel.INFO)) .childHandler(new ChannelInitializer<SocketChannel>() { @Override protected void initChannel(SocketChannel socketChannel) throws Exception { //管道注册handler ChannelPipeline pipeline = socketChannel.pipeline(); //编码通道处理 pipeline.addLast("decode", new StringDecoder()); //转码通道处理 pipeline.addLast("encode", new StringEncoder()); // 处理接收到的请求 pipeline.addLast(new NettyServerHandler()); } }); System.err.println("-------server 启动------"); // 6. 监听控制台的输入, 并将输入信息, 广播发送给客户端 new Thread(new Runnable() { @Override public void run() { try { while(true) { String accessLog = getAccessLog(); System.out.println("broadcast (" + NettyServerHandler.channelList.size() + ") ==> " + accessLog); if(NettyServerHandler.channelList.size() > 0 ){ for(Channel channel : NettyServerHandler.channelList) { channel.writeAndFlush(accessLog); } } Thread.sleep(1000); } }catch(Exception e) { e.printStackTrace(); } } }).start(); // 7. 启动netty服务 ChannelFuture cf = sbs.bind(port).sync(); cf.channel().closeFuture().sync(); }catch (Exception e) { e.printStackTrace(); } } /** * 获取访问日志 * @return */ private String getAccessLog() { StringBuilder strBuilder = new StringBuilder(); strBuilder.append(accessIps[new Random().nextInt(accessIps.length )]).append("\t") .append(System.currentTimeMillis()).append("\t") .append(accessTypes[new Random().nextInt(accessTypes.length)]).append("\t") .append(accessApis[new Random().nextInt(accessApis.length)]).append("\t\n"); return strBuilder.toString(); } /** * netty服务端的启动 * @param args * @throws Exception */ public static void main(String[] args) throws Exception{ new SocketSourceApplication(9911).runServer(); } }NettyServerHandler实现类:
public class NettyServerHandler extends ChannelInboundHandlerAdapter { // 客户端通道记录集合 public static List<Channel> channelList = new ArrayList<>(); @Override public void channelActive(ChannelHandlerContext ctx) throws Exception { System.out.println("Server---连接已建立: " + ctx); super.channelActive(ctx); // 将成功建立的连接通道, 加入到集合当中 channelList.add(ctx.channel()); } @Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { System.out.println("Server---收到的消息: " + msg); } @Override public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception { System.out.println("server--读取数据出现异常"); cause.printStackTrace(); ctx.close(); } @Override public void channelUnregistered(ChannelHandlerContext ctx) throws Exception { super.channelUnregistered(ctx); // 移除无效的连接通道 channelList.remove(ctx.channel()); } @Override public void channelInactive(ChannelHandlerContext ctx) throws Exception { super.channelInactive(ctx); // 移除无效的连接通道 channelList.remove(ctx.channel()); } }POM依赖:
<dependencies> <!-- Netty 核心组件依赖 --> <dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <version>4.1.16.Final</version> </dependency> <!-- spring boot 依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <version>${spring.boot.version}</version> </dependency> <!-- Spring data jpa 组件依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> <version>${spring.boot.version}</version> </dependency> <!-- mysql-connector-java --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.jdbc.version}</version> </dependency> <!-- Redis 缓存依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <version>2.1.1.RELEASE</version> </dependency> </dependencies> -
读取HDFS文件数据
HdfsSourceApplication实现类:
public class HdfsSourceApplication { public static void main(String[] args) throws Exception{ // 配置日志文件 System.setProperty("log4j.configurationFile", "log4j2.xml"); // 1. 创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 读取HDFS数据源 DataStreamSource<String> socketStr = env.readTextFile("hdfs://10.10.20.132:9090/hadoop-env.sh"); // 3. 打印文件内容 socketStr.print().setParallelism(1); // 4. 执行任务 env.execute("job"); } } -
Hadoop环境安装
-
配置免密码登录
生成秘钥:
[root@flink1 hadoop-2.6.0-cdh5.15.2]# ssh-keygen -t rsa -P '' Generating public/private rsa key pair.将秘钥写入认证文件:
[root@flink1 .ssh]# cat id_rsa.pub >> ~/.ssh/authorized_keys修改认证文件权限:
[root@flink1 .ssh]# chmod 600 ~/.ssh/authorized_keys -
配置环境变量
将Hadoop安装包解压, 将Hadoop加入环境变量/etc/profile:
export HADOOP_HOME=/usr/local/hadoop-2.6.0-cdh5.15.2 export PATH=$HADOOP_HOME/bin:$PATH执行生效:
source /etc/profile -
修改Hadoop配置文件
1) 修改hadoop-env.sh文件
vi /usr/local/hadoop-2.6.0-cdh5.15.2/etc/hadoop修改JAVA_HOME:
export JAVA_HOME=/usr/local/jdk1.8.0_1812)修改core-site.xml文件
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://flink1:9090</value> </property> </configuration>这里的主机名称是flink1。
3)修改hdfs-site.xml文件
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-2.6.0-cdh5.15.2/tmp</value> </property> </configuration>4)修改mapred-site.xml文件
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>5)修改slaves文件
flink1这里配置的是单节点, 指向本机主机名称。
6)修改yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> -
启动Hadoop服务
[root@flink1 sbin]# ./start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh 20/09/27 19:22:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [flink1] flink1: setterm: $TERM is not defined. flink1: starting namenode, logging to /usr/local/hadoop-2.6.0-cdh5.15.2/logs/hadoop-root-namenode-flink1.out flink1: setterm: $TERM is not defined. flink1: starting datanode, logging to /usr/local/hadoop-2.6.0-cdh5.15.2/logs/hadoop-root-datanode-flink1.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: setterm: $TERM is not defined. 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop-2.6.0-cdh5.15.2/logs/hadoop-root-secondarynamenode-flink1.out 20/09/27 19:22:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop-2.6.0-cdh5.15.2/logs/yarn-root-resourcemanager-flink1.out flink1: setterm: $TERM is not defined. flink1: starting nodemanager, logging to /usr/local/hadoop-2.6.0-cdh5.15.2/logs/yarn-root-nodemanager-flink1.out上传一个文件, 用于测试:
hdfs dfs -put /usr/local/hadoop-2.6.0-cdh5.15.2/etc/hadoop/hadoop-env.sh / -
访问验证

-
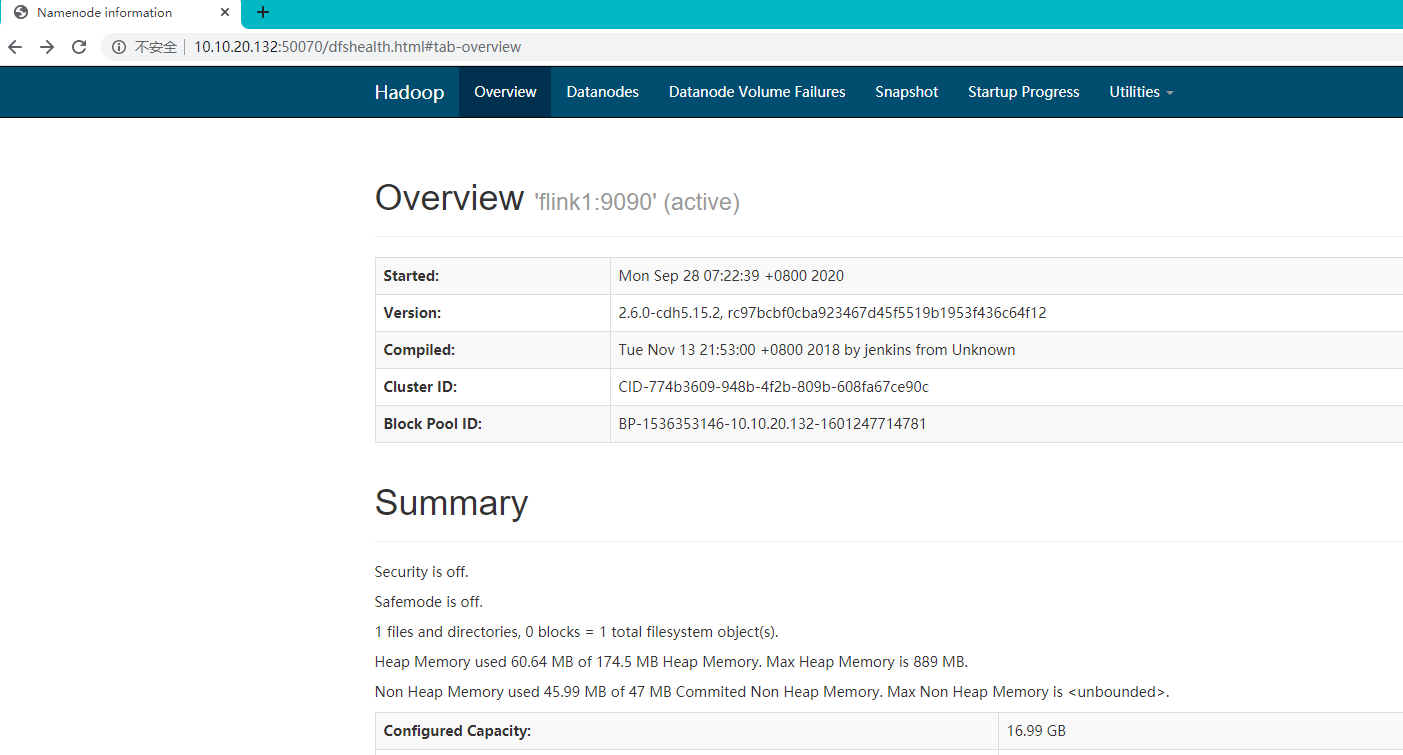
4. ES 连接方式的写入
-
ES服务安装
-
到[官网下载地址] artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.1.tar.gz 下载6.8.1版本的gz压缩包, 不要下载最新版本, Spring Boot等项目可能未及时更新支持。
-
解压安装包
tar -xvf elasticsearch-6.8.1-linux-x86_64.tar.gz -
ElasticSearch不能以Root身份运行, 需要单独创建一个用户
1. groupadd elsearch 2. useradd elsearch -g elsearch -p elasticsearch 3. chown -R elsearch:elsearch /usr/local/elasticsearch-6.8.1执行以上命令,创建一个名为elsearch用户, 并赋予目录权限。
-
修改配置文件
vi config/elasticsearch.yml, 只需修改以下设置:
#集群名称 cluster.name: my-application #节点名称 node.name: node-1 #数据存储路径 path.data: /usr/local/elasticsearch-6.8.1/data #日志存储路径 path.logs: /usr/local/elasticsearch-6.8.1/logs # 绑定IP地址 network.host: 10.10.20.28 # 指定服务访问端口 http.port: 9200 # 指定API端户端调用端口 transport.tcp.port: 9300 -
指定JDK版本
-
最新版的ElasticSearch需要JDK11版本, 下载[JDK11压缩包] download.oracle.com/otn/java/jdk/11.0.4+10/cf1bbcbf431a474eb9fc550051f4ee78/jdk-11.0.4_linux-x64_bin.tar.gz, 并进行解压。
-
修改环境配置文件
vi bin/elasticsearch-env
参照以下位置, 追加一行, 设置JAVA_HOME, 指定JDK11路径。
JAVA_HOME=/usr/local/jdk_11 # now set the path to java if [ ! -z "$JAVA_HOME" ]; then JAVA="$JAVA_HOME/bin/java" else if [ "$(uname -s)" = "Darwin" ]; then # OSX has a different structure JAVA="$ES_HOME/jdk/Contents/Home/bin/java" else JAVA="$ES_HOME/jdk/bin/java" fi fi -
关闭ConcMarkSweepGC
JDK9版本以后不建议使用ConcMarkSweepGC, 如果不想出现提示, 可以将其关闭
vi config/jvm.options
将UseConcMarkSweepGC注释:
## GC configuration #-XX:+UseConcMarkSweepGC ... ## G1GC Configuration # NOTE: G1GC is only supported on JDK version 10 or later. # To use G1GC uncomment the lines below. #-XX:-UseConcMarkSweepGC ...
-
-
启动ElasticSearch
-
切换用户
su elsearch
-
以后台常驻方式启动
bin/elasticsearch -d
-
-
问题处理
出现max virtual memory areas vm.max_map_count [65530] is too low, increase to at least 错误信息
修改系统配置:
-
vi /etc/sysctl.conf
添加
vm.max_map_count=655360
执行生效
sysctl -p
-
vi /etc/security/limits.conf
在文件末尾添加
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
elsearch soft nproc 125535
elsearch hard nproc 125535
重新切换用户即可:
su - elsearch
-
-
-
FLINK ES写入功能实现
功能: 将Socket流数据, 写入至ES服务。
代码:ElasticSinkApplication实现类:
public class ElasticSinkApplication { public static void main(String[] args) throws Exception{ // 配置日志文件 System.setProperty("log4j.configurationFile", "log4j2.xml"); // 1. 创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 读取Socket数据源 DataStreamSource<String> socketStr = env.socketTextStream("localhost", 9911, "\n"); //3. 配置ES服务信息 List<HttpHost> httpHosts = new ArrayList<>(); httpHosts.add(new HttpHost("10.10.20.132", 9200, "http")); //4. 数据解析处理 ElasticsearchSink.Builder<String> esSinkBuilder = new ElasticsearchSink.Builder<>( httpHosts, new ElasticsearchSinkFunction<String>() { public IndexRequest createIndexRequest(String element) { Map<String, String> json = new HashMap<>(); // 解析数据 String[] arrValue = String.valueOf(element).split("\t"); for(int i=0; i<arrValue.length; i++) { if(i == 0) { json.put("ip", arrValue[i]); }else if( i== 1) { json.put("time", arrValue[i]); }else if( i== 2) { json.put("type", arrValue[i]); }else if( i== 3) { json.put("api", arrValue[i]); } } return Requests.indexRequest() .index("flink-es") .type("access-log") .source(json); } @Override public void process(String element, RuntimeContext ctx, RequestIndexer indexer) { indexer.add(createIndexRequest(element)); } } ); // 5. ES的写入配置 esSinkBuilder.setBulkFlushMaxActions(1); esSinkBuilder.setRestClientFactory( restClientBuilder -> { restClientBuilder.setMaxRetryTimeoutMillis(5000); } ); // 6. 添加ES的写入器 socketStr.addSink(esSinkBuilder.build()); socketStr.print().setParallelism(1); // 7. 执行任务 env.execute("job"); } }查看index信息:
http://10.10.20.132:9200/_cat/indices?v
查看具体数据:
5. KAFKA 连接方式的读取与写入
-
Kafka安装
-
[下载Kafka_2.12-1.1.1安装包] archive.apache.org/dist/kafka/1.1.1/kafka_2.12-1.1.1.tgz
-
将安装包解压
tar -xvf kafka_2.12-1.1.1.tgz -
修改kafka配置
只修改绑定IP, 因为是单节点, 其他按默认配置来。
listeners=PLAINTEXT://10.10.20.132:9092 advertised.listeners=PLAINTEXT://10.10.20.132:9092如有多个IP地址, 绑定为对外访问的IP。
-
启动zookeeper服务
kafka安装包内置了zookeeper,可以直接启动。
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties -
启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
-
-
Flink Kafka 读取功能
功能: 通过flink读取kafka消息队列数据, 并打印显示。
代码:KafkaSourceApplication实现类
public class KafkaSourceApplication { public static void main(String[] args) throws Exception { // 1. 创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 设置kafka服务连接信息 Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "10.10.20.132:9092"); properties.setProperty("group.id", "fink_group"); // 3. 创建Kafka消费端 FlinkKafkaConsumer kafkaProducer = new FlinkKafkaConsumer( "flink-source", // 目标 topic new SimpleStringSchema(), // 序列化 配置 properties); // kafkaProducer.setStartFromEarliest(); // 尽可能从最早的记录开始 // kafkaProducer.setStartFromLatest(); // 从最新的记录开始 // kafkaProducer.setStartFromTimestamp(...); // 从指定的时间开始(毫秒) // kafkaProducer.setStartFromGroupOffsets(); // 默认的方法 // 4. 读取Kafka数据源 DataStreamSource<String> socketStr = env.addSource(kafkaProducer); socketStr.print().setParallelism(1); // 5. 执行任务 env.execute("job"); } }通过kafka生产者命令测试验证:
bin/kafka-console-producer.sh --broker-list 10.10.20.132:9092 --topic flink-source扩展点:kafka消息的消费处理策略:
// kafkaProducer.setStartFromEarliest(); // 尽可能从最早的记录开始 // kafkaProducer.setStartFromLatest(); // 从最新的记录开始 // kafkaProducer.setStartFromTimestamp(...); // 从指定的时间开始(毫秒) // kafkaProducer.setStartFromGroupOffsets(); // 默认的方法 -
Flink Kafka 写入功能
功能: 将Socket的流数据,通过flink 写入kafka 消息队列。
代码: KafkaSinkApplication实现类
public class KafkaSinkApplication { public static void main(String[] args) throws Exception { // 1. 创建运行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 读取Socket数据源 DataStreamSource<String> socketStr = env.socketTextStream("localhost", 9911, "\n"); // 3. Kakfa的生产者配置 FlinkKafkaProducer kafkaProducer = new FlinkKafkaProducer( "10.10.20.132:9092", // broker 列表 "flink-topic", // 目标 topic new SimpleStringSchema()); // 序列化 方式 // 4. 添加kafka的写入器 socketStr.addSink(kafkaProducer); socketStr.print().setParallelism(1); // 5. 执行任务 env.execute("job"); } }通过kafka消费者命令测试验证:
bin/kafka-console-consumer.sh --bootstrap-server 10.10.20.132:9092 --topic flink-topic控制消息的发送处理模式:
// 控制消息的操作模式 Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "10.10.20.132:9092"); FlinkKafkaProducer kafkaProducer = new FlinkKafkaProducer( "flink-topic", // 目标 topic new KeyedSerializationSchemaWrapper<>(new SimpleStringSchema()), properties, FlinkKafkaProducer.Semantic.EXACTLY_ONCE ); // 序列化 schema提供了三种消息处理模式:
Semantic.NONE:Flink 不会有任何语义的保证,产生的记录可能会丢失或重复。Semantic.AT_LEAST_ONCE(默认设置):类似FlinkKafkaProducer010版本中的setFlushOnCheckpoint(true),这可以保证不会丢失任何记录(虽然记录可能会重复)。Semantic.EXACTLY_ONCE:使用 Kafka 事务提供精准一次的语义。无论何时,在使用事务写入 Kafka 时,都要记得为所有消费 Kafka 消息的应用程序设置所需的isolation.level(read_committed或read_uncommitted- 后者是默认值)。
Kafka 的消息可以携带时间戳,指示事件发生的时间或消息写入 Kafka broker 的时间。
kafkaProducer.setWriteTimestampToKafka(true);
共同学习,写下你的评论
评论加载中...
作者其他优质文章


