
作者| QingStor 黄蒙
存储文件是大家日常工作生活中最常见的需求,随着文件数量和占用存储空间的上升,以及在一定范围内共享访问文件的需求产生,我们自然需要把存储文件的工作从单个计算机设备中剥离出来,作为一个单独的服务资源(或物理硬件)来对外提供存储功能,提供更大的容量的同时,为多个终端通过网络共享访问。
这里提到的存储设备就是我们常说的 NAS(Network Attached Storage:网络附属存储)。
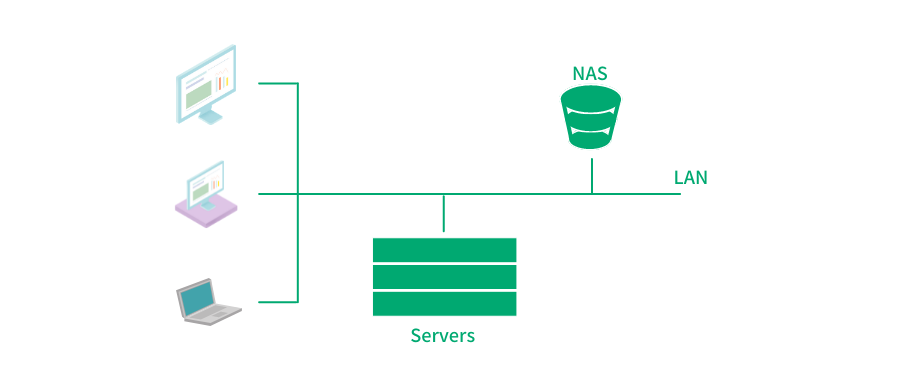
而终端通过网络来共享访问 NAS,需要标准的协议规范。NFS 就是其中最重要也是应用最广泛的协议标准之一(其它流行的网络文件协议还有 SMB[1] 协议,后续会有专门的文章进行介绍,尽请期待)。今天我们就来聊聊 NFS 协议。
1. 简单好用的无状态协议诞生
NFS 第一次出现在我们的视野中,是在 1985 年。NFS version2 作为 SunOS 2.0 的组件正式发布。所以在当时把它叫做 “Sun 网络文件系统” 可能更为贴切。另外,你没有看错,第一个正式对外发布的版本就是 v2 版本(v1 版本从未对外正式发布,这也是我们从不讨论 NFS v1 的原因)。
不过 NFS 并不是最早的网络文件系统,彼时已经有一些更早的网络文件系统存在,比如 UNIX SVR3 系统中包含的 RFS(Remote File System)[2] RFS 已经引入了 RPC(Remote Procedure Call)概念,并成为 NFS v2 的借鉴的范本。但 RFS 也有自己明显的问题,比如其为每个客户端打开文件记录状态(即有状态协议),所以很难应对服务端宕机或重启的情况。NFS v2 为了在设计层面很好的解决 RFS 的缺陷,设计成了一个完全无状态的协议。
1995 年,NFS v3 正式发布。此时 NFS 协议的开发已经不再完全依赖 Sun 公司,而是多家公司共同主导完成. NFS v3 包含众多优化,但大多数可以认为是性能层面的优化。总体看来,NFS v3 仍然遵循无状态协议的设计。
无状态协议的设计,自然是降低了应对服务端宕机重启情况的处理难度。但想要彻底挣脱“有状态信息”的束缚并不容易。比如,作为网络文件协议,就需要支持 “文件锁” 操作,但锁信息天然就是一种“状态信息”。所以在 NFS v2/v3 运行的环境中,NFS 将这部分负担 “外包给”了 NLM(Network Lock Manager)。当 NFS Client 接收到一个文件锁请求时,会产生一个 NLM 协议的 RPC 调用,而不是产生一个 NFS 协议的 RPC 调用。但这样 NLM 就成为了一个 “有状态” 协议。所以它需要处理出现服务端崩溃、客户端崩溃、网络分区出现后的故障恢复问题。NFS v2/v3 协议与 NLM 的配合工作总体来说不够协调(比如 NLM 协议本身会标记和识别每把锁由哪个进程申请和持有,但 NFS server 处理读写请求时,却无法区分请求来自于哪个远端进程),这也导致了难以完美的实现锁逻辑。
即便抛开文件锁的问题不谈,无状态协议设计本身也带来了新的问题。NFS 服务作为“无状态服务”,无法记录各个 NFS 协议客户端打开文件的状态,也就没有简单直接的办法判断文件内容是否已经被其它客户端修改,即 cache 是否还有效。在 NFS v2/v3 协议中,NFS 协议客户端通常将文件的修改时间和文件大小保存在 cache 详细信息中,以一个时间间隔,定期对 cache 进行有效性验证:NFS 协议客户端获取当前的文件属性,和 cache 中的修改时间及文件大小做比较,如果仍一致,则假定文件没有修改过,cache 仍然有效;如果不匹配,则认为文件发生了了变化,cahce 不再有效。这样的方式显然是低效的。而更不幸运的是,由于很多文件系统保存时间戳的精度不足,NFS 协议客户端无法探测出那些在一个较粗精度的时间单位(秒)中连续的修改,比如刚校验过 cache 有效性后,同一秒内又发生了更改(覆盖写),那么从修改时间和文件大小都观察不出需要重新更新cache。这种情况下,只有该 cache 被 lru 驱逐,或者文件后续被再次修改,否则 NFS 协议客户端无法感知到文件的最新变化。
2. 无状态到有状态,进化为成熟单机网络文件系统
2002 年 NFS v4.0 版本发布。此时 NFS 协议的开发完全由 IETF 主导,最大的一个变化就是 NFS 协议的设计从无状态协议变为有状态协议。
从无状态协议再次演变为有状态协议,并不是追求一种 old fasion,而是因为当前已经具备了更好的工程能力,来设计开发出足以应对有状态协议设计下复杂问题的机制(当然,这背后的动力显然也是拜常年忍受无状态设计中的种种缺陷之苦所赐)。
NFS v4.0 的有状态设计主要体现在如下几个方面:
a. 协议自身加入了文件锁功能,会维护锁信息这样的状态信息,不需要 NLM 协助。
b.在 cache 一致性问题的处理上,NFSv4 支持了 delegation 机制。由于多个客户端可以挂载同一个文件系统,为了保持文件同步,NFSv4可以依靠 delegation 实现文件同步。当客户端 A 打开一个文件时,NFS 服务端会分配给客户端 A 一个 delegation。只要客户端 A 持有 delegation,就可以认为与服务端保持了一致,可以放心的的在 NFS 协议客户端侧做缓存等处理。如果另外一个客户端 B 访问同一个文件,则服务端会暂缓处理(即短暂阻塞)客户端 B 的访问请求,并向客户端 A 发送 RECALL 请求。当客户端 A 接收到 RECALL 请求后,会将本地缓存刷新到服务端中,然后将 delegation 归还给服务端,这时服务端开始继续处理客户端 B 的请求。
当然,delegation 机制仅能理解为在考虑缓存一致性的情况,以一种更加激进的方式进行读写处理,所以该机制更应该被理解为是一种性能效率优化,而不是完全解决 cache 一致性问题的方案,因为当 NFS 服务端发现多个客户端对同一文件的竞争出现,并回收之前发放的授权后,又会回退到跟 v2/v3 版本中相似的机制去判断 cache 的有效性。
除了上述两点,v4.0 版本相较之前的版本还有以下优化:
a. NFSv4 增加了安全性设计,开始支持 RPC SEC-GSS[3] 身份认证。
b. NFSv4 只提供了两个请求 NULL 和 COMPOUND,所有的操作都整合进了 COMPOUND 中,客户端可以根据实际请求将多个操作封装到一个 COMPOUND 请求中,增加了灵活性的同时减少了交互次数,大大提高了性能。
c.NFSv4 版本中修改了文件属性的表示方法,显著增强对 Windows 系统的兼容性,而几乎同时,微软开始把 SMB 协议重塑成 CIFS(Common Internet FileSystem),这看起来绝非巧合,可见两者的竞争意味。
经过上面这些改进,可以说 NFS 已经进化成为了成熟高效的单机网络文件系统,但是软件的世界已经慢慢向文件系统提出了更多扩展性的需求和更多的企业级特性需求,NFS v4.0 版本对此还未给出答案。
3. 具备更强扩展性,企业级集群文件系统雏形已现
2010 年及 2016 年, NFS v4 的演进版本 v4.1 和 v4.2 陆续发布。
2010 年,NFS v4.1 的问世,让 NFS 向集群文件系统的方向迈出了重要一步 — 因为其引入了并行文件系统的概念(Parallel NFS/pNFS):即在协议层面将元数据与数据分离,创造出元数据节点和数据节点的角色,对数据的访问具备了一定扩展性。并行访问数据的设计也让整体吞吐提升到新的高度,这与很多现代分布式文件系统思路相似。
但需要指出的是,在此设计中,元数据的处理扩展性仍未得到解决。另外作为有状态协议,在用来保证高可用性的主备架构中,由于备节点中并没有主节点中维护的状态信息,所以故障切换过程很难做到足够平滑。
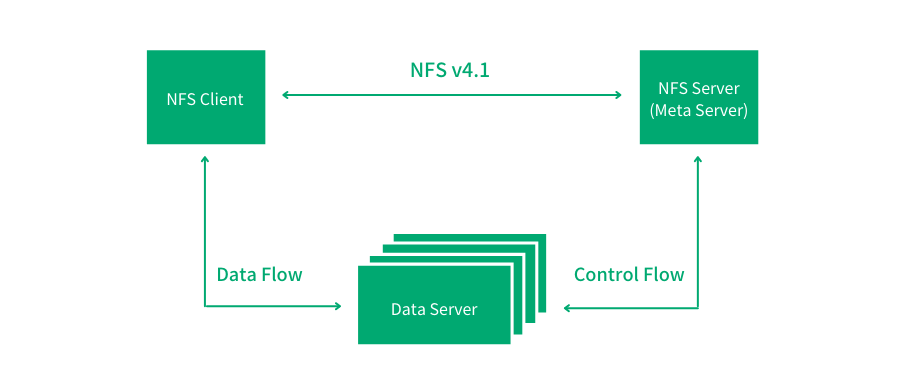
除此之外,NFS 协议开始加入了更多的数据中心级企业级特性:
NFSv4.1 开始支持 RDMA(Remote Direct Memory Access)[4],并在 NFS v4.2 中开始支持稀疏文件(sparse file)以及支持 server 侧拷贝(Server-Side Copy)。
这都帮助 NFS 协议可以更好地支撑更加严肃的数据中心/企业级应用。
4. NFS 的继续进化和工程层面的探索:内核态 vs 用户态
NFS 协议不断的发展,在复杂性不断提高的同时,也在集群扩展性/可用性方面不断探索,但这无疑也给工程实现层面提出了新的挑战。在 Linux 世界中,最常使用的就是内核态的 nfsd 服务,但是随着机制和架构的复杂性的增加,在用户态去实现一个 NFS 服务似乎成为了一个工程更合理的方案。作为 NFS 在 Linux 世界中的竞争对手,Samba[5] 服务就是基于用户态打造了一套较为完整的集群方案。
针对这一问题,开源社区也给出了一些探索,其中最具影响力同时也是应用最广泛的要数 nfs-ganesha[6] 项目,该项目目前由 RedHat 维护,其在用户态实现了完整的 NFS 服务功能。
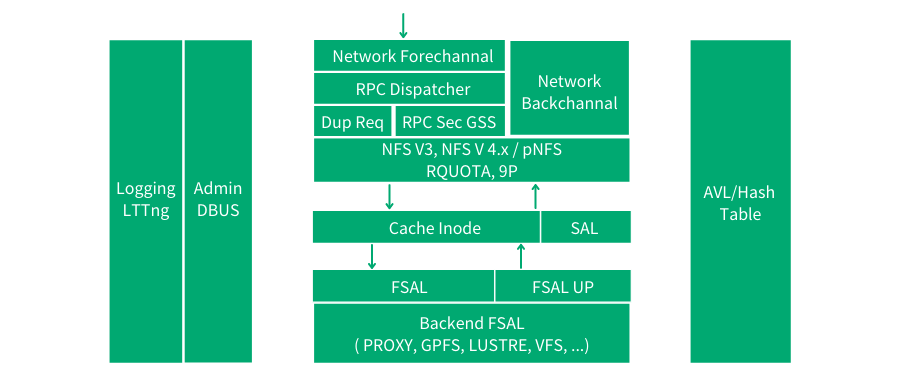
如图 nfs-ganesha 架构图所示,该项目本身专注于协议处理逻辑(支持所有的 NFS 协议版本),同时设计独立的 SAL(State abstraction layer)抽象层,和 FSAL(File-System abstraction layer)抽象层。前者有助于在处理有状态协议的“状态”时扩展一些集群逻辑,而后者方便接入包括本地 VFS 文件系统和各种开源/商业分布式存储。这样的设计有利于借助外部中间件和服务来打造更好的集群逻辑,为更多开放性的设计提供了空间,同时也通过对接更多的后端存储系统来保证社区活力和扩大应用范围。
在未来相当长的一段时间里,NFS 协议仍会承担重要的角色,而 NFS 的工程实践想要进一步获得发展,满足日渐膨胀及复杂的需求,仍需要在用户态继续探索。
NFS 协议不但是我们平时共享文件的背后功臣,也在超算和广电等行业支撑着各类核心业务。
作为一个有多年历史的网络文件协议,NFS 有其历史局限性,甚至每次迭代都有其沉重的历史包袱捆绑手脚,但它仍可以被当作文件系统的经典范例去研究。可以说对 NFS 协议了解逐步深入的过程,也是对现代分布式文件系统重新理解的过程。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



