
你好呀,我是why。

不是,这不是我。我还年轻,也比他帅。
这是今天文章的主人公。
他叫做 Brett Wooldridge,你应该是不认识的。
但是我把他的 github 截图给你看看,你一定知道他写的开源项目:
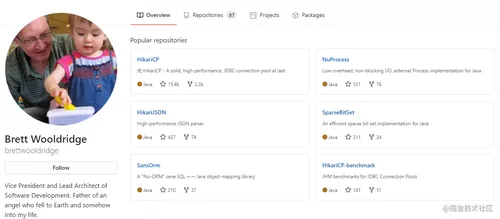
看到了吗?
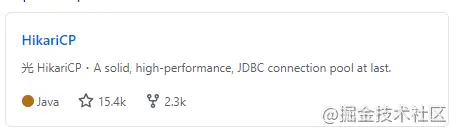
他就是大名鼎鼎的 HikariCP 的爸爸啊。
而且你看他的 github 的简介,写的很有感觉:
Father of an angel who fell to Earth and somehow into my life.
一个落到地球上的天使的父亲,她不知不觉地进入了我的生活。
图片应该是就他的孩子,他在旁边露出了老父亲般慈祥的微笑。
文章最开始的那一张图,是我从这个报道中找到的:
其中问的第一个问题是这个:

你创建了Java 中最流行的连接池之一,HikariCP。那么请问是什么让你的库如此受欢迎呢?
下面一小节,我就用第一人称的角度给大家讲述一下这个老哥是怎么回答这个问题的。
为啥写 HikariCP?
啥,你问我为啥要写 HikariCP?
哎呀妈呀,还不是因为没有找到趁手的家伙什嘛。
我几年前写代码的时候,需要用到一个数据库的连接池,于是就像大多数开发者一样,面向浏览器编程,在网上找了一个开源的池子,拿来就用。
你还别说,看起来好像还不错。
但是后来在对项目做性能测试的时候,就慢慢的发现这个池子不太行了,老是会碰到死锁、连接状态不正确的问题。
我寻思这玩意不是坑爹吗?

但是当时用的连接池是开源的嘛,本着开源的精神,我就想着把代码拉下来看看嘛,能不能帮忙给修复一下。
结果我打开代码的时候,好家伙,代码量之大,至少比我预期的要多出个几千行来。
代码多就算了,忍忍就能读下去。
神奇的是代码逻辑。
我是去排查死锁问题的,结果我发现锁是一个套一个。
有的时候在一个方法里面获取到锁了,我硬是找不到释放的地方。
最后在隔着十万八千里的地方,看到了释放锁的地方。
我当时大概是这样的:

因为我知道,我已经没有办法找到死锁潜伏在代码的哪个角落了。
就算我解决了当前的问题,按照项目这样的写法,迟早也会碰到其他的问题。
于是我当机立断,决定...
在网上再找一个。

这次我学乖了,找到新的连接池之后,我先看了它的代码。
因为被死锁搞怕了,所以特别是关注了关于锁的部分。
新找到的连接池锁的语义确实更清晰了,但是代码量仍然是我预期的二倍多。
除此之外,我研究过的所有的链接池,都在以各种各样的方式违反 JDBC 的合约。
比如,我发现的最常见的一个问题是这样的。
当一个链接被用完了,放回池子里面的时候。某些池子并没有把这个链接里面的消息清理干净,比如自动提交、事务隔离级别等等,导致下个消费者再次拿到这个链接的时候,是一个“脏”链接。
我当时就在想:

Really?这就是 Java 生态中的连接池的现状?不行了,我要亲自出手了。于是出于需要和挫折感,我创建了HikariCP。
回到最开始的问题。
如上所述,在我写 HikariCP 之前,其实已经有很多成熟的连接池了,那么 HikariCP 是如何变得流行的呢?
再我看来,如果我主打正确性和可靠性,其实不算一个好的卖点,因为我认为这是必须所具备的东西。
所以我专注于推广性能。在我的各个社交媒体上去进行推广。
在 2015 年的某个时候,Wix 工程团队写了一篇关于使用 HikariCP 的博客。
这一波我就直接弹射起飞了。HikariCP 也算是走进了大家的视野。
最后,我确实希望随着时间的推移,更多的用户会对正确性和可靠性给予同等的重视,没有这些性能就没有意义。
就我而言,我打算多写一些关于 HikariCP 的这些方面的文章。
性能为啥牛逼?
前面说了,HikariCP 的卖点是强悍的性能。
那么它的性能为啥这么牛逼呢?
其实答案就写在 HikariCP 的 github 主页上:
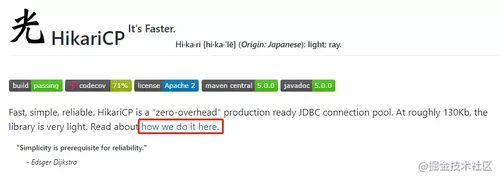
在进入 how we do it here 之前,先简单说说这个项目的名称。
可以看到一个大大汉字:光。
关于这个名字的来源,其实在前面提到的报道中也提到过:

HikariCP,被翻译为“光”,在英语中,在HikariCP的上下文中,它是一个双关语。在这个项目里面,"光"不只表示速度快,也是指代码量很少。
Hikari 的发音是 Hi-ka-lee。
这个大家记一下。
我记得有一次面试,有个面试者提到了这个连接池,但是他不知道怎么读。
他说:就是 H 开通 CP 结尾的那个连接池,咋读的我忘记了。
但是我当时也一下就反应过来了。
我说:嗯,我知道你说的哪个连接池,你继续说。
其实,当时我也不知道怎么读,就很尴尬。
好了,接下来,就一起看看性能为啥这么牛逼。
答案,作者都在 github 里面写着呢:
首先,这个文章的标题就很有意思:

wath mean is Down the Rabbit Hole?
直译过来是“在兔子洞里”。

我觉事情没有这么简单,于是我去查了一下:

哦,down the rabbit hole 原来是是冒险进入未知世界的隐喻。出自著名的《爱丽丝梦游仙境》一书中。
一般我们用 down the rabbit hole 用来描述陷入一个愈发奇怪、令人摸不着头脑或出人意料的状况,而且一件事情促使另一件事情的发生,接连不断,因此越陷越深、无从脱身的场景。
一个英语的小俚语,送给大家。

知道标题的含义后,等你看完作者写的文章之后,你再次审视这个“兔子洞”的标题,你就会发现:真特么贴切啊。
全文读完,理解之后,我发现作者想表达的为什么这么快的原因有四个:
字节码级别的优化-尽量的利用 JIT 的内联手段
字节码级别的优化-利用更容易被 JVM 优化的指令
代码级别的优化-利用改造后的 FastList 代替 ArrayList
代码级别的优化-利用无锁的 ConcurrentBag
我们一个个的看。
字节码级别的优化
文章的开头,作者就说了:我这波操作在字节码,就问你牛不牛逼。

简单的翻译一下关键的地方:
为了使 HikariCP 变得更快,我进行了字节码级别的优化。
我拿出了我所知道的所有技巧来利用 JIT 优化,从而帮助到你。
我研究了编译器的字节码输出,甚至是JIT的汇编输出,以限制关键的程序小于 JIT 的 inline-threshold。
这个地方作者提到了 JIT 的内联优化。
啥是内联?
内联其实是一个动作。
选定某个被调用的方法,将其内容复制到被调用的地方。
举个简单的例子,假设代码是这样的:
int result = add(a,b);
private int add(int x,int y){
return x+y;
}复制代码那么经过 JIT 的内联优化之后,代码就会变成这样:
int result= a + b;复制代码
这样,节约了调用 add 方法的开销。
内联,也被称为优化子母,它为其他的优化手段建立了非常好的基础,所以除了上面写的那个例子之外,还有很多的更加进阶的体现方式,比如逃逸分析、循环展开、锁消除:

那么一个调用的开销到底有哪些呢?
我想无外乎就是这几步:
首先要设置方法调用需要传递的参数,对吧?
有了参数,是不是还得查询具体调用哪个方法,对吧?
然后如果有类似于局部变量,或者求值这样的方法,还得创建新的调用栈帧,创建新的运行时数据结构,对吧?
最后,还有可能需要给调用方返回一个结果,对吧?
有的朋友就就会说了,至于吗?这个开销看着也不大啊?
是的,确实不大,但是当再小的一个优化点,乘以一个巨大的调用量之后,最终的结果都是很可观的。
我想这个道理大家都明白。
作者也在文章里面说了:

HikariCP 包含了许多微观的优化,这些优化单独来看几乎无法衡量,但结合起来就能提升整体性能。
甚至在数百万次的调用中,优化的级别是以毫秒的时间来衡量的。
可能这就是大佬吧。
我想,追求性能的极致,也就不过如此了。
接下来,说说另外一个字节码级别的优化:
invokevirtual vs invokestatic
这波优化我觉得简直就是在大气层了。
作者举了个例子。
之前获取 Connection, Statement, ResultSet 的代理对象什么的都是通过单例工厂方法。
就类似于这样的:

ROXY_FACTORY 就是一个 static 的字段。
上面的代码的字节码大概是这样的:
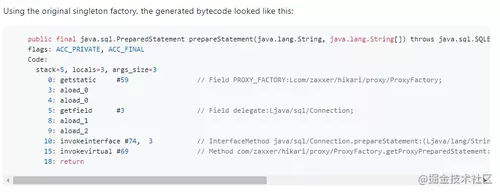
通过字节码你可以看到,首先有一个 getstatic 调用,来获得静态字段 PROXY_FACTORY 的值。
还有一个 invokevirtual 指令的调用,对应的就是 ProxyFactory 实例的 getProxyPreparedStatement() 方法:
15: invokevirtual #69 // Method com/zaxxer/hikari/proxy/ProxyFactory.getProxyPreparedStatement:(Lcom/zaxxer/hikari/proxy/ConnectionProxy;Ljava/sql/PreparedStatement;)Ljava/sql/PreparedStatement;复制代码
这个地方有什么优化空间呢?
作者把代码修改成了这样:

其中 ProxyFactory 是通过 Javassist 生成的。
所以你去看 ProxyFactory 源码,全是空实现,
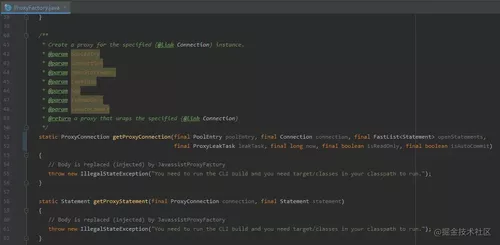
它真正的实现逻辑,是对应源代码的这个类,就不具体展示了,有兴趣的可以下来看看:
com.zaxxer.hikari.util.JavassistProxyFactory
然后,把 getProxyPreparedStatement 方法做成了 static。
然后字节码就变成了这样:
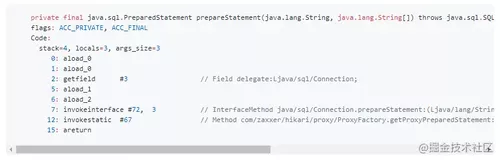
神奇的事情就发生了:

getstatic 指令消失了
invokevirtual 被替换成了 invokestatic 调用,这样更加容易被JVM优化。
最后,可能第一眼没有注意到的是,堆栈大小从 5 减少到 4 。这是因为在 invokevirtual 的情况下,ProxyFactory 的实例被隐含地传递到了堆栈中(也就是 this 对象),而且在调用 getProxyPreparedStatement() 时,还有一个额外的从堆栈中弹出的操作。
第 1,3 点应该问题不大。大家都能明白是怎么回事。
但是这个第二点:invokevirtual 被替换成了 invokestatic 调用,这样更加容易被JVM优化。
说真的,我第一次看到的时候大概是这样的:

为啥啊?
invokevirtual 和 invokestatic 是干啥的我倒是还记得。
但是 invokestatic 的性能会更好一点吗?
于是我带着这个问题去翻了《深入理解JVM虚拟机》,没有直接找到答案。
但是还是有意外收获的。就是写下了这篇文章:《报告!书里有个BUG》
不然你觉得我为什么会突然翻到书里面的这一部分,都是有契机的。

虽然,书里面没有直接把答案写出来,但是在相关部分有这样的一段话:

我理解一下就是 invokevirtual 指令,需要查询虚方法表才能确定方法的直接引用。
而 invokestatic 在类加载的时候,就可以从符号引用转成直接引用。
这样看来,invokestatic 确实是优于 invokevirtual 的。
那么问题又来了。
类加载的过程是什么?
加载、验证、准备、解析、初始化。
invokestatic 是在哪个过程搞事情的?
肯定是解析阶段哈,朋友们。
解析阶段,就是 JVM 将常量池内的符号引用替换为直接引用的过程。
扯远了,说回来。
上面只是我的一点猜测,我相信肯定不止我一个人看了作者的“兔子洞”文章后关于 invokevirtual vs invokestatic 这一块有疑问。
于是,我去查了一圈。
果不其特么的然。(抱歉爆粗了,但是我确实找了很久。)
找到了这个链接,链接的前半部分和我的问题一模一样:
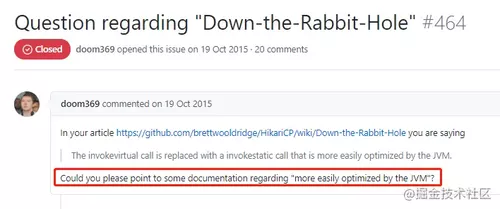
作者的回复如下:
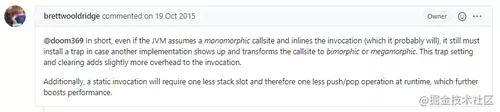
后面那一段 Additionally 很好理解。
就是前面说的,静态调用少一个堆栈,在运行时就少一个推/拉操作,这进一步提高了性能。
主要是前面这段,有亿点点难懂。
他说:简而言之,JVM 在做内联调用的时候,即使是单态的内联,它也必须安装一个 trap(陷阱),以防另一个实现出现,并将调用转变为多态。
这个 trap 的设置和清除给调用增加了一点开销。
怎么样,懵不懵逼?
其实,他这句话,我个人理解,说的就是 Java 的动态分派,聊的就是 JVM 的 CHA(Class Hierarchy Analysis,类型继承关系分析) 技术。
答案就写在《深入理解Java虚拟机(第三版)》的 417 页,翻去吧:

你非要问我证据是什么,那么这两个单词呼应上了,你说这事多巧?
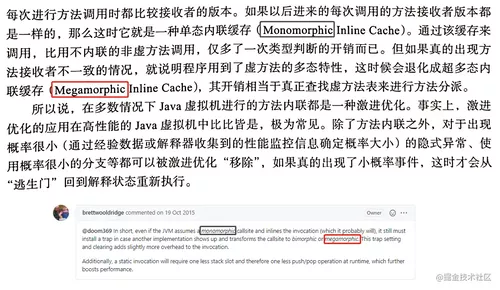
invokevirtual 调用的是虚方法,按照书里的说法,前面提到的 trap 其实就是这里的“逃生门”:

而 This trap setting and clearing adds slightly more overhead to the invocation(这个 trap 的设置和清除给调用增加了一点开销)这句话,其实就是对应这里:

现在你知道为什么对于 JVM 来说, invokestatic 比 invokevirtual 更容易优化了吧?
优化指的就是内联。
invokestatic 调用的是静态方法,对于非虚方法,JVM 可以直接进行内联,这种内联是有百分之百的安全保障的。
而 invokevirtual 调用的是虚方法,对于虚方法的内联,就得上 CHA 机制,设置逃生门这一套玩意。
虽然都是内联,这不得多消耗一点性能嘛。
内联已经是性能优化了,让代码更好的内联,优化性能优化的优化。
这波操作,在大气层。

好了,上面就是字节码层面的优化了,接着我们看代码层面的优化。
代码层面的优化
代码层面上最出名的就是 FastList 替换 ArrayList 这个玩意了。

首先,我去看了项目的提交记录,在 2014 年 1 月 15 日的时候,作者进行了一次提交:
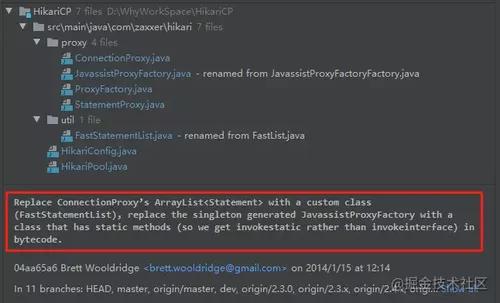
备注的后半部分我们应该很熟悉了,前面已经讲过了。
前面就是用 FastList 替换 ArrayList 的那一次提交。
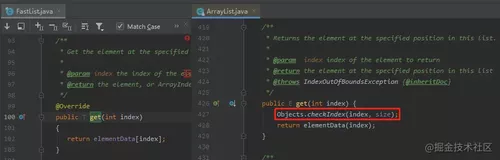
Java ArrayList 在每次调用 get(int index) 时都会进行范围检查。在 HikariCP 项目中,可以保证 index 在正确的范围内,所以这个检查没有意义,于是就去掉了:
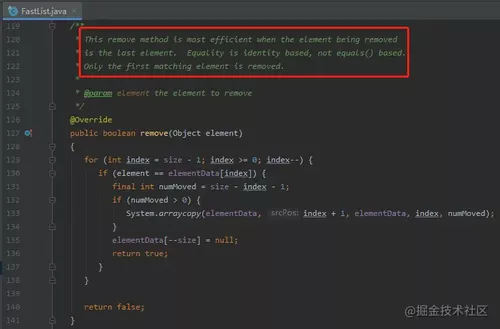
再比如,ArrayList 的 remove(Object o) 方法是从头扫到尾。
假设要删除最后一个元素,需要遍历整个数组。
巧就巧在,比如 HikariCP 的 Statement,按照我们的编码习惯,删除(关闭)应该先删除最后一个。
所以 FastList 优化了 remove(Object element) 方法, 将查找顺序变成了逆序查找:
整体来看,FastList 的优化点就上面说的 get 和 remove 方法。
接着,看看另外一个代码级别的优化:
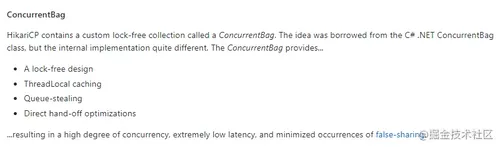
作者列了几个点:
一个无锁的设计
线程本地缓存
窃取队列
直接交接的优化
作者介绍的很简单,其实这里面还是很有东西的。
一个重要的技巧是 ConcurrentBag 通过 ThreadLocal 做了一次连接的预分配。
通过 ThreadLocal 一定程度上避免了共享资源的竞争。
自己看代码的话主要看看 add(空闲连接加入队列)、borrow(获取连接)、requite(释放连接) 方法。
网上也有很多相应的文章去介绍,有兴趣的可以去了解一下,我这就不写了。
哦,你不想看其他的文章,就想等着我给你讲呢? 好的,先欠着,欠着。 偷个懒,文章写太长了也没人看。

打起来了
在写文章的过程中,我还看到了这样的一个 issue,感觉有点意思,写一下。
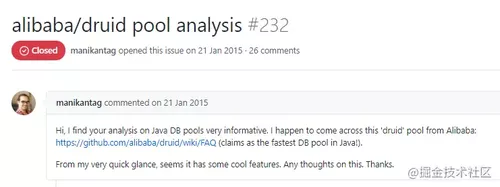
一个小哥说:
你好,我觉得你对 Java 数据库池的分析很有参考价值。我碰巧遇到了阿里巴巴的这个 druid 线程池(号称是Java中最快的数据库池!)。从我的快速浏览来看,它似乎有一些很酷的功能。对此有什么想法吗。谢谢。
HikariCP 的作者很快就进行了回复:

至少在他的基准测试中,Druid 在获取和返回连接方面是最慢的,而在创建和关闭语句方面是第三快的。他们维基中的基准页面没有显示他们是用什么配置运行的,但我怀疑他们禁用了借来的测试。虽然我不会说这是 "作弊",但这不是我在生产上的使用方式。据我所知,他们也没有提供他们测试源代码。
这就有点意思了。
虽然我不会说这是"作弊",这话说的,就像是:有一句话我不知当讲不当讲。
然后就接着讲出来了。
接着,另外一个吃瓜网友说:
Druid 的设计理论是专注于监控和数据访问行为的增强(如自动数据库切片)。它提供了一个SQL解析器来分析用户的SQL查询,并收集了很多数据用来监控。因此,如果你需要一个 JDBC 监控解决方案,你可以试试 Druid。
HikariCP 的作者也表示这句话没毛病,但是他强调了自己的 HikariCP 也是给监控留了口子的:
这是一个有效的观点。我想指出,HikariCP也提供监控数据,但提供的指标是 "池级 "指标,并不具体到查询执行时间等。
上面的对话,都是发生在 2015 年 1 月。
但是一年半后, 2016 年 7 月 26 日,这个问题又被一个人激活了:
wenshao,来者何人?
此人正是 druid 的爸爸之一,江湖人称温少。
也许你不认识温少,也许你不知道温少写的 druid,但是你一定知道温少的另外一个大作:
问题是多了一点,但是并不妨碍别人是大神。
可以直接端茶:
首先温少说:如果你配置了maxWait 属性,druid 会使用公平锁,所以降低了性能。
至于为什么这样的,是因为在生产环境中遇到的一些问题,设计如此。
然后他接着提到了淘宝:
链接点进去,标题是这样的:
说的是 2015 年的天猫双 11。
标题翻译过来就是:
阿里巴巴集团在光棍节销售的前90分钟内销售了50亿美元。
我还在链接里面看到了好久没见的马爸爸:
我理解温少放这个链接的意思就是说,druid 在阿里内部使用,天猫双十一是一个非常牛逼的场景,druid 经受住了这样场景的考验。
HikariCP 的作者并没有回复温少。
直到另外一个吃瓜群众的推波助澜:
HikariCP 的作者寻思,这是要进行数据量的 battle 了呀。
那我就不客气了。
HikariCP 是世界上使用最广泛的连接池之一,被一些最大的公司使用,每天为数十亿的用户提供服务。
而对于 Druid,不好意思,我说话有点直:在中国以外的地方很少见。
但是对于他的这个回答,很快就有人提出了质疑:
一些最大的公司都在使用,每天为数十亿用户服务?比如说呢?
要数据是吧?坐稳了:
wix.com托管着超过1.09亿个网站,每天处理的请求超过10亿个。
Atlassian的产品拥有数百万的客户。
HikariCP是 spring boot 的默认连接池。
HikariCP每月从中央maven仓库解析超过30万次。
这些公司都在用:
这个回答之后,双方都没有说话了。
两方之间的 battle 就算是结束了。
但是还有人在继续跟帖,我觉得这个哥们属于清醒吃瓜:
另外一个老哥的回答就有意思了:
别吵了,别吵了。我特么来这里是学技术的,不是来看你们讨论 "资本主义"工具和 "共产主义"工具的区别的。
而我觉得,这场 battle 其实真的没有特别大的意义。
在技术选型上,没有最好的,只有合适的。
Druid 和 HikariCP 各有各的优势。
作者:why技术
链接:https://juejin.cn/post/6994287988809302024
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


