
hive 说明与使用
hive 介绍
hive 基于 hadoop 数据仓库的工具
hive 使用 hql 语言操作; hql 语句有点类似 sql, 最终在 hadoop 节点上运行
hive 优点
通过 sql 语法简单容易去上手
避免写原生 hadoop 程序, 减少开发工作量
hive 执行延时比较高, 所以hive 适合 数据量特别大, 实时性要求不搞的情况
hive 支持用户自定义函数
hive 缺点
hql 表达能力有限
hive 无法做迭代式的运算
hive 数据挖掘不是特别擅长
hive 效率低,调优空间小,只能用于离线场景: 所以一般我们不会直接使用hadoop执行查询, 而使用spark和hadoop链接在一起执行查询
hive 架构原理和使用场景
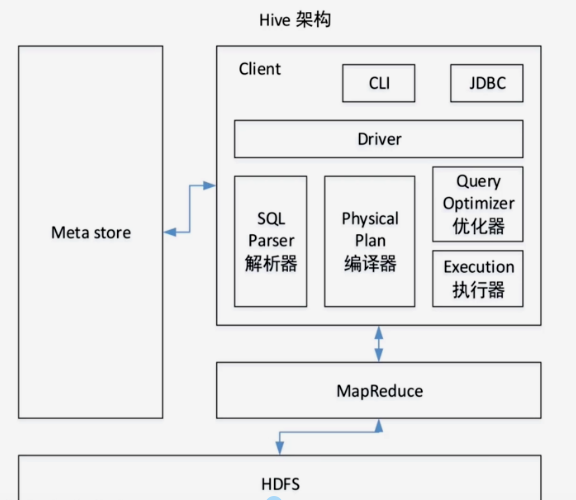
数据存储在 hdfs, hive 类sql 操作
到数据仓库的数据基本就是不变的数据, 所以读的特别多, 写得特别少. 尽量不要改写.
hive 没有索引,所以查询都是全表扫描: 离线数据分析; 可扩展性非常好
hive 实操
# 进入 hive 容器
docker ps
docker exec -it dc387ff5c56d /bin/bash
# 进入 hive 命令行
root@dc387ff5c56d:/opt# hive
#
hive> show databases;
OK
default
Time taken: 1.009 seconds, Fetched: 1 row(s)
hive> use default;
hive> show tables;
hive> create table student(id int , name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 2.854 seconds
# 浏览器查看 hadoop 数据节点是否创建成功 student 表
http://192.168.20.157:50070/explorer.html#/user/hive/warehouse
在宿主机编辑好文件 复制到 容器中
[work@Lan-Kvm-20157-Reptile2 ~]$ vim student.txt
1 namenode
2 spark
3 hadoop
4 elasticsearch
"student.txt" [New] 4L, 44C written
[work@Lan-Kvm-20157-Reptile2 ~]$ docker cp ./student.txt dc387ff5c56d:/opt
[work@Lan-Kvm-20157-Reptile2 ~]$ docker exec -it dc387ff5c56d /bin/bash
root@dc387ff5c56d:/opt# ls
hadoop-2.7.1 hive student.txt
root@dc387ff5c56d:/opt# cat student.txt
1 namenode
2 spark
3 hadoop
4 elasticsearch
root@dc387ff5c56d:/opt#
加载数据到 hive
hive> load data local inpath '/opt/student.txt' into table student;
Loading data to table default.student
OK
Time taken: 2.415 seconds
hive> select * from student;
OK
1 namenode
2 spark
3 hadoop
4 elasticsearch
Time taken: 2.174 seconds, Fetched: 4 row(s)
hive>
# namenode 文件数据加载
hive> load data inpath 'hdfs://namenode:8020/student3.txt' into table student;
namenode 操作 上传文件数据到 hdfs
[work@Lan-Kvm-20157-Reptile2 hadoop-spark-hive]$ vim language.txt
5 java
6 php
7 python
8 shell
9 mysql
10 golang
"language.txt" [New] 6L, 48C written
# 上传文件至 hadoop 对应路径, 数据直接加载到 hadoop
# 路径在 (namenode网站/Utilities/filesystem查看) http://192.168.20.157:50070/explorer.html#/user/hive/warehouse/student
[work@Lan-Kvm-20157-Reptile2 hadoop-spark-hive]$
[work@Lan-Kvm-20157-Reptile2 hadoop-spark-hive]$ docker cp language.txt 67264de82f72:/home
root@67264de82f72:/opt# hadoop fs -put /home/language.txt /user/hive/warehouse/student
hive> drop table stu_external;
oK
Time taken : 0.188 seconds
hive> create external table stu_external(id int, name string) row format delimited fields terminated by '\t' location ' / student' ;
OK
Time taken: 0.055 seconds
点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦