
在这里主要向大家做一个 Databend 性能调优相关的分享,共会分为三次向大家介绍,如下所示:
1、基础篇:代码调优的前置知识
2、实践篇1:Databend 源码性能调优实践
3、实践篇2:Databend 的 Group By 聚合查询为什么跑的这么快?
Databend 是基于 Rust 语言开发面向云原生设计的数据仓库。Rust 是近几年比较火的系统编程语言,它具有零额外开销的抽象成本,并且有贴近 C++ 的运行性能。
但这并不意味着使用 Rust 实现的代码一定比使用 Python 实现的开发要快,在没有理解本质的情况下,Rust 依然能写出低效率的代码,这其实取决于编程人员的水平,只是 Rust 让我们更容易写出高效的代码。
下面将根据多个例子,来讲讲编程中常见的一些优化点,这些优化点多以 Rust 实现为例,但其原理可以运用在其他语言中。
本系列课程的视频回放,可以点击 https://www.bilibili.com/video/BV1zM4y1c7aW?spm_id_from=333.999.0.0 查看。
inline vs no inline
在 Rust 中,有三个 hint 去做代码的内联,如下所示:
#[inline],
#[inline(never)],
#[inline(always)]
在写代码时,我们也尽量告诉编译器我们所期望采用的方式。
内联有以下优点:
a.内联作为一种优化转换,它可以取代对函数的调用,节省代码的开销。
缺点
a. 代码二进制体积变大,使得编译时间更糟。
b. 泛型函数可能会导致内联代码膨胀.
注:
a.对于私有函数可能不需要内联,因为 LLVM 具有启发式内联。
b.私有函数具有隐式内联。
Case 1
下图所示代码展示了两段函数 default_crc32() 和 inlined_crc32(),这两段代码所实现的功能为做一个 crc32 的哈希,在 default_crc32() 是直接调用一个 crc32 fast 的哈希库,算出哈希值后,对数组进行一次遍历,得到其加总的结果;而在 inlined_crc32() 中,在 new() 函数、update() 函数加入了 inline。他们的运行时间如下:
default_crc32 time: [16.184 ms 16.196 ms 16.209 ms]
inlined_crc32 time: [1.6317 ms 1.6353 ms 1.6396 ms]
从数据中,我们可以明显的看出使用内联后性能有接近 10 倍的改善。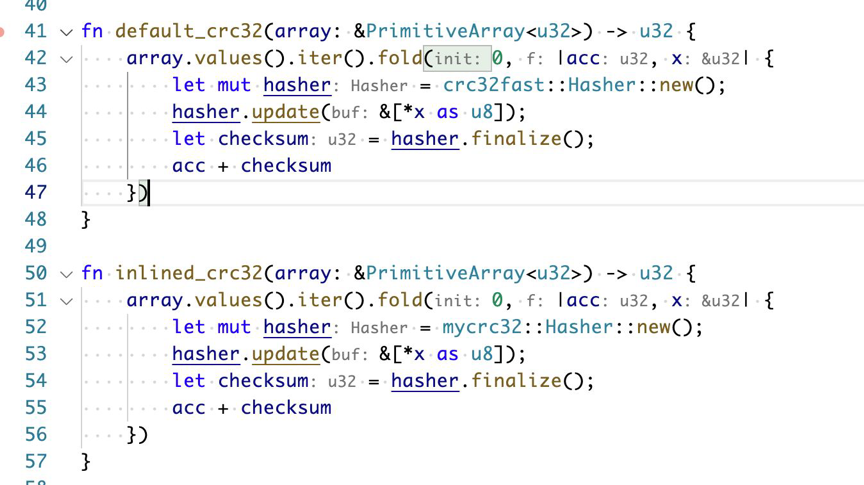
Case 2
在前面一个例子中,大家可以感受到内联对代码性能带来的提升。而不恰当的使用,同时也会让性能更差。但内联不是银弹,下面这段代码是使用了 inline(never)这段代码。当我们不使用这个 hint 时候,我们的整个函数会被编译器优化成 inline 的,进一步会导致 aggregate 里面的子函数就不会被 inline 了,但我们的程序执行耗时大多在子函数中,因为子函数中使用了 loop 循环执行 CPU 密集型操作。所以我们需要显式地告诉编译器不要 inline 外层函数,来达到 10% 左右的性能提升。
No extra allocation/copy
在写代码时候,可能会存在着一些额外的分配及拷贝。我们可以通过对其进行优化,也能提升我们代码的性能。
Case 3
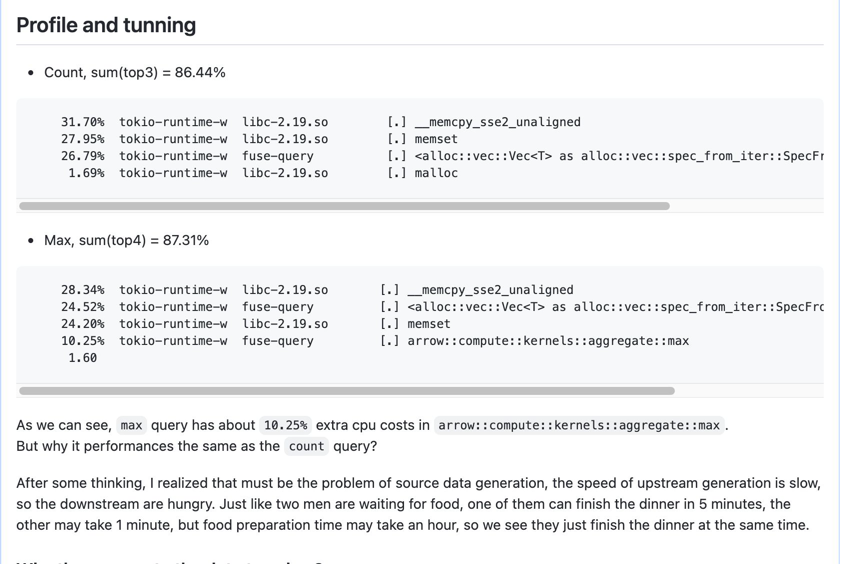
select sum(number) from numbers_mt(10000000000)
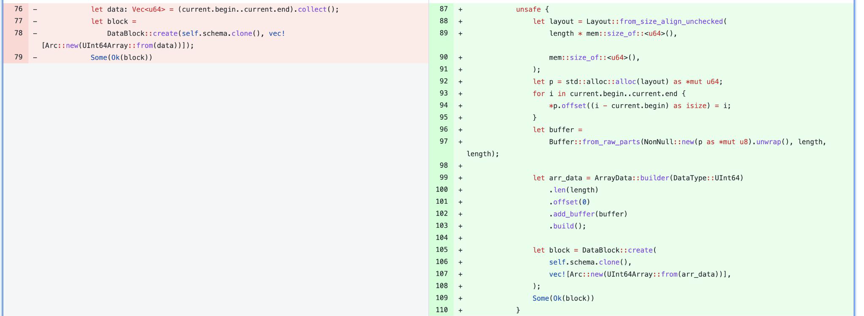
再来看第三个例子,这个例子源于 Databend 开发初期,当我们生成 numbers 表时求一个到10000000000的加总值。在这个代码中通过生成一个 Vec 的数组,我们将其转换成 Arrow 格式时,我们调用了 UInt64 Array::from() 这个函数,虽然我们将 data move 进去了,但这个函数内部还是调用了内存拷贝,通过 perf 工具可以看到 SQL 执行的开销多在内存拷贝中。
我们优化的方式是去掉多余的内存拷贝,使用了 unsafe 去生成 Arrydata,然后生成 Arrow 格式的 Array,最后让整体性能提升了 2-3 倍。
Case 4.1
cast(number as Varchar) 这个例子是将一个 NumberArray 转换成 StringArray。在左边的代码中,逻辑是遍历 NumberArray 将每行的数值转换为字符串,然后返回一个迭代器,迭代器再去生成StringArray。但这段代码产生了非常多的额外开销,由于他遍历到每一个元素时,都会产生一个局部的 Vec,这里的 Vec 是非常离散的,并且使用一次后就会被丢弃,在这里就会产生大量的小内存分配和回收,进而导致性能变差。
在第一个版本的优化中,我们在生成了一个局部的 buffer,在数值转为 string 的过程中,我们把序列化写入到这个 buffer 中,再通过 builder 去把数据 push 进 arrow 的内存格式中。这使得其性能提升至两倍,但这个 case 并没有被优化到极致。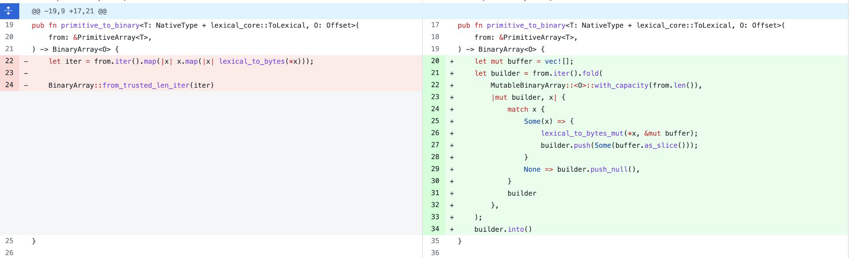
Case 4.2
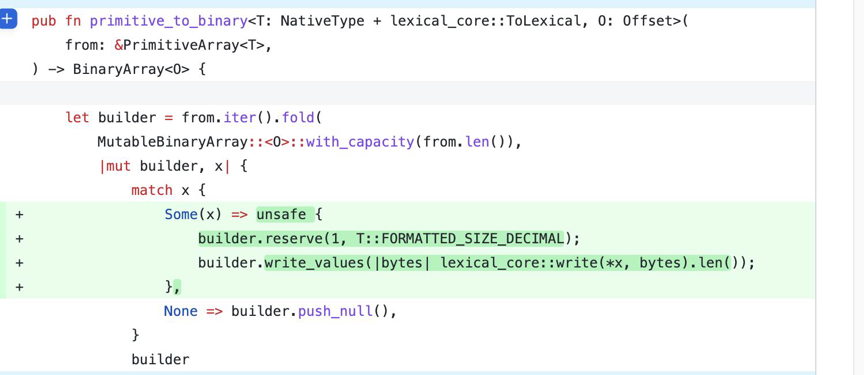
经过 Case 4.1 的优化,我们继续对其优化。因为在上述 Case 中我们用到了一个 buffer,但其实我们可以直接移除 buffer。这里我们用一个闭包函数,在数值转 String 的过程中,直接往 arrow 的内存模型中进行写入,无需额外的内存分配和拷贝,对比前一个版本,可以再提升两倍左右的性能。
Case 5
Databend 在开发的过程中,也会有一些些早期的代码写的不够好,比如我们在收集内存分配的时候,我们个 MemoryTracker 变量存储在 thread_local 中,去获取 runtime_tracker 的时候,左边的代码多了一个 Arc 的 clone,右边的代码是返回的引用,虽然clone 本身开销并不是很大,但是在 SQL 执行过程中,我们会临时地去分配很多小的内存,所以每一次分配的都会去调用这个 get 方法,就会大大降低其性能。
另外,我们还做了一次优化是,并不是每次内存分配都会去实时反馈到全局统计变量中,因为多线程去更新全局变量需要同步操作,所以我们这里做了统计值的线程内部缓冲更新,避免小内存分配统计影响性能。
Less extra function call
Case 6
下面的例子是 Arrow 中的一个排序函数,例如在 SQL:
排序的列是 a,但其余的列也要跟着 a 的顺序走,arrow 的执行流程是先将索引按照 a 进行排序,下面的例子就是索引排序的过程,排序我们需要按照 a 列在不同 index 中的值进行比较,然后根据结果决定是否交换 index。
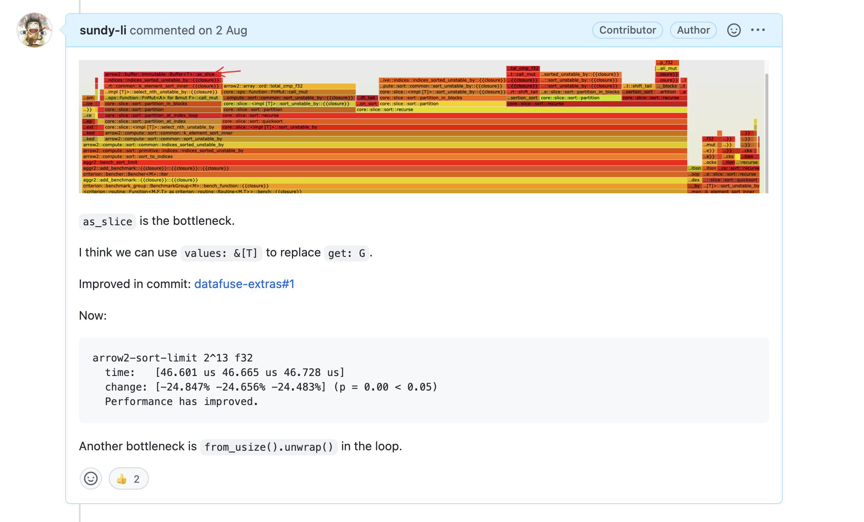
左边的实现是闭包捕获了array,但我们根据 index 那对应的值需要调用 array.values().as_slice().get_unchecked(), 这里有 3 次函数调用,如果 array 的长度很长,这个调用开销的放大是非常可观的。我们的优化过程也非常简单,我们把 values 先引用到一个变量中,之后闭包就会直接去捕获 values。这个优化大约可以达到 25% 的性能提升。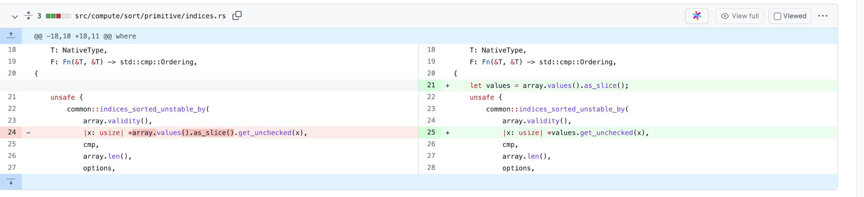
Less branch prediction miss
大家应该都熟悉分支预测可以利用 CPU 乱序执行来提升性能。但是分支预测失败了,返回会大大影响性能性能 。请大家来看以下的几个例子。
Case 7
下面的例子是在一个循环中,每次循环都会调用 unwrap 函数,这个 unwrap 函数在 Rust 其实就是一次 if else 封装,因此这里会有分支预测的开销。分支预测通常来说是有缓存的,但在这个函数中,分支预测的缓存似乎工作的不太友好。
对他优化的方式是迭代器生成封装到一个方法中,从而去除多余的分支预测。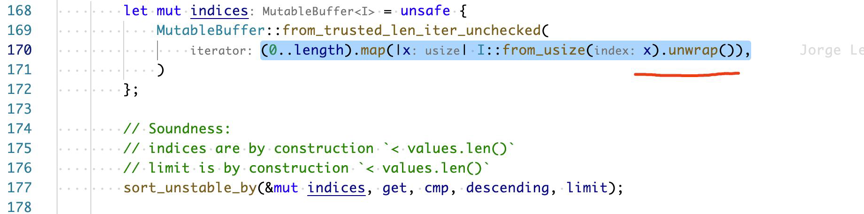

Case 8
这个例子是 abs 函数的实现。在这里我们是去对 int8 这个函数进行一次遍历并求绝对值,map 判断了 null 的情况,如果原始值是 null,结果依然需要为 null。Arrow 的内存模型是有两个 array 的,它的第一个 array 是一个 int8 的数组,第二个 array 是一个 bitmap。我们的优化方式是先忽略 null,直接遍历 int8 数组,进行 abs 的 transform,然后将输入的 bitmap 进行 clone 给结果数组,从而去除了分支预测。由于类似函数会很多,所以我们封装了多个 apply 函数进行数组到数组的转换。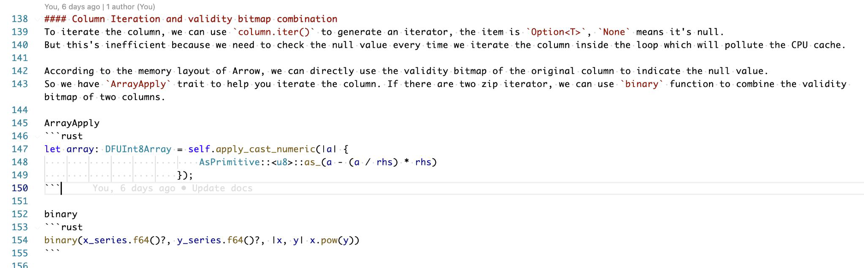
Case 9
这里来自 ClickHouse 的一个例子。
SQL:
这个 SQL 通常会有 2 个分支预测,一个判断 number > 3,第二个判断 number 是否有 null 值。在向量化 sum 中,我们用一些位操作来优化分支开销。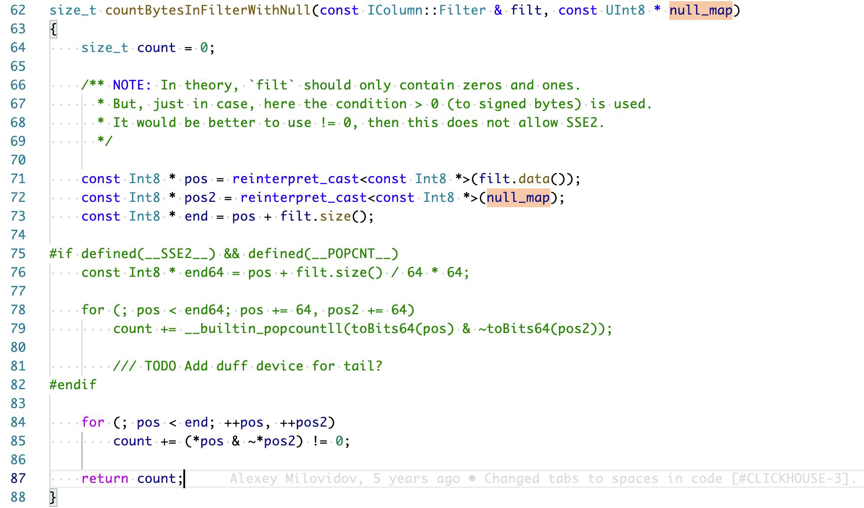
SIMD
SIMD 指的是单指令多数据执行。接下来我们会讲到两个关于 simd 的例子。
Case 10:simd sum
在我们的列数据库中,非常常用的就是向量化执行。首先,我们先来看第一段代码,做的是对 double 数组的一次求和。理想化的情况的是,我们的 CPU 执行的如果最佳流水线,ADD 执行的次数是 N 次。
现代的 CPU 中通常有一些特殊的优化指令集,比如 SSE,AVX,通过这些指令对数据进行批量的求和,这样可以让整体性能提升至 4 倍左右。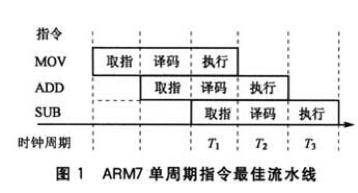
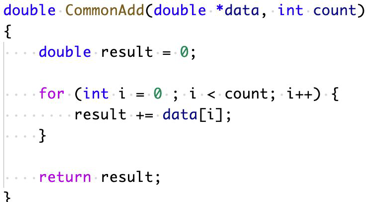

AVXAdd 的函数实现看起来比较丑陋,通常来说我们不需要显示的使用 AVXAdd,因为现代的编译器已经足够智能优化上面的代码成 AVXAdd 方式执行了,比如 GCC 的自动向量化。
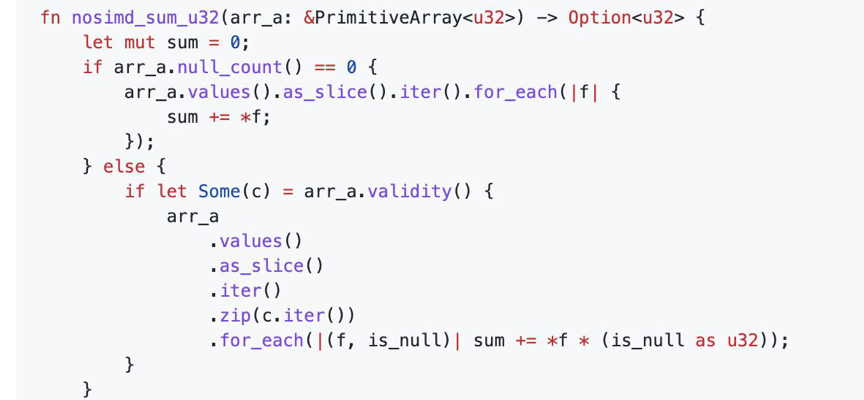
Case 11: null sum in arrow2
求和运算中,我们通常要忽略 null 值,这样可能会破坏自动向量化的优化,因为 null 值是 runtime 才能感知的。Rust有一些向量化的 crate 非常有用,比如说 Arrow2 中使用了packed_simd2, Rust 也即将迎来标准的 simd 库。下面的例子是对含有 null 值得数组求和向量化代码。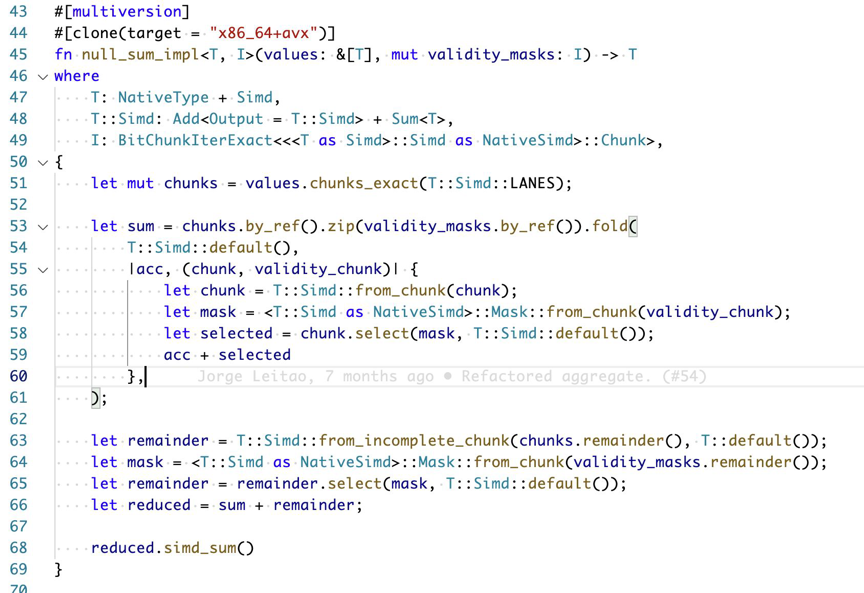
整体的原理是将数据按 chunk 分桶在一个 simd 位宽中,然后运用向量化的 select 将非 null 的值抽出到一个新的 selected 中求和。
自动向量化
通常来说,我们不会主动编写向量化的代码,而是让循环中的逻辑尽量简单 (不引入分支),编译器往往能给我们优化出高效的代码,比如在 not nullable 的 array 中进行求和,自动向量化的代码反而比手动向量化的代码更加高效。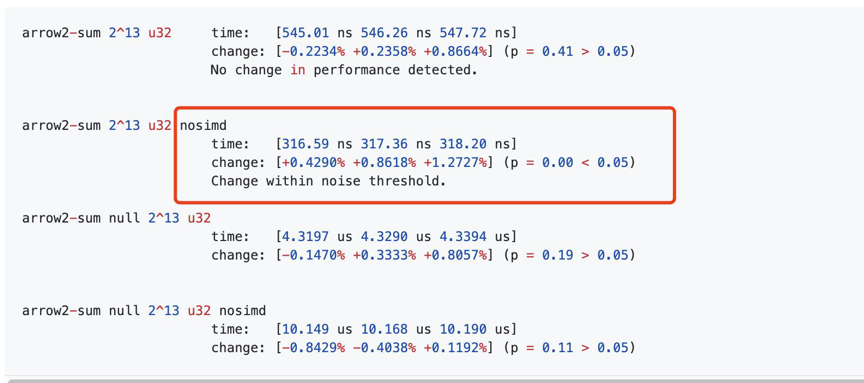
通过以上的 11 个例子,希望你已经对代码调优有了更深入的了解,在下一次的分享中我们将介绍 Databend 的 group by 查询为什么能跑的这么快。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



