
大家好,我是我是皮皮。
一、前言
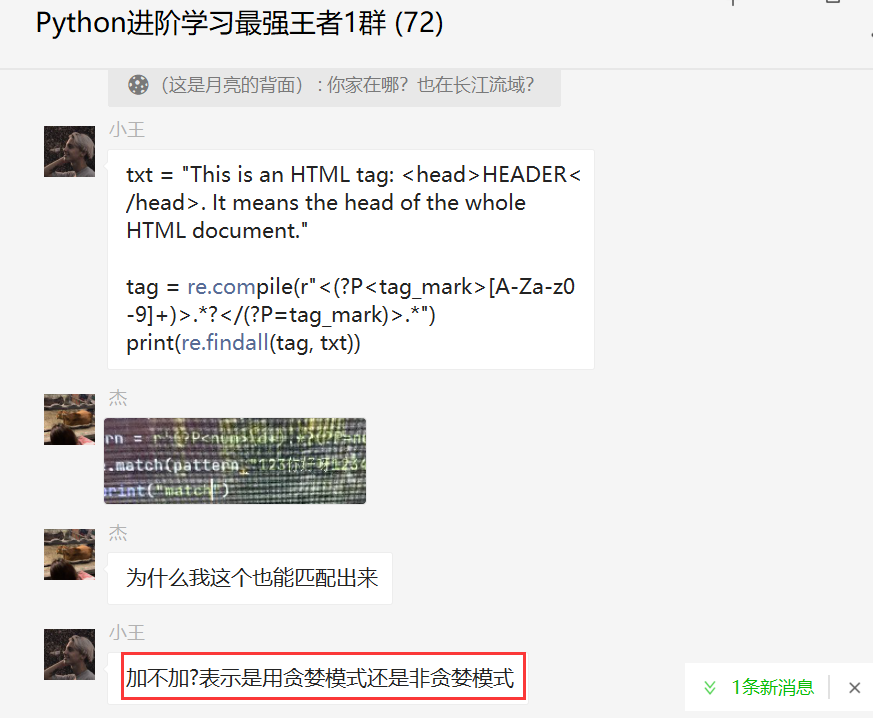
前几天在Python最强王者交流群有个叫【杰】的粉丝问了一个关于Python正则表达式的问题,其中涉及到Python正则表达式中的贪婪模式和非贪婪模式,讨论十分火热,这里拿出来给大家分享下,一起学习。
二、解决过程
这里分享【小王】大佬的解答,一起来看看吧,下面是他给的一个示例代码。
import re
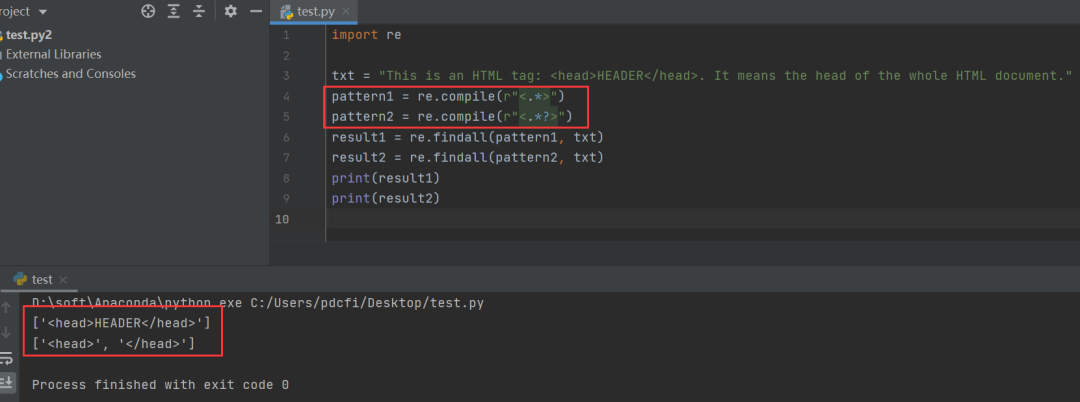
txt = "This is an HTML tag: <head>HEADER</head>. It means the head of the whole HTML document."
pattern1 = re.compile(r"<.*>")
pattern2 = re.compile(r"<.*?>")
result1 = re.findall(pattern1, txt)
result2 = re.findall(pattern2, txt)
print(result1)
print(result2)
输出结果如下图所示:
关于输出的解析如下:
我想匹配HTML标签中的数据,也就是<>之间的数据。
pattern1 = re.compile(r"<.*>")
pattern2 = re.compile(r"<.*?>")
这两种只相差了一个?,但是区别却很大。解析如下图所示:
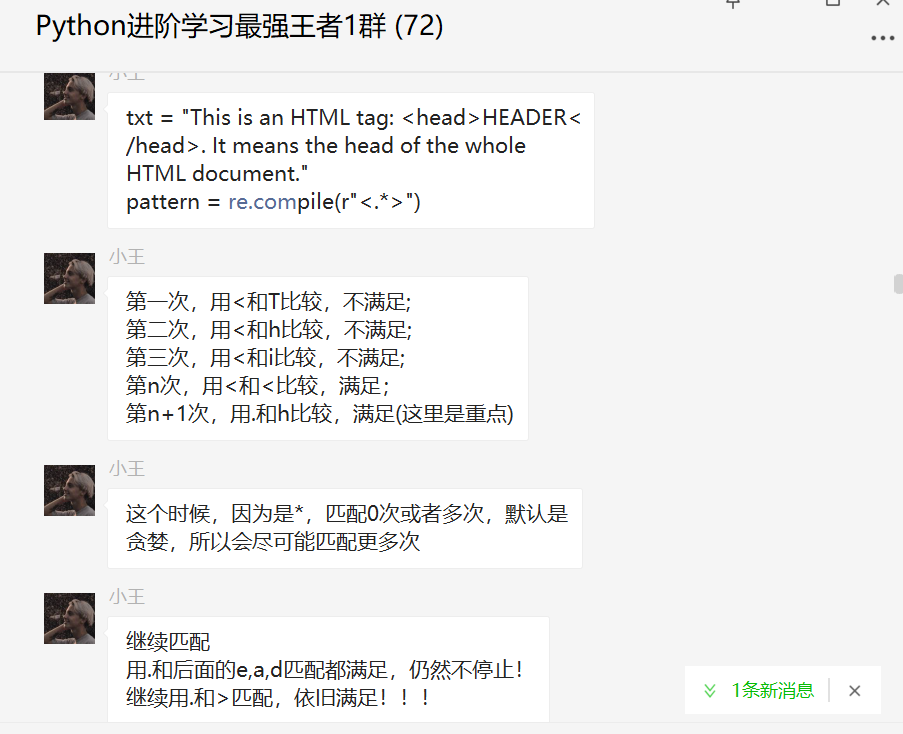
直到什么时候停止呢?
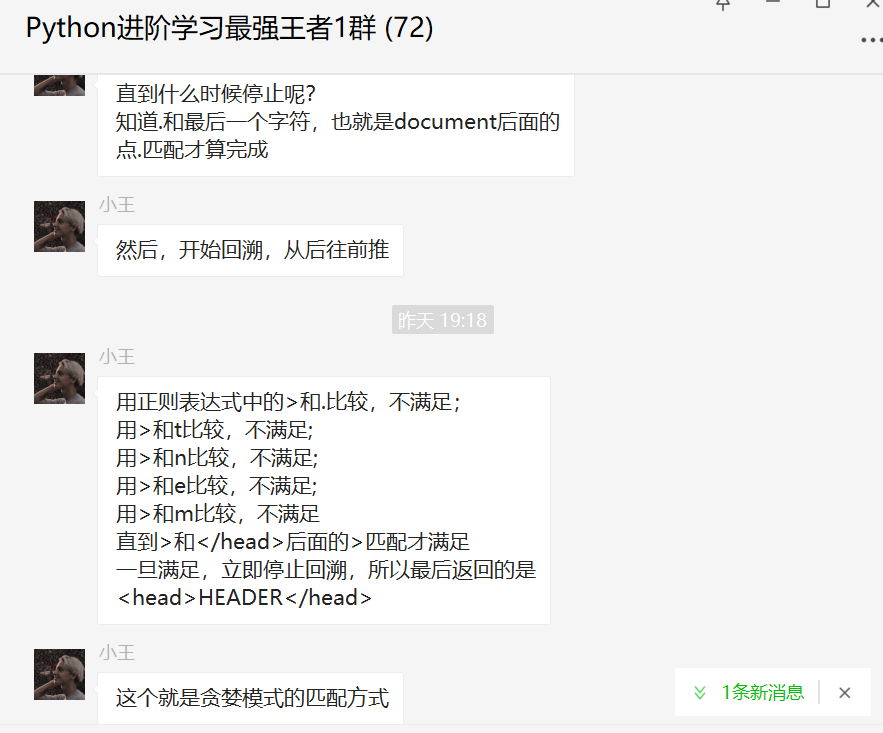
这个就是贪婪模式的匹配方式,那么非贪婪模式呢?
小彩蛋
分享一个【小王】大佬的代码,实现的效果是将正则匹配结果写成命名分组Python代码。
常规写法如下所示:
import re
txt = "This is an HTML tag: <head>HEADER</head>. It means the head of the whole HTML document."
tag = re.compile(r"<([A-Za-z0-9]+)>.*?</\1>.*")
print(re.findall(tag, txt))
写成命名分组的写法如下所示:
txt = "This is an HTML tag: <head>HEADER</head>. It means the head of the whole HTML document."
tag = re.compile(r"<(?P<tag_mark>[A-Za-z0-9]+)>.*?</(?P=tag_mark)>.*")
print(re.findall(tag, txt))
总结
大家好,我是皮皮。这篇文章基于粉丝提问,针对Python正则表达式中的贪婪模式和非贪婪模式问题,给出了具体说明和演示,顺利的帮助粉丝解决了问题。
最后感谢粉丝【杰】提问,感谢【小王】大佬给出的解答和示例,感谢【(这是月亮的背面)】、【dcpeng】、【wangning】、【Chloé P.】等大佬们参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦