
背景
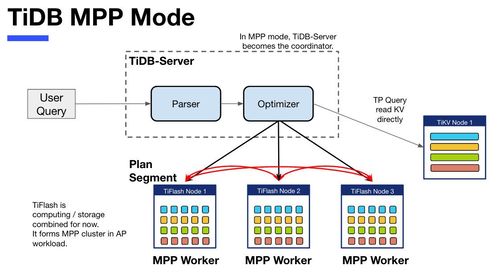
本系列会聚焦在 TiFlash 自身,读者需要有一些对 TiDB 基本的知识。可以通过这三篇文章了解 TiDB 体系里的一些概念《 说存储 》、《 说计算 》、《 谈调度 》。
今天的主角 -- TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,通过 Raft Learner 协议异步复制,但提供与 TiKV 一样的快照隔离支持。我们用这个架构解决了 HTAP 场景的隔离性以及列存同步的问题。自 5.0 引入 MPP 后,也进一步增强了 TiDB 在实时分析场景下的计算加速能力。
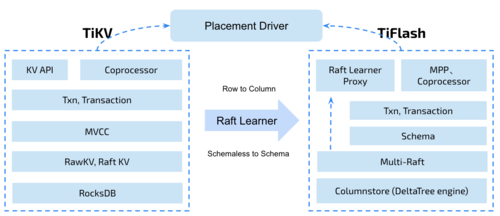
上图描述了 TiFlash 整体逻辑模块的划分,通过 Raft Learner Proxy 接入到 TiDB 的 multi-raft 体系中。我们可以对照着 TiKV 来看:计算层的 MPP 能够在 TiFlash 之间做数据交换,拥有更强的分析计算能力;作为列存引擎,我们有一个 schema 的模块负责与 TiDB 的表结构进行同步,将 TiKV 同步过来的数据转换为列的形式,并写入到列存引擎中;最下面的一块,是稍后会介绍的列存引擎,我们将它命名为 DeltaTree 引擎。
有持续关注 TiDB 的用户可能之前阅读过 《TiDB 的列式存储引擎是如何实现的?》 这篇文章,近期随着 TiFlash 开源 ,也有新的用户想更多地了解 TiFlash 的内部实现。这篇文章会从更接近代码层面,来介绍 TiFlash 内部实现的一些细节。
这里是 TiFlash 内一些重要的模块划分以及它们对应在代码中的位置。在今天的分享和后续的系列里,会逐渐对里面的模块开展介绍。
# TiFlash 模块对应的代码位置 dbms/ └── src ├── AggregateFunctions, Functions, DataStreams # 函数、算子 ├── DataTypes, Columns, Core # 类型、列、Block ├── IO, Common, Encryption # IO、辅助类 ├── Debug # TiFlash Debug 辅助函数 ├── Flash # Coprocessor、MPP 逻辑 ├── Server # 程序启动入口 ├── Storages │ ├── IStorage.h # Storage 抽象 │ ├── StorageDeltaMerge.h # DeltaTree 入口 │ ├── DeltaMerge # DeltaTree 内部各个组件 │ ├── Page # PageStorage │ └── Transaction # Raft 接入、Scehma 同步等。 待重构 https://github.com/pingcap/tiflash/issues/4646 └── TestUtils # Unittest 辅助类
TiFlash 中的一些基本元素抽象
TiFlash 这款引擎的代码是 18 年从 ClickHouse fork。ClickHouse 为 TiFlash 提供了一套性能十分强劲的向量化执行引擎,我们将其当做 TiFlash 的单机的计算引擎使用。在此基础上,我们增加了针对 TiDB 前端的对接,MySQL 兼容,Raft 协议和集群模式,实时更新列存引擎,MPP 架构等等。虽然和原本的 Clickhouse 已经完全不是一回事,但代码自然地 TiFlash 代码继承自 ClickHouse,也沿用着 CH 的一些抽象。比如:
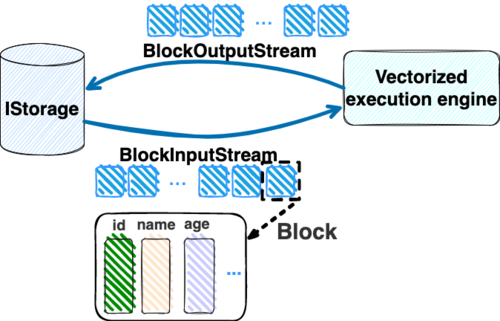
IColumn 代表内存里面以列方式组织的数据。IDataType 是数据类型的抽象。Block 则是由多个 IColumn 组成的数据块,它是执行过程中,数据处理的基本单位。
在执行过程中,Block 会被组织为流的形式,以 BlockInputStream 的方式,从存储层 “流入” 计算层。而 BlockOutputStream,则一般从执行引擎往存储层或其他节点 “写出” 数据。
IStorage 则是对存储层的抽象,定义了数据写入、读取、DDL 操作、表锁等基本操作。
DeltaTree 引擎
虽然 TiFlash 基本沿用了 CH 的向量化计算引擎,但是存储层最终没有沿用 CH 的 MergeTree 引擎,而是重新研发了一套更适合 HTAP 场景的列存引擎,我们称为 DeltaTree,对应代码中的 " StorageDeltaMerge "。
DeltaTree 引擎解决的是什么问题
A. 原生支持高频率数据写入,适合对接 TP 系统,更好地支持 HTAP 场景下的分析工作。
B. 支持列存实时更新的前提下更好的读性能。它的设计目标是优先考虑 Scan 读性能,相对于 CH 原生的 MergeTree 可能部分牺牲写性能
C. 符合 TiDB 的事务模型,支持 MVCC 过滤
D. 数据被分片管理,可以更方便的提供一些列存特性,从而更好的支持分析场景,比如支持 rough set index
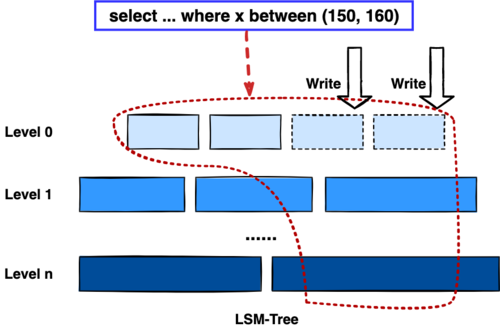
为什么我们说 DeltaTree 引擎具备上面特性呢🤔 ?回答这个疑问之前,我们先回顾下 CH 原生的 MergeTree 引擎存在什么问题。MergeTree 引擎可以理解为经典的 LSM Tree(Log Structured Merge Tree)的一种列存实现,它的每个 "part 文件夹" 对应 SSTFile(Sorted Strings Table File)。最开始,MergeTree 引擎是没有 WAL 的,每次写入,即使只有 1 条数据,也会将数据需要生成一个 part。因此如果使用 MergeTree 引擎承接高频写入的数据,磁盘上会形成大量碎片的文件。这个时候,MergeTree 引擎的写入性能和读取性能都会出现严重的波动。这个问题直到 2020 年,CH 给 MergeTree 引擎引入了 WAL,才部分缓解这个压力 ClickHouse/8290 。
那么是不是有了 WAL,MergeTree 引擎就可以很好地承载 TiDB 的数据了呢?还不足够。因为 TiDB 是一个通过 MVCC 实现了 Snapshot Isolation 级别事务的关系型数据库。这就决定了 TiFlash 承载的负载会有比较多的数据更新操作,而承载的读请求,都会需要通过 MVCC 版本过滤,筛选出需要读的数据。而以 LSM Tree 形式组织数据的话,在处理 Scan 操作的时候,会需要从 L0 的所有文件,以及其他层中 与查询的 key-range 有 overlap 的所有文件,以堆排序的形式合并、过滤数据。在合并数据的这个入堆、出堆的过程中, CPU 的分支经常会 miss,cache 命中也会很低。测试结果表明,在处理 Scan 请求的时候,大量的 CPU 都消耗在这个堆排序的过程中。
另外,采用 LSM Tree 结构,对于过期数据的清理,通常在 level compaction 的过程中,才能被清理掉(即 Lk-1 层与 Lk 层 overlap 的文件进行 compaction)。而 level compaction 的过程造成的写放大会比较严重。当后台 compaction 流量比较大的时候,会影响到前台的写入和数据读取的性能,造成性能不稳定。
MergeTree 引擎上面的三点:写入碎片、Scan 时 CPU cache miss 严重、以及清理过期数据时的 compaction ,造成基于 MergeTree 引擎构建的带事务的存储引擎,在有数据更新的 HTAP 场景下,读、写性能都会有较大的波动。
DeltaTree 的解决思路以及模块划分
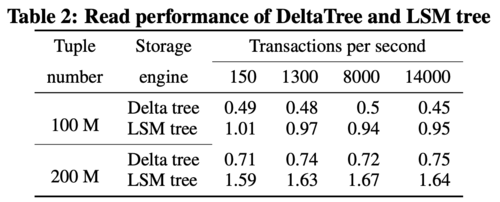
在看实现之前,我们来看看 DeltaTree 的疗效如何。上图是 Delta Tree 与基于 MergeTree 实现的带事务支持的列存引擎在不同数据量(Tuple number)以及不同更新 TPS (Transactions per second) 下的读 (Scan) 耗时对比。可以看到 DeltaTree 在这个场景下的读性能基本能达到后者的两倍。
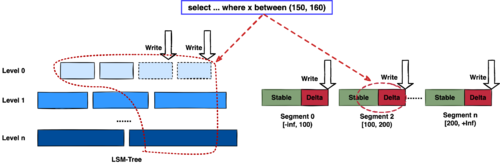
那么 DeltaTree 具体面对上述问题,是如何设计的呢?
首先,我们在表内,把数据按照 handle 列的 key-range,横向分割进行数据管理,每个分片称为 Segment。这样在 compaction 的时候,不同 Segment 间的数据就独立地进行数据整理,能够减少写放大。这方面与 PebblesDB[1] 的思路有点类似。
另外,在每个 Segment 中,我们采用了 delta-stable 的形式,即最新的修改数据写入的时候,被组织在一个写优化的结构的末尾( DeltaValueSpace.h ),定期被合并到一个为读优化的结构中( StableValueSpace.h )。Stable Layer 存放相对老的,数据量较大的数据,它不能被修改,只能被 replace。当 Delta Layer 写满之后,与 Stable Layer 做一次 Merge(这个动作称为 Delta Merge),从而得到新的 Stable Layer,并优化读性能。很多支持更新的列存,都是采用类似 delta-stable 这种形式来组织数据,比如 Apache Kudu[2]。有兴趣的读者还可以看看《Fast scans on key-value stores》[3] 的论文,其中对于如何组织数据,MVCC 数据的组织、对过期数据 GC 等方面的优劣取舍都做了分析,最终作者也是选择了 delta-main 加列存这样的形式。
Delta Layer 的数据,我们通过一个 PageStorage 的结构来存储数据,Stable Layer 我们主要通过 DTFile 来存储数据、通过 PageStorage 来管理生命周期。另外还有 Segment、DeltaValueSpace、StableValueSpace 的元信息,我们也是通过 PageStorage 来存储。上面三者分别对应 DeltaTree 中 StoragePool 这一数据结构的 log, data 以及 meta。
PageStorage 模块
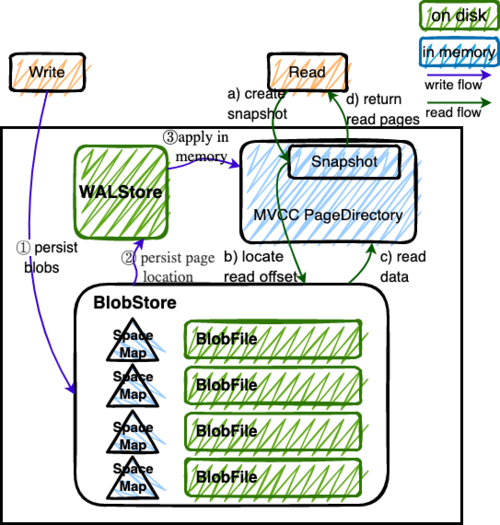
上面提到, Delta Layer 的数据和 DeltaTree 存储引擎的一些元数据,这类较小的数据块,在序列化为字节串之后,作为 "Page" 写入到 PageStorage 来进行存储。PageStorage 是 TiFlash 中的一个存储的抽象组件,类似对象存储。它主要设计面向的场景是 Delta Layer 的高频读取:比如在 snapshot 上,以 PageID (或多个 PageID) 做点查的场景;以及相对于 Stable Layer 较高频的写入。PageStorage 层的 "Page" 数据块典型大小为数 KiB~MiB。
PageStorage 是一个比较复杂的组件,今天先不介绍它内部的构造。读者可以先理解 PageStorage 至少提供以下 3 点功能:
提供 WriteBatch 接口,保证写入 WriteBatch 的原子性
提供 Snapshot 功能,可以获取一个不阻塞写的只读 view
提供读取 Page 内部分数据的能力(只读选择的列数据)
读索引 DeltaTree Index
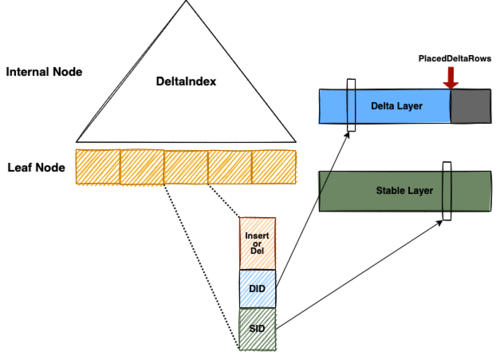
前面提到,在 LSM-Tree 上做多路归并比较耗 CPU,那我们是否可以避免每次读都要重新做一次呢?答案是可以的。事实上有一些内存数据库已经实践了类似的思路。具体的思路是,第一次 Scan 完成后,我们把多路归并算法产生的信息想办法存下来,从而使下一次 Scan 可以重复利用。这份可以被重复利用的信息我们称为 Delta Index,它由一棵 B+ Tree 实现。利用 Delta Index,把 Delta Layer 和 Stable Layer 合并到一起,输出一个排好序的 Stream。Delta Index 帮助我们把 CPU bound、而且存在很多 cache miss 的 merge 操作,转化为大部分情况下一些连续内存块的 copy 操作,进而优化 Scan 的性能。
Rough Set Index
很多数据库都会在数据块上加统计信息,以便查询时可以过滤数据块,减少不必要的 IO 操作。有的将这个辅助的结构称为 KnowledgeNode、有的叫 ZoneMaps。TiFlash 参考了 InfoBright [4] 的开源实现,采用了 Rough Set Index 这个名字,中文叫粗粒度索引。
TiFlash 给 SelectQueryInfo 结构中添加了一个 MvccQueryInfo 的结构,里面会带上查询的 key-ranges 信息。DeltaTree 在处理的时候,首先会根据 key-ranges 做 segment 级别的过滤。另外,也会从 DAGRequest 中将查询的 Filter 转化为 RSFilter 的结构,并且在读取数据时,利用 RSFilter,做 ColumnFile 中数据块级别的过滤。
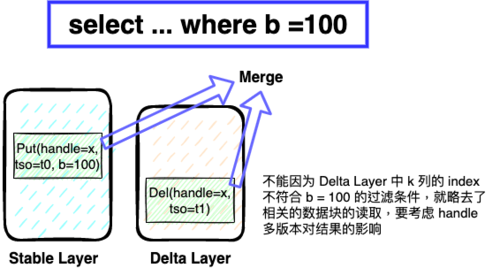
在 TiFlash 内做 Rough Set Filter,跟一般的 AP 数据库不同点,主要在还需要考虑粗粒度索引对 MVCC 正确性的影响。比如表有三列 a、b 以及写入的版本 tso,其中 a 是主键。在 t0 时刻写入了一行 Insert (x, 100, t0),它在 Stable VS 的数据块中。在 t1 时刻写入了一个删除标记 Delete(x, 0, t1),这个标记存在 Delta Layer 中。这时候来一个查询 select * from T where b = 100,很显然如果我们在 Stable Layer 和 Delta Layer 中都做索引过滤,那么 Stable 的数据块可以被选中,而 Delta 的数据块被过滤掉。这时候就会造成 (x, 100, t0) 这一行被错误地返回给上层,因为它的删除标记被我们丢弃了。
因此 TiFlash Delta layer 的数据块,只会应用 handle 列的索引。非 handle 列上的 Rough Set Index 主要应用于 Stable 数据块的过滤。一般情况下 Stable 数据量占 90%+,因此整体的过滤效果还不错。
代码模块
下面是 DeltaTree 引擎内各个模块对应的代码位置,读者可以回忆一下前文,它们分别对应前文的哪一部分 ;)
# DeltaTree 引擎内各模块对应的代码位置 dbms/src/Storages/ ├── Page # PageStorage └── DeltaMerge ├── DeltaMergeStore.h # DeltaTree 引擎的定义 ├── Segment.h # Segment ├── StableValueSpace.h # Stable Layer ├── Delta # Delta Layer ├── DeltaMerge.h # Stable 与 Delta merge 过程 ├── File # Stable Layer 的存储格式 ├── DeltaTree.h, DeltaIndex.h # Delta Index ├── Index, Filter, FilterParser # Rough Set Filter └── DMVersionFilterBlockInputStream.h # MVCC Filtering
小结
本篇文章主要介绍了 TiFlash 整体的模块分层,以及在 TiDB 的 HTAP 场景下,存储层 DeltaTree 引擎如何进行优化的思路。简单介绍了 DeltaTree 内组件的构成和作用,但是略去了一些细节,比如 PageStorage 的内部实现,DeltaIndex 如何构建、应对更新,TiFlash 是如何接入 multi-Raft 等问题。更多的代码阅读内容会在后面的章节中逐步展开,敬请期待。
体验全新的一栈式实时 HTAP 数据库,即刻注册 TiDB Cloud,免费试用 TiDB Developer Tier 一年。
适用于中国出海企业和开发者
相关文章
[1] SOSP'17: PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees
[2] Kudu: Storage for Fast Analytics on Fast Data
[3] VLDB'17: Fast scans on key-value stores
[4] Brighthouse: an analytic data warehouse for ad-hoc queries
共同学习,写下你的评论
评论加载中...
作者其他优质文章



