
本教程是系列教程,对于初学者可以对 ES 有一个整体认识和实践实战。
还没开始的同学,建议先读一下系列攻略目录:[Springboot2.x整合ElasticSearch7.x实战目录]
本篇幅是继上一篇 [Springboot2.x整合ElasticSearch7.x实战(一)],适合初学 Elasticsearch 的小白,可以跟着整个教程做一个练习。
第三章 分词器安装
使用搜索,少不了使用分词器,elasticsearch 自带了一些简单分词器,也可以使用第三方分词器插件,如 ik、pinyin 等。
Standard Analyzer - 默认分词器,按词切分,小写处理
Simple Analyzer - 按照非字母切分(符号被过滤), 小写处理
Stop Analyzer - 小写处理,停用词过滤(the,a,is)
Whitespace Analyzer - 按照空格切分,不转小写
Keyword Analyzer - 不分词,直接将输入当作输出
Patter Analyzer - 正则表达式,默认\W+(非字符分割)
Language - 提供了30多种常见语言的分词器
Customer Analyzer 自定义分词器
ik分词器插件安装
- 下载和elasticsearch版本一致
教程使用的是 7.7.0 版本。
- 准备 ik 目录,
cd plugins && mkdir ik
- 下载
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip
有些地方从github下载网络不好,我在课件里有插件压缩包。
- 解压到对应ik目录
解压文件到目录 elasticsearch-7.7.0/plugins/ik 下。
- 重启es,查看是否安装成功
rest 实例:
拼音分词器插件安装
- 下载和elasticsearch版本一致
教程使用的是 7.7.0 版本。
- 准备 ik 目录,
cd plugins && mkdir pinyin
- 下载
wget https://github.com/medcl/elasticsearch-analysis-pinyin/archive/v7.7.0.zip
有些地方从github下载网络不好,我在课件放了插件的压缩包。
- 解压到对应pinyin目录
解压文件到目录 elasticsearch-7.7.0/plugins/pinyin 下。
- 重启es,查看是否安装成功
更多扩展词库
- 同义词词库
有些情况会使用我们自己的分词服务,后面代码中会讲解使用方式。
第四章 Elasticsearch核心概念
Elasticsearch核心概念-相关术语解析
Cluster
Elasticsearch 集群,由一台或多台的Elasticsearch 节点(Node)组成。
Node
Elasticsearch 节点,可以认为是Elasticsearch的服务进程,在同一台机器上启动两个Elasticsearch实例(进程),就是两个node节点。
Index
索引,具有相同结构的文档的集合,类似于关系型数据库的数据库实例(6.0.0版本type废弃后,索引的概念下降到等同于数据库表的级别)。一个集群中可以有多个索引。
Type
类型,在索引中内进行逻辑细分,在新版的Elasticsearch中已经废弃。
关于 type 废弃问题,如果你需要维护低版本 elasticsearch(在7.0.0、6.*、5.6版本变化较大),一定要阅读这篇官方英文文档 https://www.elastic.co/guide/en/elasticsearch/reference/current/removal-of-types.html
Document
文档,Elasticsearch中的最小的数据存储单元,JSON数据格式,很多相同结构的文档组成索引。文档类似于关系型数据库中表内的一行记录。
举个例子,一篇新闻的文档数据。
news document
{
"id":"1",
"title":"China is a great country",
"content":"I love China."
}
Shard
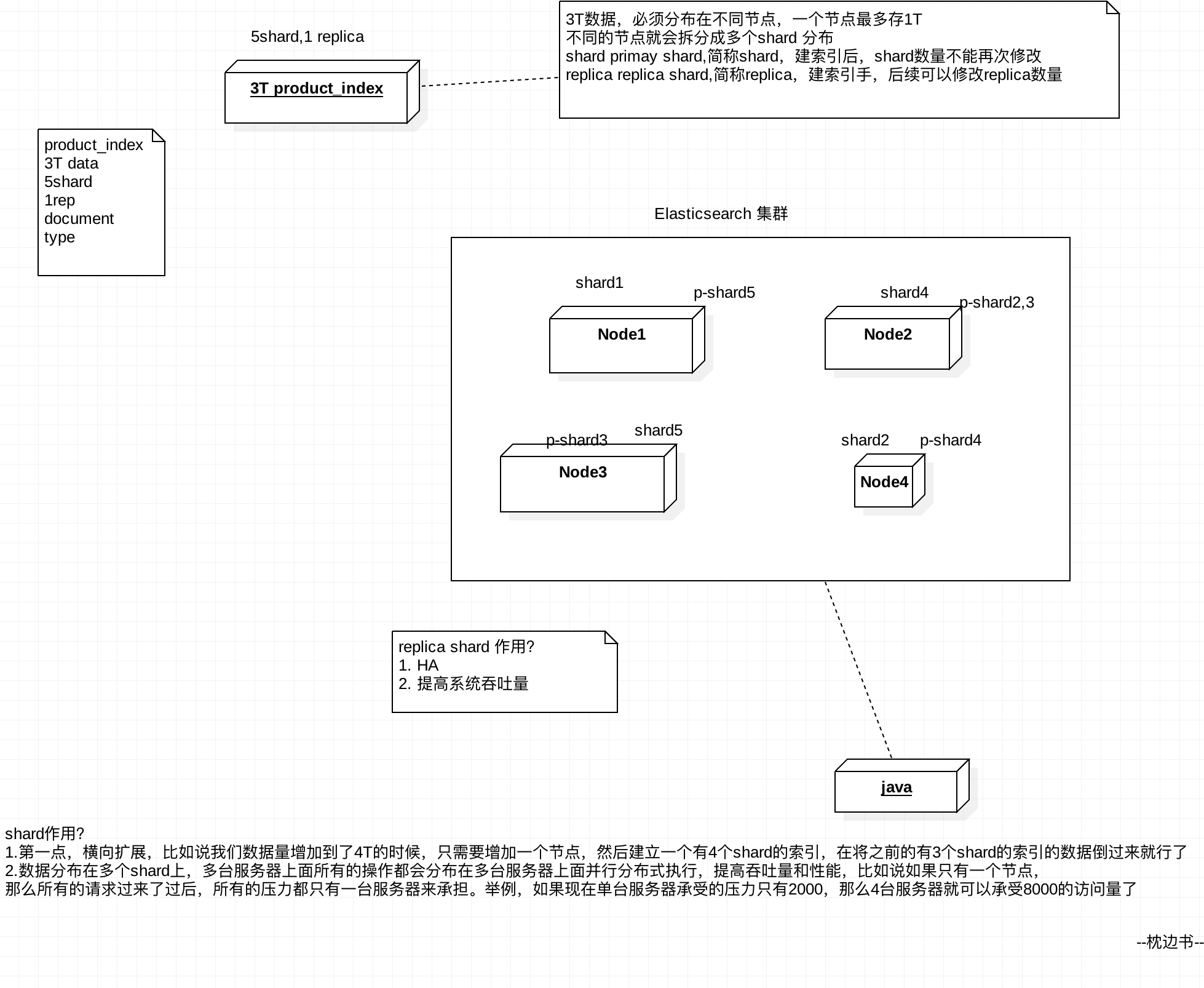
分片,单个索引切分成多个shard,分布在多台Node节点上存储。可以利用shard很好的横向扩展,以存储更多的数据,同时shard分布在多台node上,可以提升集群整体的吞吐量和性能。在创建索引的时候可以直接指定分片的数量即可,一旦指定就不能再修改了。
Replica
索引副本,完全拷贝shard的内容,一个shard可以有一个或者多个replica,replica就是shard的数据拷贝,以提高冗余。
replica承担三个任务:
- shard故障或者node宕机时,其中的一个replica可以升级成shard
- replica保证数据不丢失,保证高可用
- replica可以分担搜索请求,提高集群的吞吐和性能
shard 的全称叫 primary shard,replica 全称叫 replica shard,primary shard 数量在创建索引时指定,后期不能修改,replica shard 后期可以修改。默认每个索引的 primary shard 值为5,replica shard 值为1,含义是5个primary shard,5个 replica shard,共10个 shard。因此 Elasticsearch 最小的高可用配置是2台服务器。
理解倒排索引
例如倒排索引等内容
倒排索引相关术语
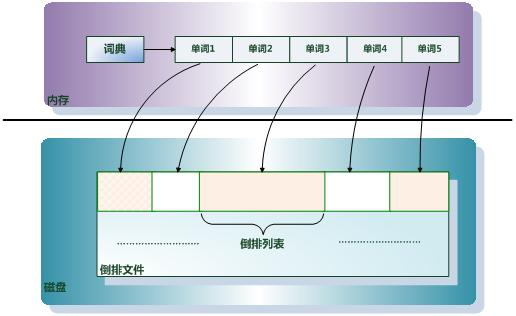
倒排索引(Inverted Index)是整个搜索的核心,倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
单词词典(Lexicon):常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
概念关系:
简单倒排索引实例
倒排索引从逻辑结构和基本思路上来讲非常简单。下面我们通过具体实例来进行说明,使得大家能够对倒排索引有一个宏观而直接的感受。
假设有五个文档:
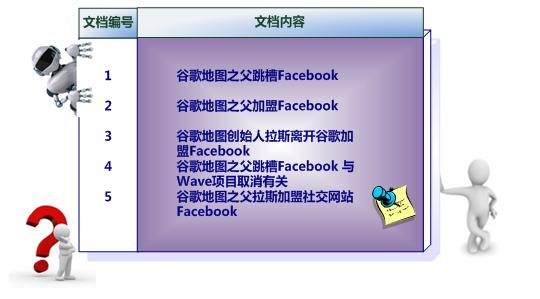
通过分词后,每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引。
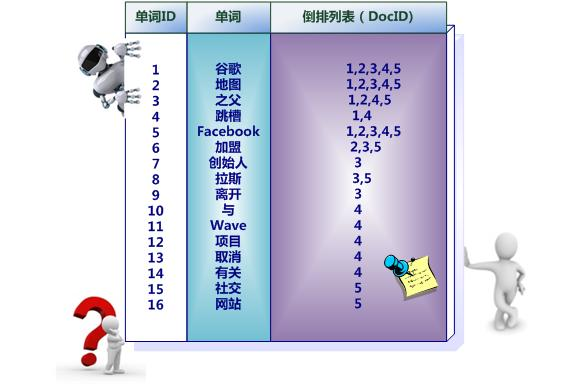
事实上,索引系统还可以记录除此之外的更多信息。下图是一个相对复杂些的倒排索引,与上图的基本索引系统比,在单词对应的倒排列表中不仅记录了文档编号,还记载了单词频率信息(TF),即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算。
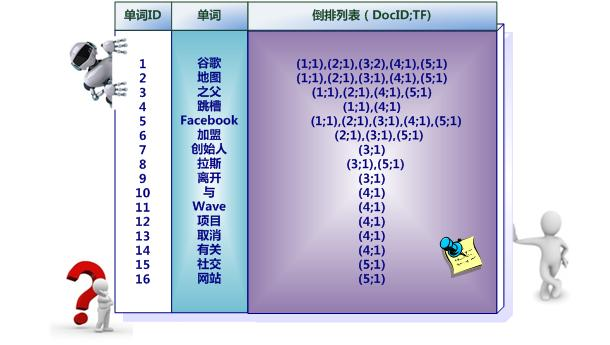
最后,实用的倒排索引还可以记载更多的信息,上图所示索引系统除了记录文档编号和单词频率信息外,额外记载了两类信息,即每个单词对应的“文档频率信息”(以及在倒排列表中记录单词在某个文档出现的位置信息。
“文档频率信息”代表了在文档集合中有多少个文档包含某个单词,之所以要记录这个信息,其原因与单词频率信息一样,这个信息在搜索结果排序计算中是非常重要的一个因子。而单词在某个文档中出现的位置信息并非索引系统一定要记录的,在实际的索引系统里可以包含,也可以选择不包含这个信息,之所以如此,因为这个信息对于搜索系统来说并非必需的,位置信息只有在支持“短语查询”的时候才能够派上用场。
在看和分享是对我最大的鼓励,我是 pub 哥,我们下期再见
共同学习,写下你的评论
评论加载中...
作者其他优质文章



