
课程名称:Scrapy打造搜索引擎(分布式爬虫)
课程章节:Scrapy爬取知名技术文章网站
主讲老师:bobby
课程内容:
今天学习的内容包括:Scrapy安装与配置、xpath基础语法、xpath提取元素、css选择器
课程收获:
Scrapy安装与配置:
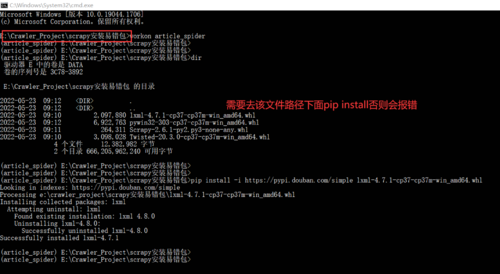
1.scrapy安装出错?
https://www.lfd.uci.edu/~gohlke/pythonlibs/
进入该网址下载出错的包,然后手动本地安装
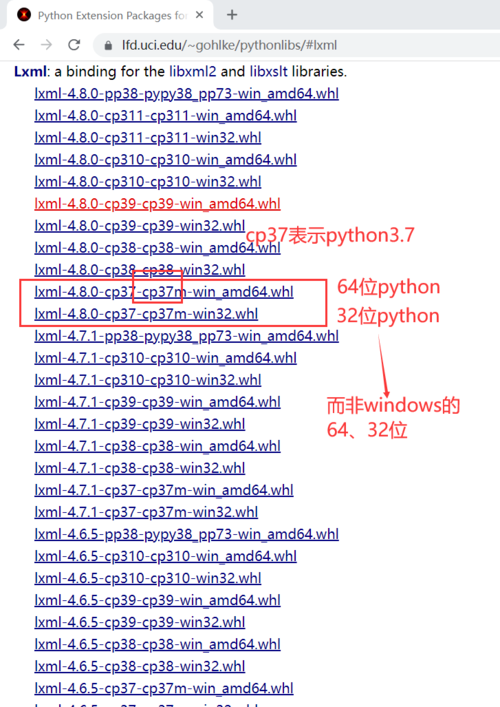
1.容易出错的包Lxml
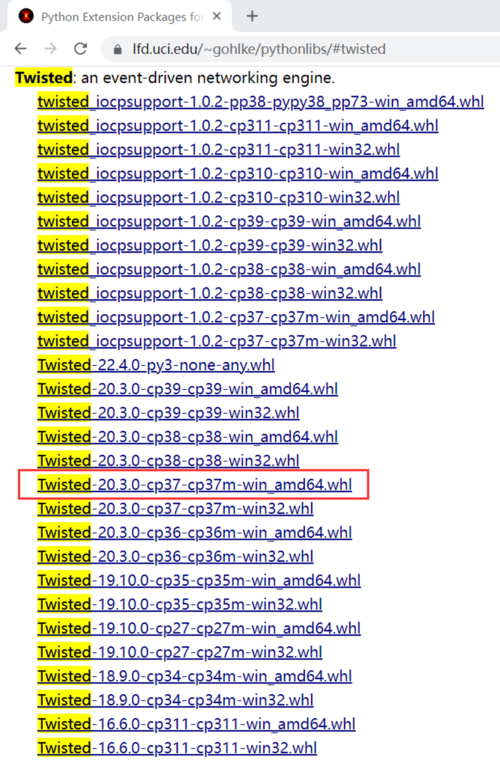
2.易错twisted包
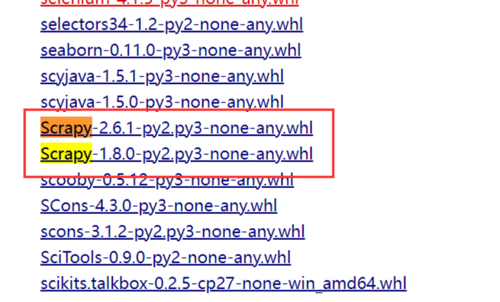
3.易错scrapy包
4.易错PyWin32包
2.如何本地安装
注:最后手动安装scrapy,因为scrapy依赖其他几个包
pip install -i https://pypi.douban.com/simple lxml-4.7.1-cp37-cp37m-win_amd64.whl
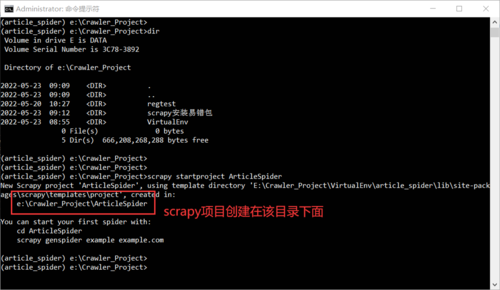
3.创建scrapy项目
1.scrapy创建项目命令:scrapy startproject ArticleSpider
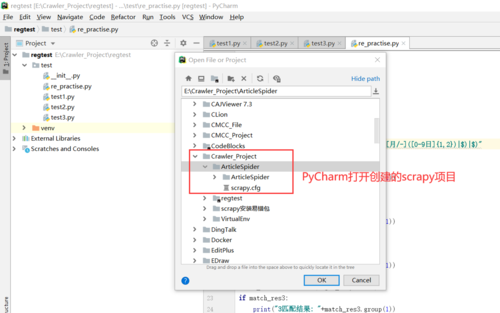
2.PyCharm打开scrapy创建项目
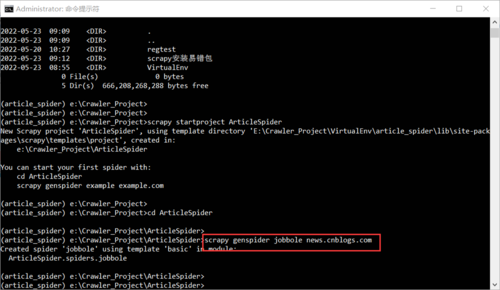
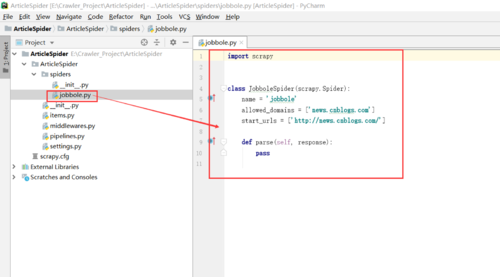
3.创建自定义spider
命令:scrapy genspider jobbole(名称(随便)) news.cnblogs.com(需要爬取的网站子域名)
from scrapy.cmdline import execute
import sys
import os
if __name__ == '__main__':
"""
为什么使用__file__,而不使用sys.path.append("E:/Crawler_Project/ArticleSpider")
原因:如果当前项目不在该路径下面或者部署到服务器上面,则会找不到该路径报错
1.__file__ 当前文件路径——E:/Crawler_Project/ArticleSpider/main.py
2.os.path.dirname(__file__)——E:/Crawler_Project/ArticleSpider
3.os.path.abspath(__file__)——E:/Crawler_Project/ArticleSpider/main.py(原因:可能有些版本python使用file会输出main.py)
"""
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
# sys.path.append()将一个目录放至python搜索目录中
# os.path.dirname()获取文件路径的文件夹路径——E:/Crawler_Project/ArticleSpider
execute(["scrapy", "crawl", "jobbole"])
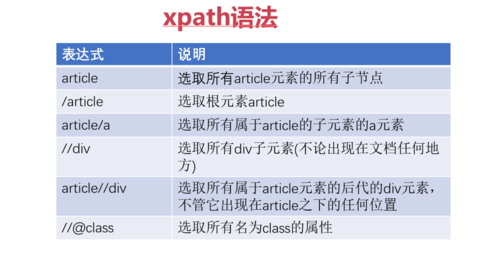
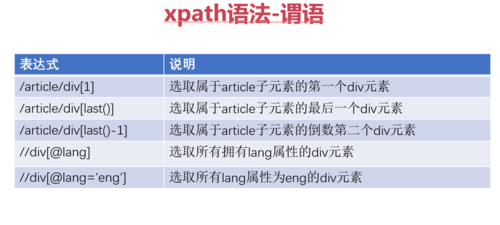
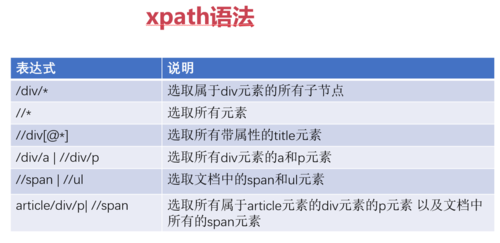
xpath:
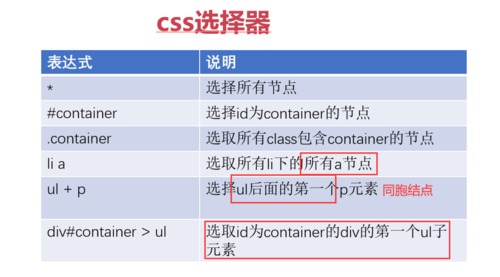
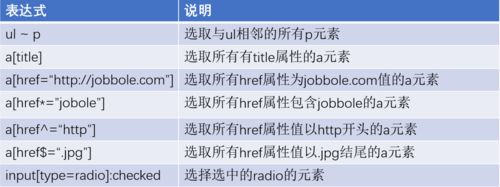
CSS选择器
共同学习,写下你的评论
评论加载中...
作者其他优质文章



