
第一模块
课程名称:2022全新版-Java分布式架构设计与开发实战
章节名称:2-1~2-9
讲师姓名:大能老师
第二模块
内容概述:
2-1~2-9小节主要讲解了分布式的理论基础——cap和base;中国互联网的发展历程;缓存的引入对数据库的意义;数据读写分离带来的性能提升;CDN解决前端资源的请求问题;文件和数据进行分布式存储,以及在海量数据中如何检索需要的数据等。
第三模块
学习心得:
通过2-1~2-9小节的学习使我对分布式有了深刻的认识,知道了其不仅有理论基础更有实际的实现,分布式下解决了很多单机系统无法解决的问题,同时也带来了新的难题,比如分布式下的事务——如何保证数据的一致性,当然到目前为止,业界已经发展出了成熟的解决方案。作为后来人要能充分学习前人的智慧,并发展出新的技术!下面附上学习笔记:
2-1 分布式理论基础:

中国互联网发展历程:
1994 - 2000 四大门户到搜索:网易、搜狐、新浪、腾讯【四大门户网站】、阿里巴巴、百度【内容为王】
2001 - 2009 从搜索到社交网络【关系为王】:博客、人人网
2010 - 现在 移动互联网和自媒体:【移动互联网和自媒体】:短视频、网络直播
单体应用架构:
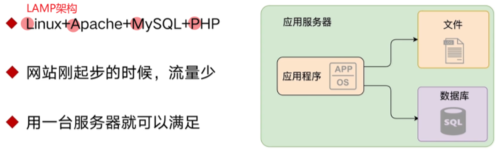
架构演进方向:

分服务器部署:
2-4 引入缓存分担数据库的压力:

图解缓存:

本地缓存的特点:
和应用服务器在一台机器上,和本地应用共用内存
速度快
容量有限
分布式缓存的特点:
在另外一台服务器上
速度上慢于【本地缓存】,但快于数据库
需要额外的网络开销
Tomcat服务器性能指标:
Tomcat7与7之前,一个请求就会占用一个线程,所以请求的并发上限1000左右
Tomcat8与8之后,采用了NIO的方式,并发达到了4000左右
提升系统并发能力的方式:
堆人:水平扩展,搞集群(技术基础:应用服务器的代理,eg:Nginx(软件4),F5(硬件))
堆能力:垂直扩展,提高单个应用的并发上限
数据库的读写分离:基于数据库的主从复制的机制,实现主库写,从库读的设计,eg:
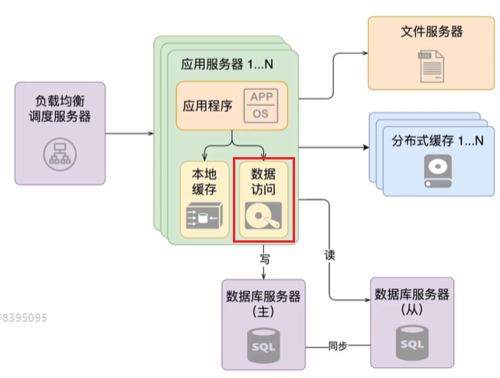
数据访问模块的存在意义:
对接多个数据源,实现读写分离和分库分表,从而将【数据库的架构变化】封装在【数据访问层】,使上层的业务逻辑代码对数据库的变化做到无感!!!即:独立于应用程序而存在,做到复用!!!
常见实现技术:ShardingSphere(已经实现了读写分离、分库分表的功能)
关于”网络带宽“:可以理解成【网上的高速公路】,既然是”路“,那就有宽度,当宽度被用完的时候,数据与请求就会进都进不去,给人的感觉就是——要访问的网站挂掉了。
避免网络带宽被耗尽的常用解决方案——CDN(内容分发网络):
原理,通过四处建分站,让用户就近获取静态资源;
即:把”静态资源“提前缓存到各地的边缘服务器中。
另一个好处:有效降低DDOS攻击,原因:DDOS攻击会对边缘服务器造成压力,但远程源服务器不会有影响!!!
DDOS攻击:通过发起极高的”虚假请求“,从而达到耗尽网络带宽的目的,进而使”真实请求“无法得到服务器回应,给真实用户带来”服务不可用“的感觉!!!
常见的分布式文件系统:
适合存小文件的:
FastDFS
TFS
适合存大文件的【大文件的标准:上百兆】:
HDFS
海量数据检索 && 数据异构的问题:
海量数据检索:当数据达到”海量“时是无法通过SQL实现有效的检索的;
解决办法:引入搜索引擎
数据异构问题:
eg:同样是一件衣服,但是两者在属性上差别很大,AB属性上的相同点大于等于不同点,此时又因为各种原因,需要将AB存在一张表时,就需要设计大量的字段去包含住AB各自所有的属性,那此时表C中的字段会比较多,同时会又大量的空数据!!!像这样的问题就是【数据异构】
解决办法:引入nosql
常见的搜索引擎和nosql:

可以发现:ES可以做搜索引擎,也可以做nosql
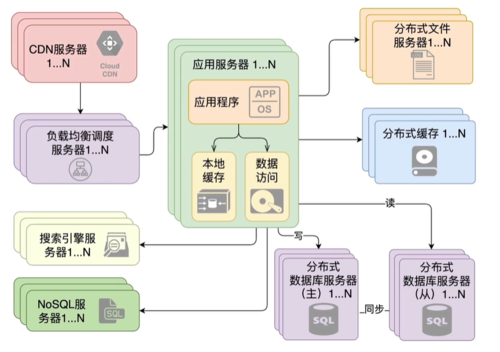
通过引入中间件来提高系统的性能,做大【高可用、高并发、高吞吐】,
eg:一个高可用、高并发、高吞吐的单体应用架构图
第四模块
学习截图:

共同学习,写下你的评论
评论加载中...
作者其他优质文章


