
在工作中大家可能会遇到下面这两个问题?
- 想要进一步提高Hive的计算效率,从数据压缩格式层面应该如何优化?
- Hive数仓中维护的数据量太大,如何提高存储空间的利用率?
针对这两个问题的解决方案,其实对应的就是在Hive中如何选择合适的数据压缩格式和数据存储格式。
Hive的数据存储格式,默认使用的都是TextFile格式的数据,这种格式的数据在存储层面占用的空间比较大,影响存储能力,也影响计算效率。
所以为了提高Hive中数据的存储能力(存储空间的利用率),以及计算性能,需要详细了解一下Hive的数据存储格式。
在具体分析Hive中的数据存储格式之前,先来了解一下Hive(MapReduce)中的数据压缩格式。
因为数据存储格式想要发挥最大性能,还需要配合数据压缩格式一起使用。
Tips:由于Hive任务底层走的是MapReduce,所以Hive中的数据压缩格式其实就是MapReduce中的数据压缩格式。
1. Hive(MapReduce)中常见的数据压缩格式
MapReduce中常见的数据压缩格式主要包括下面这些:
- DEFLATE
- Gzip
- Bzip2
- Lz4
- Lzo
- Snappy
注意:在Hadoop 3.x版本中,默认是没有集成Lzo压缩格式的,如果想要使用需要自己安装,其他的压缩格式默认都是支持的。
在Hadoop节点上执行hadoop checknative命令来确认一下:
[root@bigdata04 ~]# hadoop checknative
......
Native library checking:
hadoop: true /data/soft/hadoop-3.2.0/lib/native/libhadoop.so
zlib: true /lib64/libz.so.1
zstd : false
snappy: true /lib64/libsnappy.so.1
lz4: true revision:10301
bzip2: true /lib64/libbz2.so.1
openssl: true /lib64/libcrypto.so
ISA-L: false libhadoop was built without ISA-L support
这里面主要有zlib、snappy、lz4、bzip2。
注意:DEFLATE压缩格式底层使用的是zlib,Gzip是对DEFLATE进行了封装,所以只有lzo没有集成,其他的压缩格式都是可以正常使用的。
这几种压缩格式的自身特点和性能见下图: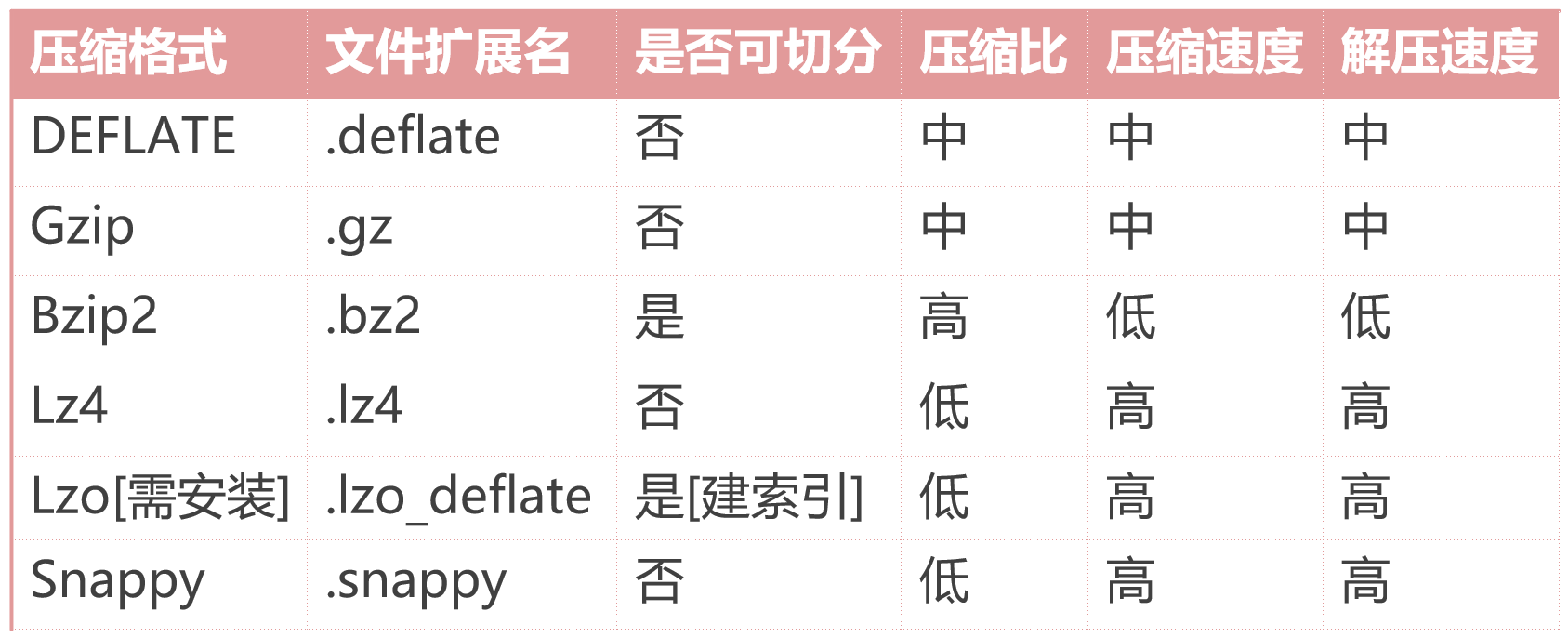
解释:
- 文件扩展名:表示压缩后的数据文件的后缀名称。
- 是否可切分:表示压缩后的数据文件在被
MapReduce读取的时候,是否会产生多个InputSplit。如果这个压缩格式产生的文件不可切分,那也就意味着,无论这个压缩文件有多大,在MapReduce中都只会产生1个Map任务。如果压缩后的文件不大,也就100M左右,这样对性能没有多大影响。但是如果压缩后的文件比较大,达到了1个G,由于不可切分,这样只能使用1个Map任务去计算,性能就比较差了,这个时候就没有办法达到并行计算的效果了。所以是否可切分这个特性是非常重要的,特别是当我们无法控制单个压缩文件大小的时候。 - 压缩比:表示压缩格式的压缩效果,压缩比越高,说明压缩效果越好,对应产生的压缩文件就越小。如果集群的存储空间有限,则需要重点关注压缩比,这个时候需要选择尽可能高的压缩比。
- 压缩速度:表示将原始文件压缩为指定压缩格式消耗的时间。压缩功能消耗的时间会体现在任务最终消耗的时间里面,所以这个指标也需要重点考虑。
- 解压速度:表示将指定压缩格式的数据文件解压为原始文件消耗的时间。因为MapReduce在使用压缩文件的时候需要先进行解压才能使用,解压消耗的时间也会体现在任务最终消耗的时间里面,所以这个指标也需要重点考虑。
注意:
这里所说的是否可切分是针对TextFile文件,也就是普通文本文件而言的。因为其他特殊的文件格式(例如:ORC、PARQUET等),结合不可切分的压缩格式之后(例如:Snappy、Gzip等),依然是可以支持切分的,这是由于这些特殊文件格式自身的特性决定的,和压缩格式的特性没有关系,这个在后面讲Hive中的数据格式的时候会详细分析。
针对这些数据压缩格式的压缩效果(压缩比),如下图所示: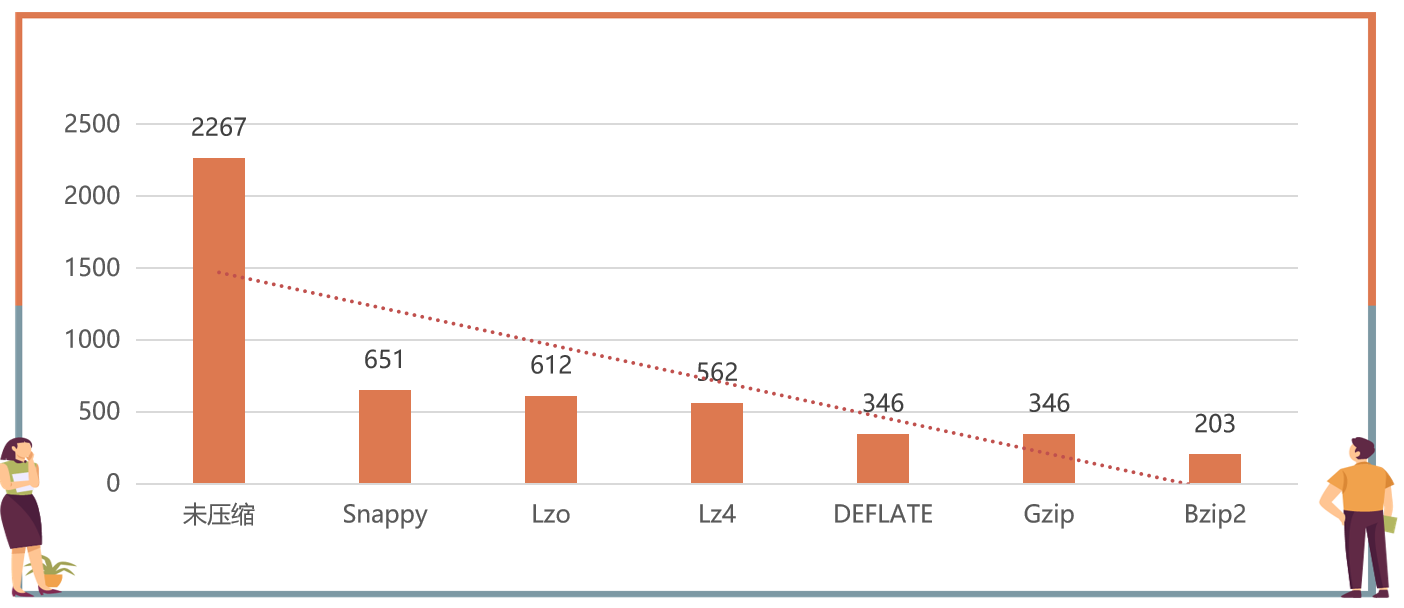
这个图里面显示的是未压缩的数据文件和各种压缩格式压缩后的数据文件的大小。
其中未压缩的数据文件大小为2267M,图中按照压缩效果进行排列,最右侧的是压缩效果最好的,Bzip2压缩后的文件只有203M。
注意:这个压缩后的数据文件大小,和原始数据内容也是有关系的,所以这里的数值大小仅作为参考,但是都是符合这个规律的。
在MapReduce的整个过程中,可以在两个地方设置数据压缩格式:
- 一个是针对
Map阶段的输出数据进行压缩。 - 一个是针对
Reduce阶段的输出数据进行压缩。
(1) 针对Map阶段的输出数据:建议选择压缩和解压速度快的压缩格式。Map阶段的数据落盘后会通过Shuffle,也就是通过网络传输到Reduce端。压缩Map的输出是可以提高网络传输效率的。但是压缩Map的输出会增加CPU的消耗。Map阶段在处理数据的时候自己本来就会消耗过多的CPU,所以此时应该重点考虑使用压缩和解压速度比较快的LZO、Snappy。

(2) 针对Reduce阶段的输出数据:需要分为两种场景。
- 如果结果数据是永久保存,此时需要重点考虑压缩效果比较好的
Bzip2和Gzip。 - 如果结果数据还需要让另一个
MapReduce任务继续计算,则需要重点考虑压缩后的数据文件是否支持切分。比如:Bzip2、Lzo。
2. Hive中常见的数据存储格式
Hive没有专门的数据存储格式,默认可以直接加载文本文件TextFile,还支持SequenceFile、RCFile这些。
其实完整来说,主要包括下面这些数据存储格式。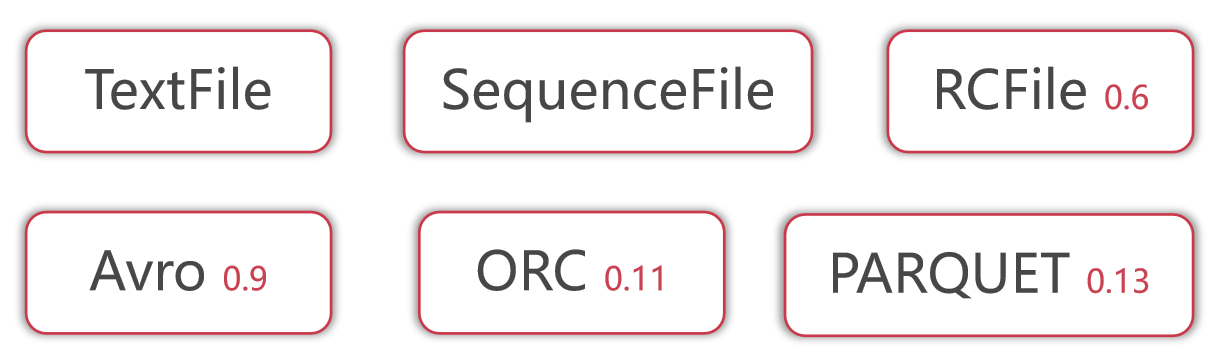
- 其中RCFile数据存储格式是从Hive 0.6版本开始支持的。
- Avro数据存储格式是从Hive 0.9版本开始支持的。
- ORC数据存储格式是从Hive 0.11版本开始支持的。
- PARQUET数据存储格式是Hive 0.13版本开始支持的。
目前工作中使用最多的是TextFile、ORC和Parquet。
默认情况下使用TextFile即可,想要提高数据存储和计算效率,可以考虑使用ORC或者Parquet。
2.1:数据存储格式之TextFile
TextFile是Hive的默认数据存储格式,基于行存储。
它的主要特点是磁盘存储开销大,数据解析开销大。
怎么理解呢?
- 磁盘存储开销大:因为存储的是原始文件内容,没有使用压缩,所以存储开销会比较大。
- 数据解析开销大:因为在反序列化读取数据的过程中,必须逐个字符判断是不是字段分隔符和行结束符,所以数据解析开销大。
当然了,如果想要减少磁盘存储开销,也可以对TextFile格式的数据进行压缩,但是部分压缩格式在Hive中无法切割。
数据的压缩格式其实是在MapReduce中提出的,因为Hive底层支持MapReduce,所以Hive中也支持这些压缩格式。
2.2:数据存储格式之SequenceFile
SequenceFile是一种二进制文件,内部数据是<Key,Value>的形式,也属于行存储。
它的特点是使用方便,MapReduce原生支持这种数据格式,并且它还支持切分,也支持压缩。
可以支持NONE、RECORD、BLOCK级别的压缩。
- NONE表示不压缩
- RECORD表示行级别的压缩
- Block表示块级别的压缩
由于Record是针对每一条数据分别进行压缩,压缩率比较低,所以一般都会选择Block压缩。
2.3:数据存储格式之RCFile
RCFile是专门为Hive设计的数据存储格式。
数据会首先按照行分组,每个组内部按照列存储。
他整合了行存储和列存储的优点,可以称为是行列式存储,大层面还是属于列式存储的。
他的主要特点是压缩速度快,可分割,支持快速列存取。
在读取所有列的情况下,RCFile的性能没有SequenceFile高,不过在实际工作中大部分的统计分析需求都不会读取所有列。
下面通过一个图来直观的感受一下RCFile的数据存储格式。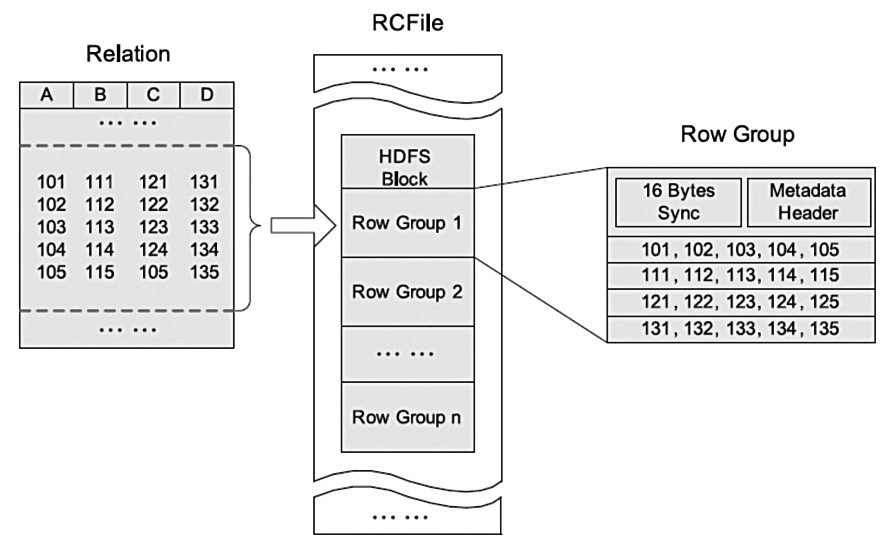
左边的Relation表示关系型数据库中的数据存储形式,可以把它认为是一张表,表中有A\B\C\D这几个列。
第一行数据中 A的值为101,B的值为111,C的值为121,D的值为131。
后面的以此类推。
针对这份数据,如果使用RCFile格式进行存储是这样的,看中间这个图:RCFile是存储在HDFS里面的,所以说会有多个HDFS的Block块。
每个Block块内部包含多个Row Group。RowGroup可以翻译为:行组。RowGroup里面包含的是具体的数据,存储格式是这样的,看右边这个图:
这里面的第一行数据是所有A字段的值,因为RowGroup是行列式存储,所以会把原始表中的每个列的数据存储到一起,便于查询这个列的数据。
第二行是所有B字段的值。后面的以此类推。
所以从这个图里面可以看出来,RCFile会把数据首先按照行分成Row Group,在Row Group内部按照列存储,每个列的数据存储在一起。
2.4:数据存储格式之ORC
ORC是在RCfile的基础之上做了一些升级,在性能层面有大幅度提升。ORC的存储格式是这样的: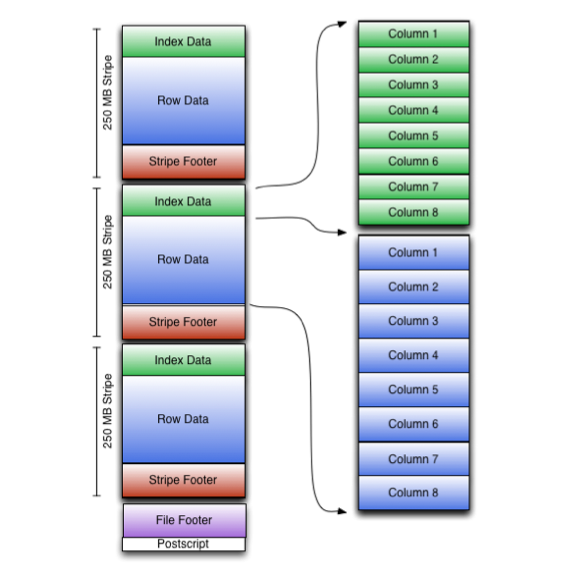
从这个图中大致可以看出来ORC中的数据首先会被划分为多个Stripe,每个Stripe 250M。Stripe表示ORC文件存储数据的地方。
在Stripe内部包含了Index Data,Row Data和Stripe Footer。
- Index Data这里面存储的是索引数据。
- Row Data里面存储的是具体的数据,这里面有多个行组,每
10000行构成一个行组。 - Stripe Footer:里面存储的是数据所在的文件目录。
最下面的File Footer:里面包含了ORC文件中Stripe的列表、每个Stripe的行数,以及每个列的数据类型。它还包含了每个列的最小值、最大值等信息。postscript:里面包含了压缩参数和压缩大小相关的信息。
这个图看起来稍微有点复杂,简化一下是这样的: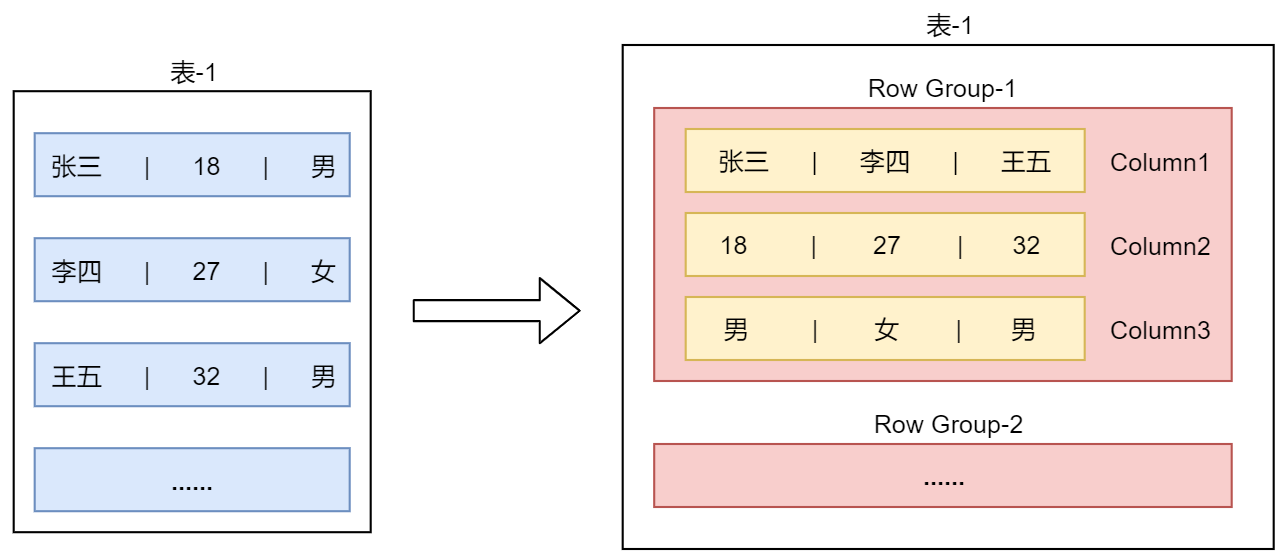
从这个图里面可以看出来ORC存储格式和RCFile存储格式在存储形式上没有特别大的区别,核心思想还是行列式存储。
注意:从官网文档资料上来看,ORC只支持NONE、ZLIB、SNAPPY这三种压缩格式,默认是ZLIB。通过查看源码以及实际验证发现,目前ORC还支持LZO这种压缩格式。
2.5:数据存储格式之ORC
Parquet是一种新型的与语言无关的,并且不和任何一种数据处理框架绑定的列式存储结构,适配多种语言和组件。Parquet数据存储格式可以在Hive、Impala、Spark等计算引擎中使用。Parquet的存储格式是这样的: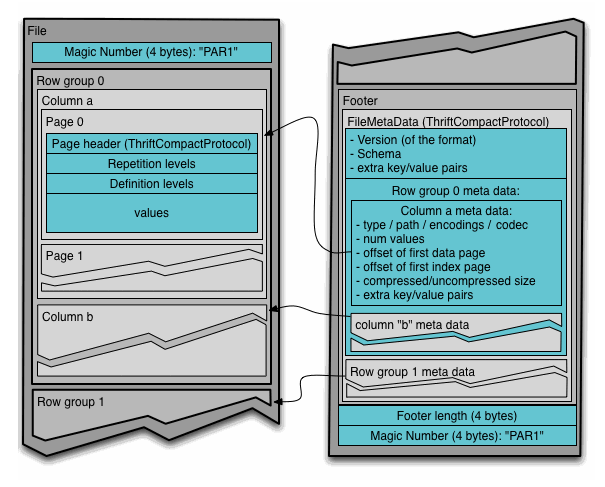
这个图是来源图官网的,看起来有点乱。
但是大致可以看出来Parquet格式的文件中包含了多个Row Group。
- 每个Row Group内部包含了多个Column。
- Column内部包含了多个Page。
- Page内部存储了具体的数据内容。
下面来看一个简化版的,这样看起来会清晰一些。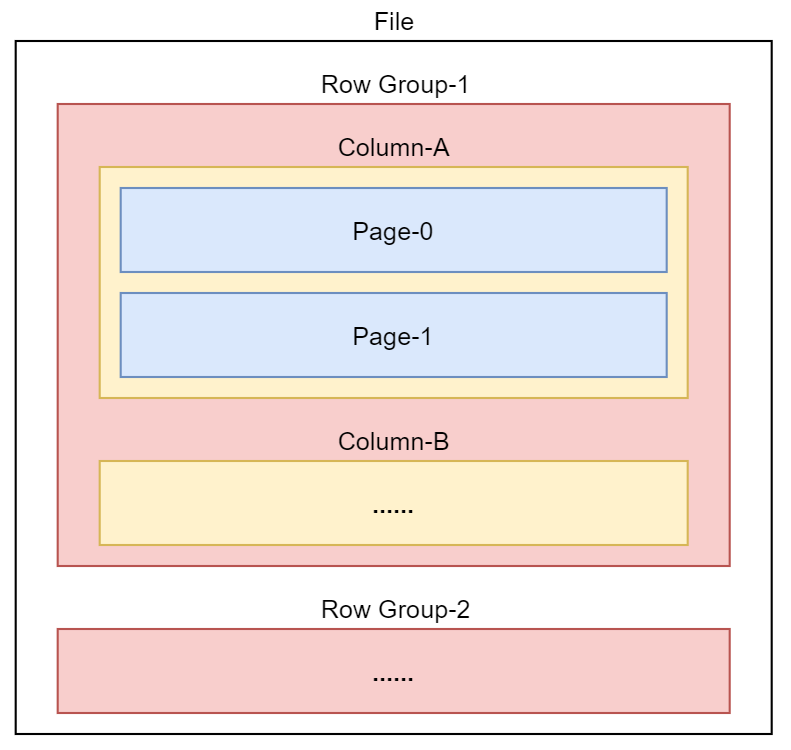
Parquet存储格式比ORC更复杂一些,多封装出来一层Page。ORC存储格式是把数据内容直接存储到了Column这一层。
Parquet具体都支持哪些压缩格式呢?
通过查阅源码发现,主要支持下面这些,如下图所示: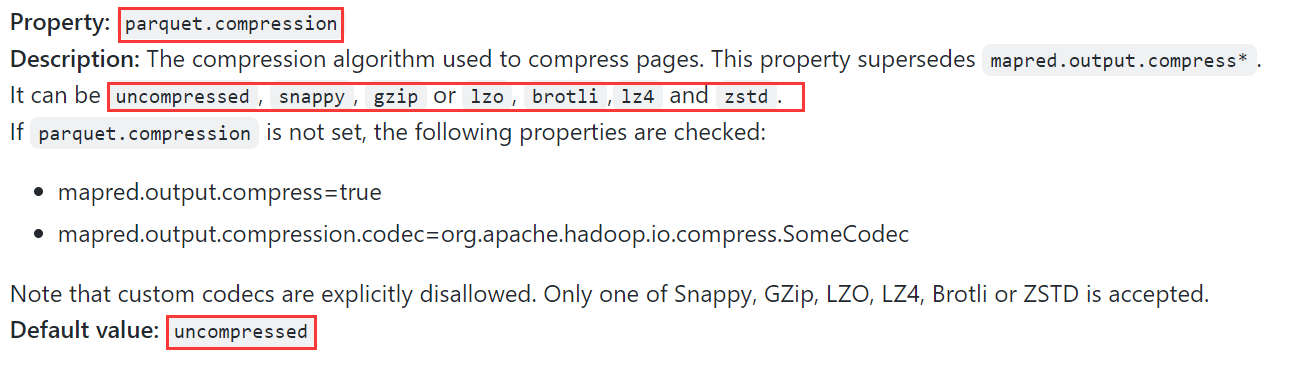
2.6:数据存储格式总结
我们分析了这么多种数据存储格式,具体在工作中应该如何选择呢?
看一下这个图片:
原始文本文件大小为:2.09G。
从这个图片中可以看出来,ORC格式在数据存储层面性能最优。
所以在实际工作中,如果希望减少Hive中的数据存储量,建议使用ORC数据存储格式。
在使用ORC数据存储格式的时候,最好再配合上合适的压缩格式,这样可以进一步挖掘ORC的存储性能。
但是ORC自身存储能力已经非常好了,并且也支持切分。所以在选择压缩格式时只需要重点考虑压缩和解压速度就行了。
常见的压缩格式中,Lzo、Snappy的压缩和解压速度是最快的。
针对他们两个进行对比的话,看下面这个图片。
从这里可以看出来,Snappy的压缩和解压速度相对更好一些。
注意:这个表格中的数据需要在生产环境下进行测试,虚拟机下测试的不太准确,但是大致规律是一样的。
所以最终建议,在工作中选择ORC+Snappy。
但是有时候在选择数据存储格式的时候还需要考虑它的兼容度,是否支持多种计算引擎。
假设我希望这一份数据,既可以在Hive中使用,还希望在Impala中使用,这个时候就需要重点考虑这个数据格式是否能满足多平台同时使用。Impala很早就开始支持Parquet数据格式了,但是不支持ORC数据格式,不过从Impala 3.x版本开始也支持ORC了。
如果你们使用的是Impala2.x版本,还想要支持Hive和Impala查询同一份数据,这个时候就需要选择Parquet了。
相对来说,Parquet存储格式在大数据生态圈中的兼容度是最高的。
更多Hive数据压缩和数据存储的内容请关注《慕课网大数据工程师》体系课。

慕课网大数据工程师体系课直达链接:
https://class.imooc.com/sale/bigdata
共同学习,写下你的评论
评论加载中...
作者其他优质文章



