
课程名称:Java架构师-技术专家
课程章节: 阶段四 · 服务调用链追踪、消息驱动
课程讲师: 慕课讲师团队
课程内容
链路追踪在微服务中的应用
微服务之间的调用关系图一

-
分布式环境下的链路追踪
-
Timing 信息
-
定位链路
-
信息的收集和展示
Sleuth 核心功能和体系架构
Sleuth最核心的功能就是提供链路追踪,在一个用户请求发起到结束的整个过程中,这个Request 经过的所有服务都会被 Sleuth 梳理出来。
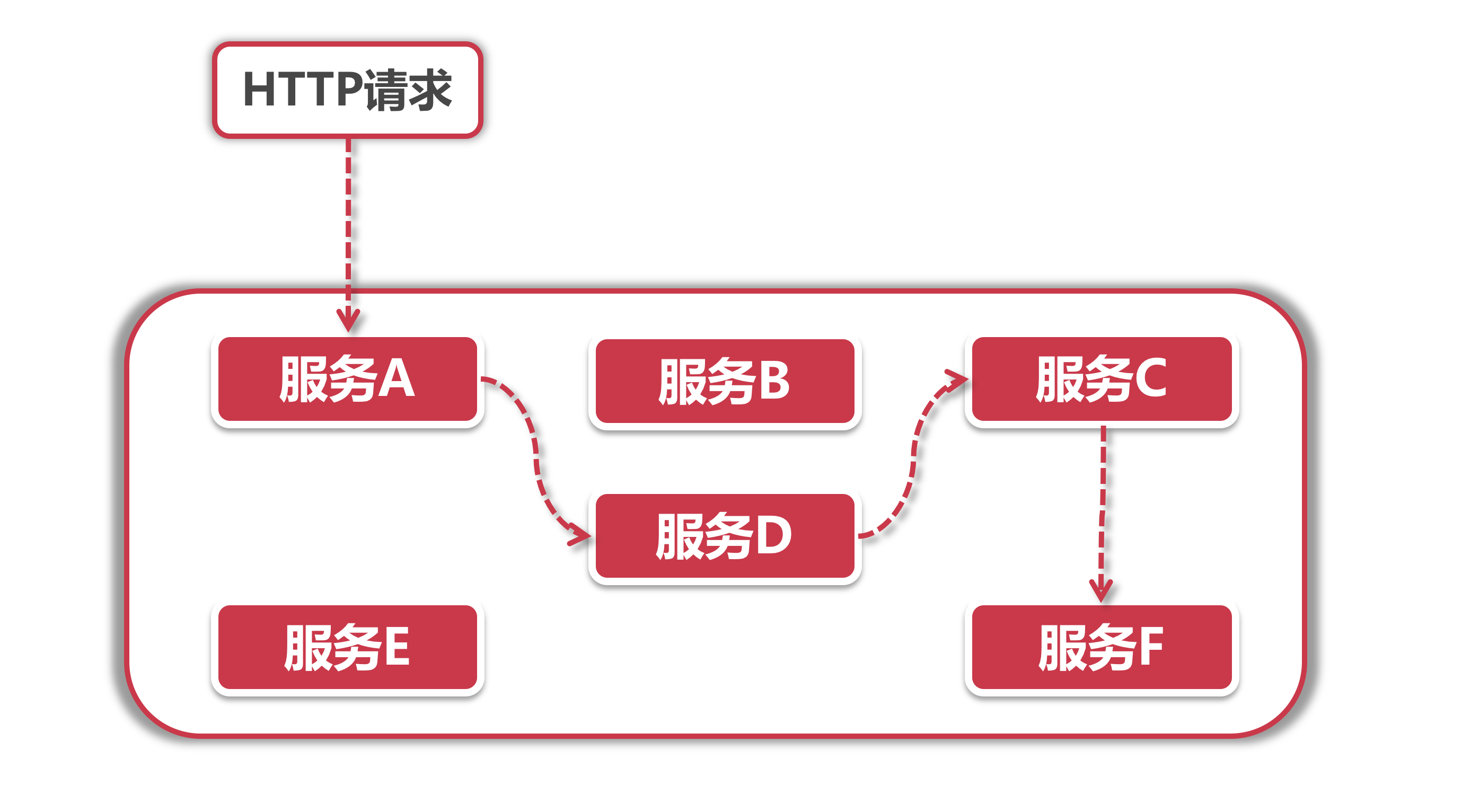
比如上面的例子,用户请求访问了服务 A ,接着服务 A 用在内部先后调用了服务 D,C 和 F,在这里 Sleuth 的工作就是通过一种 ”打标“的机制,将这个链路上的所有被访问到的服务打上一个相同的标记,这样我们只要拿到这个标记,旧很容易可以追溯到链路上下游所有的调用。
借助 Sleuth 的链路追踪能力,我们还可以完成一些其它的任务,比如说:
-
线上故障定位:结合 Tracking Id 寻找上下游链路中所有的日志信息,(这一步还需要借助一些其它开源组件)
-
依赖分析梳理:梳理上下游依赖关系,理清整个系统中所有微服务之间的依赖关系
-
链路优化:比如目前有三种途径可以导流到下单接口,通过对链路调用情况的统计分析,我们可以识别出转化率最高的业务场景,从而为以后的产品设计提供指导意见。
-
性能分析:梳理各个环节的时间消耗,找到性能瓶颈,为性能优化、软硬件资源调配指明方向。
设计原则
-
无业务侵入:不需要对业务代码做任何改动,即可静默接入链路追踪功能。
-
高性能:可以设置采样率,进一步降低开销。
Sleuth架构体系
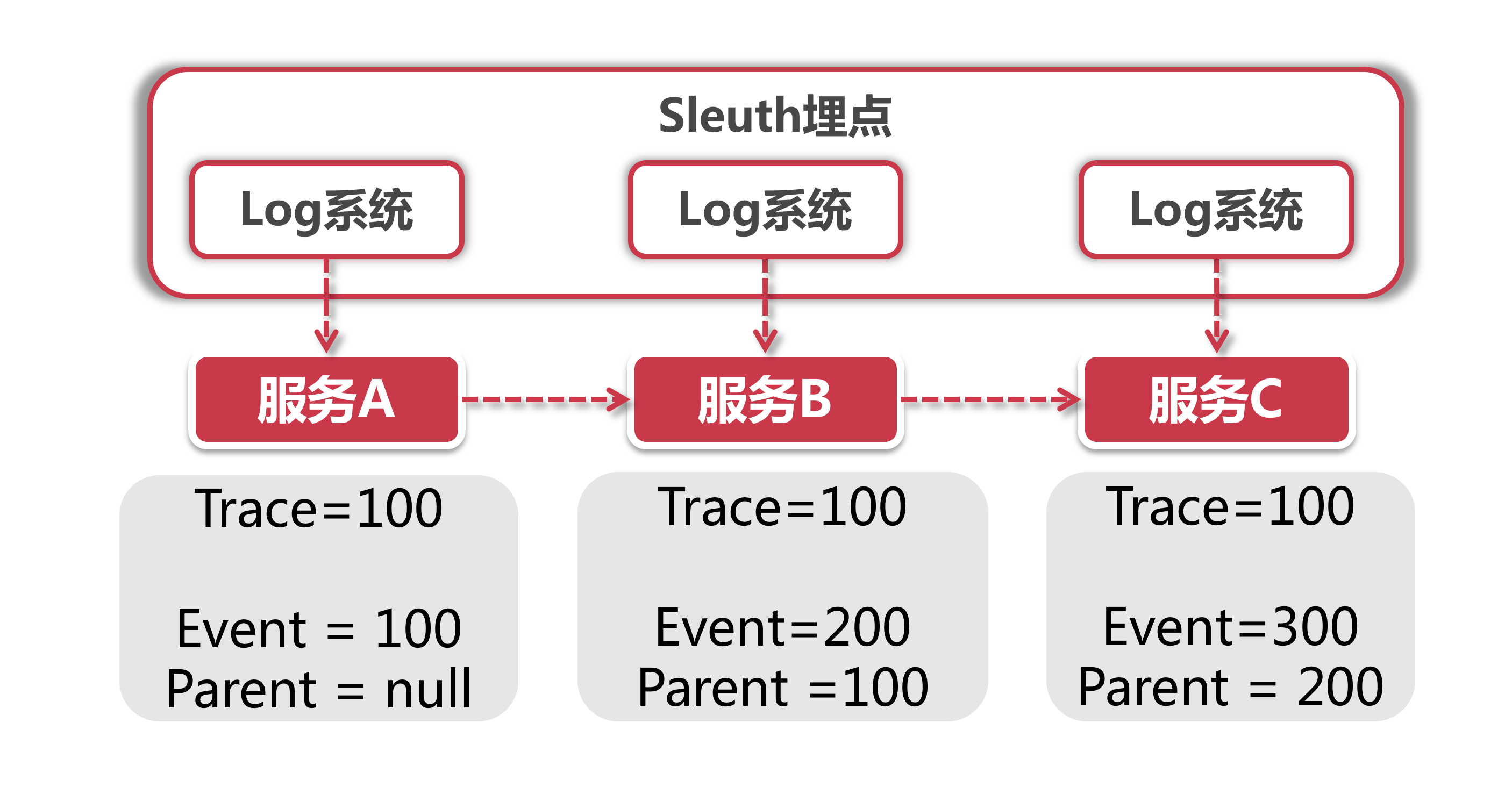
Sleuth采用集成底层 Log 系统的方式实现业务埋点,下面是它的结构:
那些数据需要埋点
每一个微服务都有自己的 Log 组件(slf4j,logback等各不相同),当我们集成 Sleuth 之后,它便会将链路信息传递给底层 Log 组件,同时 Log 组件会在每行 Log 的头部输出这些数据,这个埋点动作主要会记录两个关键信息:
-
链路 ID 当前调用链的唯一 ID,在这次调用请求开始到结束的过程中,所有经过的节点都拥有一个相同的链路 ID
-
单元 ID 在一次链路调用中会访问不同服务器节点上的服务,每一次服务调用都相当于一个独立单元,也就是说会有一个独立单元 ID。同时每一个独立单元都要知道调用请求来自哪里(就是对当前服务发起直接调用的哪一方的单元ID,记为 Parent Id)
比如这里服务 A 是起始服务,所以它的 EventID(单元Id)和 Trace ID(链路 ID)相同,而服务 B 的前置节点就是 A 节点,所以 B 的Parent Event 就是指向 A 的 Event ID。而 C 在 B 的下游,所以 C 的 Parent Id 就指向 B。A、B 和 C 三个服务都有同一个链路 ID ,但是各自有不同的单元 ID 。
数据埋点之前要解决的问题
-
Log系统集成 如何让埋点信息加入到业务 Log 中
-
埋点信息的传递 SpringCloud 中的调用都是通过 HTTP 请求来传递的。
Log 系统集成
我们需要把链路追踪信息加入到业务 Log 中,这些业务 Log 是写在具体服务里的,而不是 Sleuth 单独打印的 log ,因此 Sleuth 需要找到一个合适的切入点,让底层的 Log 组件可以获取链路信息,并且业务代码还不需要做任何改动。
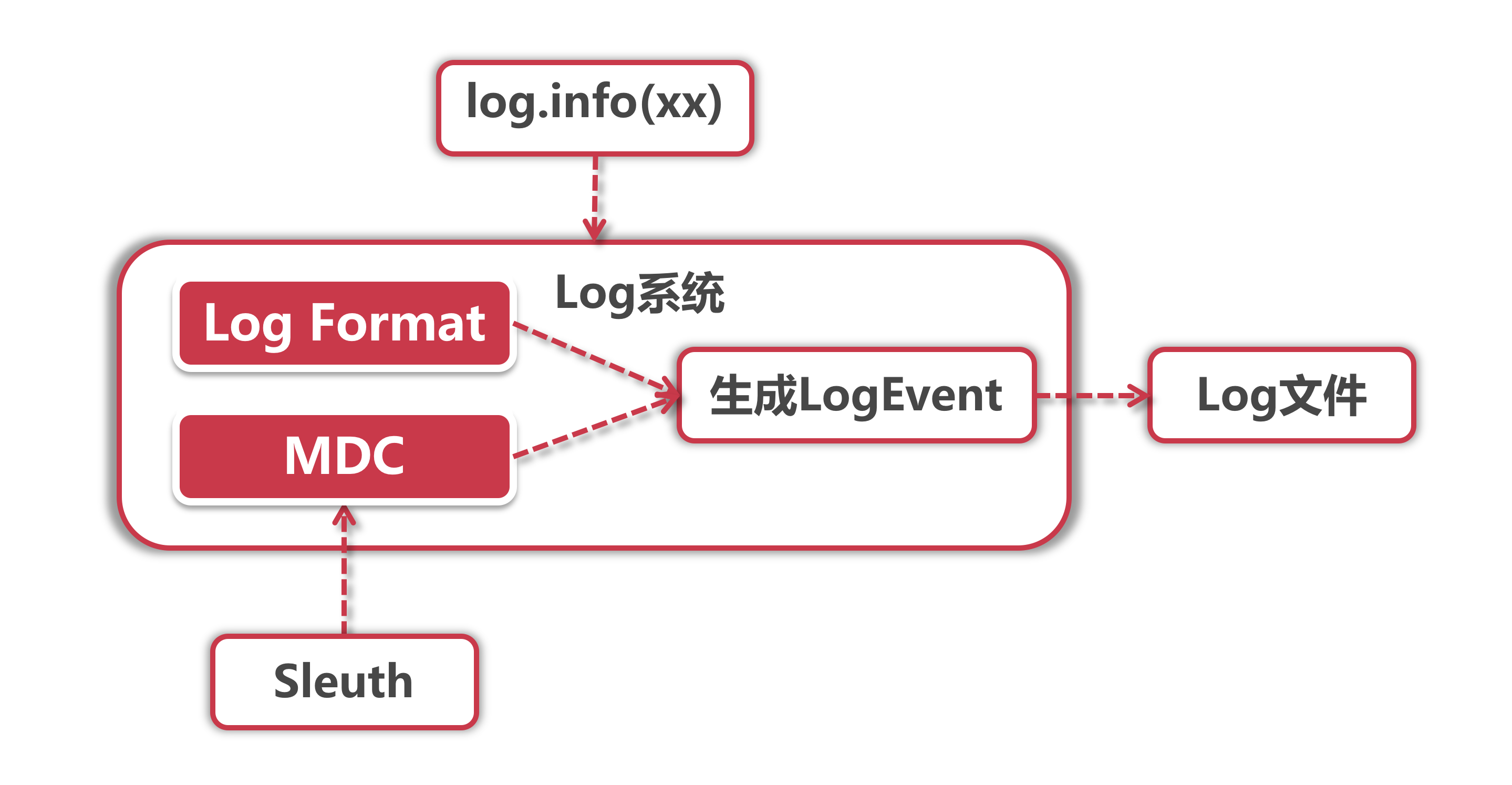
当我们使用”log.info“打印日志的时候,Log 组件会将”写入”动作封装成一个 LogEvent 事件,而这个事件的具体表现形式由 Log Format 和 MDC 共同控制,Format 决定了Log的输出格式,而MDC 决定了输出什么内容。
Log Format Pattern
Log 组件定义了日志输出格式,这和我们平时使用 “String.format" 的方式差不多,集成 Sleuth 之后的Log 输出格式是下面这个样子的。
“%5p [sleuth-traceA,%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]”
上面几个 X 开头的占位符,就是需要写入 log 的链路追踪信息了。至于这几个符号分别对应链路信息的那部分。
MDC
MDC是通过 Inheritable ThreadLocal 来实现的,可以携带当前线程的上下文信息。它的底层是一个 Map 结构,存储了一系列 Key-Value 的值。Sleuth 就是借助 Spring 的 AOP 机制,在方法调用的时候配置了切面,将链路追踪数据加入到了 MDC 中,这样在打印 Log 的时候,就能从 MDC 中获取这些值,填入到 Log Format 中的占位符里面。
由于 MDC 基于 Inheritable ThreadLocal 而不是 ThreadLocal 实现,因此假如在当前线程中又开启了新的子线程,那么子线程依然会保留父线程的上下文信息。
课程收获
今天学习了以下内容:
- sleuth 的职能
- Sleuth 核心功能和体系架构

共同学习,写下你的评论
评论加载中...
作者其他优质文章



