
①课程介绍
课程名称:Python3入门机器学习 经典算法与应用 入行人工智能
课程章节:7-1,7-2
主讲老师:liuyubobobo
内容导读
上一篇文章对PCA算法进行地整体思路的顺,这篇文章分片来讲PCA在使用搜索的方式求解过程中做了什么。
- 第一部分 使用极端数据测试
- 第二部分 求数据的前N个主成分
- 第三部分 求解第一个主成分详解
②课程详细
第一部分 使用极端数据测试
导入函数
import numpy as np
import matplotlib.pyplot as plt
创造随机的数据,theta的值为3,4
X2 = np.empty((100, 2))
X2[:,0] = np.random.uniform(0., 100., size=100)
X2[:,1] = 0.75 * X2[:,0] + 3.
可视化
plt.scatter(X2[:,0],X2[:,1])
plt.show()
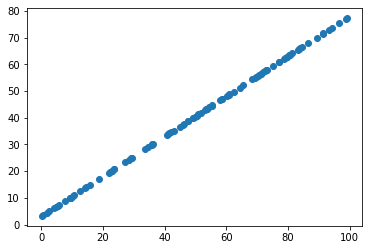
通过看图中数据的分布可以看出以下几点
- 数据没有噪点,呈线性分布
- 假如降维的话,最佳的主成分w就是沿着线分布,
- 这图片仅仅展示了两个维度的X数据
找出前N个主成分
X2_demean = demean(X2)
initial_w = np.random.random(X2.shape[1])
w2 = gradient_ascent(df_math, X2_demean, initial_w, eta=0.001)
可视化降维结果
plt.scatter(X2_demean[:,0], X2_demean[:,1])
plt.plot([0, w2[0]*30], [0, w2[1]*30], color='r')
plt.show()
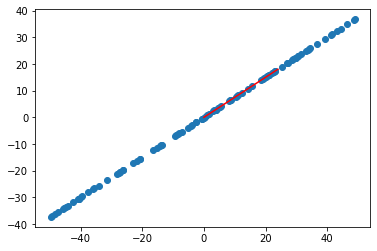
可以看出降维结果没有问题,我自己实现的PCA算法没问题
第二部分 求数据的前N个主成分(代码展示)
这一部分,展示求解主成分的代码
导入函数
import numpy as np
import matplotlib.pyplot as plt
创造随机的数据,
X = np.empty((100, 2))
X[:,0] = np.random.uniform(0., 100., size=100)
X[:,1] = 0.75 * X[:,0] + 3. + np.random.normal(0, 10., size=100)
对数据进行demean操作
def demean(X):
return X - np.mean(X, axis=0)
X = demean(X)
求主成分的代码
def f(w, X):
return np.sum((X.dot(w)**2)) / len(X)
def df(w, X):
return X.T.dot(X.dot(w)) * 2. / len(X)
def direction(w):
return w / np.linalg.norm(w)
def first_component(X, initial_w, eta, n_iters = 1e4, epsilon=1e-8):
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w)
if(abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
运行
initial_w = np.random.random(X.shape[1])
eta = 0.01
w = first_component(X, initial_w, eta)
w
求解第二主成分
#在X中对于第一主成分的分量去掉,去掉后设为X2
X2 = X -X.dot(w).reshape(-1,1) * w
我这里只有两个维度的数据,对于二维平面来说,找到第一个主成分以后,就剩一个主成分需要找了,而剩下的这一个主成分的寻找,其实某种程度上讲,已经和我们的数据无关了,剩下的这一个主成分,只要和我们的第一个主成分垂直就 ok 了
可视化
plt.scatter(X2[:,0], X2[:,1])
plt.show()
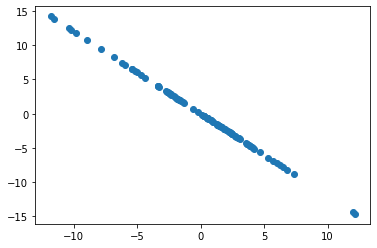
第三部分 求解第一个主成分详解
应为求解主成分找到一个轴,数据就删除掉这一主成分的数据分量,然后就成找下一个主成分,其实是一个循环,找主成分的过程其实用的函数是一样的。
代码详解
def first_n_components(n, X, eta=0.01, n_iters=1e4, epilson=1e-8):
X_pca = X.copy()
X_pca = demean(X_pca)
#主成分列表
res = []
#循环n次,求出前n个主成分
for i in range(n):
#下面要用梯度上升法,搜索对于当前XPca的第一主成分
#初始生成w
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca,initial_w, eta)
res.append(w)
#减去w轴方向上的主成分
X_pca = X_pca -X_pca.dot(w).reshape(-1,1) * w
#然后循环,基于新的x_pca进行求主成分,减去原来的w
return res
③课程思考
- PCA求解主成分的时候有点绕,但是利用三维可视化的方式,分布进行就能很清晰地认知PCA在做搜索方式进行地过程。
- PCA从主成分的方式来理解,就像是找出一个新的坐标系能更好表达数据的分布,而且每个轴逐级递增,因此降维之后能最大程度地保留数据地分布情况。
④课程截图

点击查看更多内容
1人点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦