
①课程介绍
课程名称:Python3入门机器学习 经典算法与应用 入行人工智能
课程章节:9-5 ; 9-6
主讲老师:liuyubobobo
内容导读
- 第一部分 逻辑回归添加多项式
- 第二部分 逻辑回归添加正则化
②课程详细
第一部分 逻辑回归添加多项式
有些数据非线性,不是线性的决策边界能够分割的。这时候就要引入多项式回归来拟合非线性数据的决策边界
导入函数
import numpy as np
import matplotlib.pyplot as plt
创建数据
np.random.seed(666)
X = np.random.normal(0, 1, size=(200, 2))
y = np.array(X[:,0]**2 + X[:,1]**2 < 1.5 , dtype='int')
对数据进行可视化处理
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
进行逻辑化回归查看逻辑回归的结果
from nike.LogisticRegression import LogisticRegression
log_reg1 = LogisticRegression()
log_reg1.fit(X, y)
查看准确率
log_reg1.score(X, y)
0.605
可以看到拟合的不是很好
对该数据和建立的模型进行决策边界可视化
定义可视化函数
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
可视化决策边界
plot_decision_boundary(log_reg1,[-4, 4 ,-4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
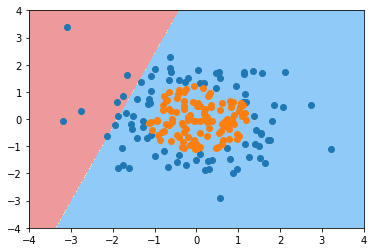
可以看到数据拟合地并不合适,究其原因在于开始的时候对数据的假设错了(线性数据)
接下来使用多项式回归
定义管道,和归一化处理
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
def PolynomialLogisticRegression(degree):
return Pipeline([
('poly',PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
调用函数,创建模型
poly_log_reg = PolynomialLogisticRegression(degree=2)
poly_log_reg.fit(X, y)
查看准确率
poly_log_reg.score(X, y)
1.0
可以看到准确率非常的高,
可视化决策边界
plot_decision_boundary(poly_log_reg,[-4, 4 ,-4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
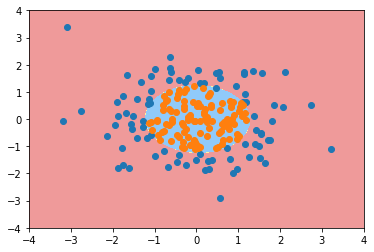
第二部分 逻辑回归添加正则化
在使用逻辑回归多项式之后,就会出现新地问题,过拟合,这时候就需要为逻辑回归添加正则化,来调解数据的过拟合,可以使用学习曲线进行观察。
创建对象
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
X = np.random.normal(0, 1, size=(200, 2))
y =np.array(X[:,0]**2 + X[:,1] <1.5, dtype=int)
for _ in range(20):
y[np.random.randint(200)] = 1
可视化随机数据
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
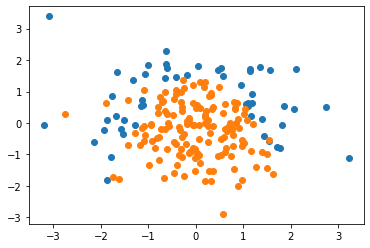
对数据进行分割以便于查看准确率
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=666)
直接使用多项式逻辑回归
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
def PolynomialLogisticRegression(degree):
return Pipeline([
('poly',PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression())
])
调用管道
Poly_reg = PolynomialLogisticRegression(degree=2)
Poly_reg.fit(X_train,y_train)
Poly_reg.score(X_test,y_test)
0.94
当dagree=2的时候准确率很不错,对新数据的泛化能力也很不错
可视化
plot_decision_boundary(Poly_reg, axis=[-4 ,4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
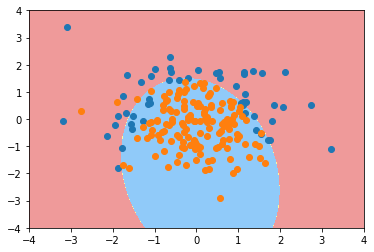
接下来模拟过拟合的情况,对多项式调整为20的
Poly_reg2 = PolynomialLogisticRegression(degree=20)
Poly_reg2.fit(X_train,y_train)
Poly_reg2.score(X_train,y_train)
可视化决策边界
plot_decision_boundary(Poly_reg2, axis=[-4 ,4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
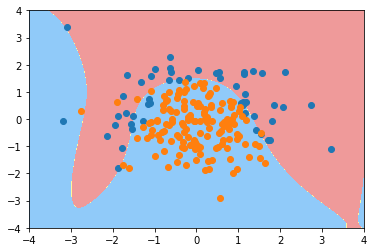
可以看到数据有一些拟合过度了,接下来加入正则化参数C对过拟合的情况进行一些缓和
定义新的管道符
def PolynomialLogisticRegression(degree, C):
return Pipeline([
('poly',PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('log_reg', LogisticRegression(C=C))
])
调用函数
Poly_reg4 = PolynomialLogisticRegression(degree=20, C=10, penalty='l2')
Poly_reg4.fit(X_train,y_train)
Poly_reg4.score(X_train,y_train)
进行可视化查看决策边界,以确定拟合的何不不合适
plot_decision_boundary(Poly_reg4, axis=[-4 ,4, -4, 4])
plt.scatter(X[y==0,0], X[y==0,1])
plt.scatter(X[y==1,0], X[y==1,1])
plt.show()
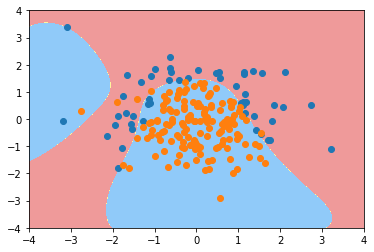
可以看到过拟合的情况得到了一部分的缓解
③课程思考
-
对于数据假设出错,就会使用错误的模型,就会导致准确率上不去,加入准确率一直上不去,可以试着从数据线性和非线性的两个角度考虑一下
-
有时候解决了一个问题就会相应的冒出一个新的问题,就像矛盾,矛盾的两个方面进行斗争,整合,共存,相互依赖,最后从旧的矛盾中诞生新的矛盾,这就是发展,我想算法的发展可能也会经理如此阶段。
④课程截图

共同学习,写下你的评论
评论加载中...
作者其他优质文章



