
您好,我是湘王,这是我的慕课手记,欢迎您来,欢迎您再来~
多数码农在开发的时候,要么处理同步应用,要么处理异步。但是如果能学会使用CompletableFuture,就会具备一种神奇的能力:将同步变为异步(有点像用了月光宝盒后同时穿梭在好几个时空的感觉)。怎么做呢?来看看代码。
新增一个商店类Shop:
/**
* 商店类
*
* @author 湘王
*/
public class Shop {
private String name = "";
public Shop(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
private double calculatePrice(String product) {
delay();
return 10 * product.charAt(0);
}
private void delay() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 同步得到价格
public double getPrice(String word) {
return calculatePrice(word);
}
// 增加异步查询:将同步方法转化为异步方法
public Future<Double> getPriceAsync(String product) {
CompletableFuture<Double> future = new CompletableFuture<>();
new Thread(() -> {
double price = calculatePrice(product);
// 需要长时间计算的任务结束并返回结果时,设置Future返回值
future.complete(price);
}).start();
// 无需等待还没结束的计算,直接返回future对象
return future;
}
}
然后再增加两个测试方法,一个同步,一个异步,分别对应商店类中的同步和异步方法:
// 测试同步方法
public static void testGetPrice() {
Shop friend = new Shop("某宝");
long start = System.nanoTime();
double price = friend.getPrice("MacBook pro");
System.out.printf(friend.getName() + " price is: %.2f%n", price);
long invocationTime = (System.nanoTime() - start) / 1_000_000;
System.out.println("同步调用花费时间:" + invocationTime + " msecs");
// 其他耗时操作(休眠)
doSomethingElse();
long retrievalTime = (System.nanoTime() - start) / 1_000_000;
System.out.println("同步方法返回所需时间:" + retrievalTime + " msecs");
}
// 测试异步方法
public static void testGetPriceAsync() throws InterruptedException, ExecutionException {
Shop friend = new Shop("某东");
long start = System.nanoTime();
Future<Double> futurePrice = friend.getPriceAsync("MacBook pro");
long invocationTime = (System.nanoTime() - start) / 1_000_000;
System.out.println("异步方法花费时间:" + invocationTime + " msecs");
// 其他耗时操作(休眠)
doSomethingElse();
// 从future对象中读取价格,如果价格未知,则发生阻塞
double price = futurePrice.get();
System.out.printf(friend.getName() + " price is: %.2f%n", price);
long retrievalTime = (System.nanoTime() - start) / 1_000_000;
System.out.println("异步方法返回所需时间:" + retrievalTime + " msecs");
}
这里之所以采用微秒,是因为代码量太少的缘故,如果用毫秒根本看不出来差别。运行之后会发现异步的时间大大缩短。
假设现在咱们做了一个网站,需要针对同一个商品查询它在不同电商平台的价格(假设已经实现了这样的接口),那么显然,如果想查出所有平台的价格,需要一个个地调用,就像这样(为了效果更逼真一些,将返回的价格做了一些调整):
private double calculatePrice(String product) {
delay();
return new Random().nextDouble() * product.charAt(0) * product.charAt(1);
}
/**
* 测试客户端
*
*/
public class ClientTest {
private List<Shop> shops = Arrays.asList(
new Shop("taobao.com"),
new Shop("tmall.com"),
new Shop("jd.com"),
new Shop("amazon.com")
);
// 根据名字返回每个商店的商品价格
public List<String> findPrice(String product) {
List<String> list = shops.stream()
.map(shop ->
String.format("%s price is %.2f RMB",
shop.getName(), shop.getPrice(product)))
.collect(Collectors.toList());
return list;
}
// 同步方式实现findPrices方法,查询每个商店
public void test() {
long start = System.nanoTime();
List<String> list = findPrice("IphoneX");
System.out.println(list);
System.out.println("Done in " + (System.nanoTime() - start) / 1_000_000 + " ms");
}
public static void main(String[] args) {
ClientTest client = new ClientTest();
client.test();
}
}
由于调用的是同步方法,因此结果查询较慢——叔可忍婶不能忍!
如果可以同时查询所有的电商平台是不是会快一些呢?可以试试,使用流式计算中的并行流:
// 根据名字返回每个商店的商品价格
public List<String> findPrice(String product) {
List<String> list = shops.parallelStream()// 使用并行流
.map(shop ->
String.format("%s price is %.2f RMB",
shop.getName(), shop.getPrice(product)))
.collect(Collectors.toList());
return list;
}
改好之后再试一下,果然快多了!
可以用咱们学过的CompletableFuture再来把它改造一下:
// 使用CompletableFuture发起异步请求
// 这里使用了两个不同的Stream流水线,而不是在同一个处理流的流水线上一个接一个地放置两个map操作
// 这其实是有原因的:考虑流操作之间的延迟特性,如果在单一流水线中处理流,发向不同商家的请求只能以同步、顺序执行的方式才会成功
// 因此,每个创建CompletableFuture对象只能在前一个操作结束之后执行查询指定商家的动作、通知join()方法返回计算结果
public List<String> findPrice(String product) {
List<CompletableFuture<String>> futures =
shops.parallelStream()
.map(shop -> CompletableFuture.supplyAsync(
() -> String.format("%s price is %.2f RMB",
shop.getName(), shop.getPrice(product))))
.collect(Collectors.toList());
return futures.stream()
// 等待所有异步操作结束(join和Future接口中的get有相同的含义)
.map(CompletableFuture::join)
.collect(Collectors.toList());
}
这样一来,新的CompletableFuture对象只有在前一个操作完全结束之后,才能创建。而且使用两个不同的Stream流水线,也可以让前一个CompletableFuture在还未执行完成时,就创建新的CompletableFuture对象。它的执行过程就像下面这样:
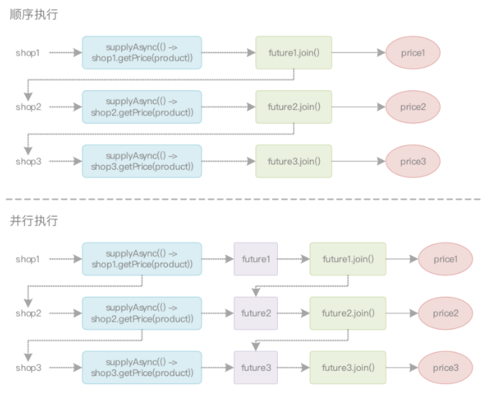
还有没有改进空间呢?当然是有的!但是代码过于复杂,而且在多数情况下,上面列举出的所有代码已经足够解决实际工作中90%的问题了。不过还是把CompletableFuture结合定制Executor的代码贴出来,这样也有个大致的概念(不鼓励钻牛角尖)。
// 使用定制的Executor配置CompletableFuture
public List<String> findPrice(String product) {
// 为“最优价格查询器”应用定制的执行器Execotor
Executor executor = Executors.newFixedThreadPool(Math.min(shops.size(), 100),
(Runnable r) -> {
Thread thread = new Thread(r);
// 使用守护线程,这种方式不会阻止程序的关停
thread.setDaemon(true);
return thread;
}
);
// 将执行器Execotor作为第二个参数传递给supplyAsync工厂方法
List<CompletableFuture<String>> futures = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(
() -> String.format("%s price is %.2f RMB",
shop.getName(), shop.getPrice(product)), executor))
.collect(Collectors.toList());
return futures.stream()
// 等待所有异步操作结束(join和Future接口中的get有相同的含义)
.map(CompletableFuture::join)
.collect(Collectors.toList());
}
这基本上就是CompletableFuture全部的内容了。可以总结一下,对于集合进行并行计算有两种方法:
1、要么将其转化为并行流,再利用map这样的操作开展工作
2、要么枚举出集合中的每一个元素,创建新的线程,在CompletableFuture内操作
CompletableFuture提供了更多的灵活性,它可以调整线程池的大小,确保整体的计算不会因为线程因为I/O而发生阻塞。因此使用建议是:
1、如果进行的是计算密集型操作,且无I/O操作,那么推荐使用并行parallelStream()
2、如果并行的计算单元还涉及等待I/O的操作(包括网络连接等待),那么使用CompletableFuture灵活性更好。
感谢您的大驾光临!咨询技术、产品、运营和管理相关问题,请关注后留言。欢迎骚扰,不胜荣幸~
共同学习,写下你的评论
评论加载中...
作者其他优质文章


