
上一篇自然语言处理中传统词向量表示VS深度学习语言模型(一)主要介绍了关于语言表示的问题,今天在正式接触word2vec之前还是想啰嗦一下自然语言处理的基本问题以及语言模型等方面的知识。
1. 语言模型
语言模型(language model,LM)在自然语言处理中占有重要的地位,尤其在基于统计模型的语音识别、机器翻译、分词和句法分析等相关研究中得到广泛应用。语言模型,简单地说,就是判断一个句子的概率的模型,其基本任务就是使得一个句子更符合自然语言的叙述规则,使得符合这套叙述规则的句子的概率更大。即计算P(S)的概率,其中S为一句话。
早期的自然语言处理系统主要是基于人工撰写的规则,这种方法费时费力,且不能覆盖各种语言现象。上个世纪80年代后期,机器学习算法被引入到自然语言处理中,这要归功于不断提高的计算能力。研究主要集中在统计模型上,这种方法采用大规模的训练语料(corpus)对模型的参数进行自动的学习,和之前的基于规则的方法相比,这种方法更具鲁棒性。
2. 统计语言模型
统计语言模型(Statistical Language Model),就是利用统计数据来求P(S)的大小,在NLP领域中,大部分的任务都是基于词语的细分粒度来构建模型,由词语构成句子,段落,文章等,那么统计语言模型的处理单元当然也多是已词语为单位而展开的。以词语为单位,对于序列S,可以由n个词语W1,W2,W3,...,Wn表示,因此,语言模型可以表示为,求概率P(S)的大小:
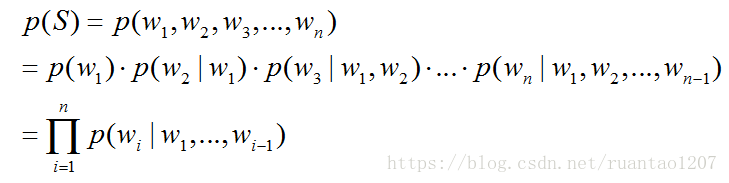
在上式中,产生第i(1≤i≤n)个词的概率是由已经产生的i-1个词决定的,一般的我们将前i-1个词称为第i个词的“历史”或者“上下文”。在这种计算方法中,一方面,随着历史长度的增加,不同的词语的组合数目按照指数级增长。如果历史的长度为i-1,那么,就有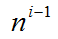 种不同的历史情况存在,这样的话就会存在着参数空间过大的问题;另一方面,对于组合特征中,存在着大量的未出现的组合,这样就导致该组合出现的次数为0,最终导致数据稀疏严重的问题。
种不同的历史情况存在,这样的话就会存在着参数空间过大的问题;另一方面,对于组合特征中,存在着大量的未出现的组合,这样就导致该组合出现的次数为0,最终导致数据稀疏严重的问题。
2.1 N元模型(N-gram)
由于长历史信息的组合数目过大的问题,导致概率无法计算,所以就需要一种替代的方案来近似这个概率,使之得以解决。N元模型就是在这种需求上产生的,N元模型是利用了马尔科夫假设来将求解进行转换,马尔科夫假设认为:随意一个词出现的概率只与它前面出现的有限的一个或者n个词有关。这样就将长历史信息转换为只关注于前面出现的k个历史信息,大大地简化了组合空间。
通常情况下,n不能过大,否则组合空间过大的情况依然存在,无法解决根本问题。所以n一般取1,2,3。
当n=1时,被称为一元语言模型,unigram,说明一个词的出现与它周围的词是独立的,
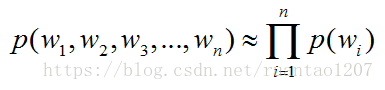
当n=2时,被称为二元语言模型,bigram,也叫一阶马尔科夫链(Markov chain),说明当前词的出现只与其前一个词有关,
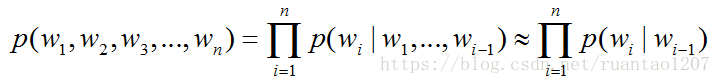
当n=3时,被称为三元语言模型,trigram,也叫二阶马尔科夫链,说明当前词的出现与其前面的两个词有关,
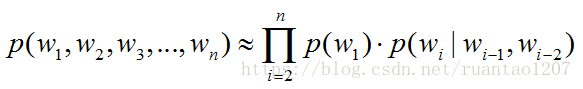
以上内容,我们大致的讲解了n-gram语言模型为什么存在,以及不同的n元gram的形式。总结:语言模型是为了求解语言模型中一个句子产生的概率大小,而n-gram是为了对求解过程中参数空间过大问题的一步优化假设,且基于不同的n有着不同的gram形式。
3.神经网络语言模型
在第2节中,我们知道语言模型可以使用n-gram模型来进行近似求解,可以解决一部分的自然语言处理领域的基础问题,其在词性标注、句法分析、机器翻译、信息检索等任务中起到了重要作用。然而随着深度学习的不断发展,神经网络相关研究越来越深入,神经网络语言模型(Neural Network Language Model,NNLM)越来越受到学术界和工业界的关注,接下来将系统介绍下NNLM。
用神经网络来训练语言模型的思想最早由百度 IDL (深度学习研究院)的徐伟提出NNLM(Nerual Network Language Model)是这方面的一个经典模型,NNLM 依赖的一个核心概念就是词向量(Word Embedding)。词向量源于Hinton在Learning distributed representations of concepts提出的Distributed Representation,Bengio将其引入到语言模型建模中,提出了NNLM。
模型的训练数据是一组词的序列W1,W2,...,Wn,Wn∈V,其中V为词典,Vi表示词典中的第i个单词。NNLM的训练目标也是训练如下模型:
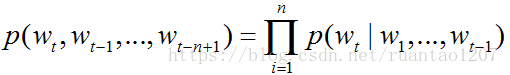
其中表示词序列中第 个单词,w1,...,wt-1表示从第1个词到第 个词组成的子序列。
其模型的框架为:
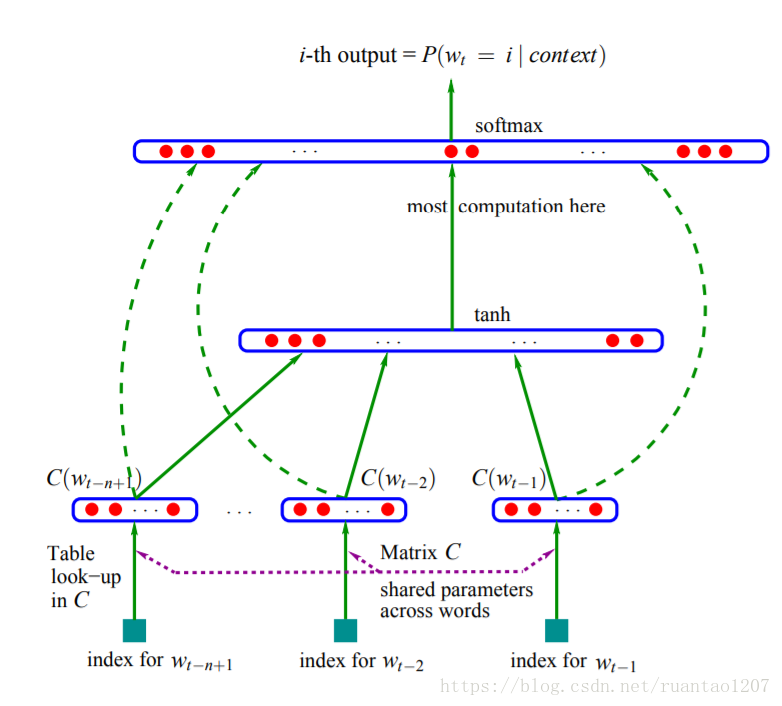
这里的模型主要分为两个部分,特征映射和计算条件概率分布。

这里偷懒了,直接截图过来了。3333~
需要注意的是:一般的神经网络模型不需要对输入进行训练,而该模型中的输入 是词向量,也是需要训练的参数。由此可见模型的权重参数与词向量是同时进行训练,模型训练完成后同时得到网络的权重参数和词向量。word2vec也是通过类似的方式来训练语言模型,最后顺便得到最后的词向量。接下来的博文中将会介绍下word2vec。
特别感谢:
共同学习,写下你的评论
评论加载中...
作者其他优质文章



