
文章摘要:在线上环境遇到数据库死锁问题该如何分析并解决问题呢?
虽然很多童鞋在学数据库课程时都了解数据库隔离级别、死锁和事务等概念,但在测试/线上环境遇到死锁却不一定能够及时分析并解决这类问题。本文主要以作者在测试环境中遇到的一个死锁Case说起,首先还原出现死锁的现场和条件,并结合排查业务应用工程日志、MySQL数据库状态信息等方式,同时给出MySQL锁的基本概念,再通过阅读日志深入定位并分析出现死锁的原因,最后讲下MySQL InnoDB的加锁原理以及如降低死锁发生的机率。
一、出现死锁的当前场景
在测试环境上做业务流程的联调验证自测,在跑自测用例时,突然发现在多线程并发情况下有数据未从业务表中删除完成,通过Spring Boot工程打印出的Log日志中可以看到出现了死锁问题。下面将先给大家还原下死锁的当前场景,然后逐步分析和使用正确方法排查死锁的原因。
1、数据库表结构
CREATETABLE `hw_band_width_bill_record` (
`ID` bigint(20) unsigned NOT NULLAUTO_INCREMENT COMMENT '主键id,自增',
`CUSTOMER_ID` varchar(50) NOT NULL COMMENT ……,
`USER_ID` varchar(50) NOT NULL COMMENT ……,
`CLOUD_SER_TYPE_CODE` varchar(50) NOT NULL COMMENT……,
`RES_TYPE_CODE` varchar(50) NOT NULL COMMENT ……,
`RES_SPEC_CODE` varchar(50) NOT NULL COMMENT ……,
`RES_INSTANCE_ID` varchar(50) DEFAULT NULL COMMENT……,
`RES_ATTR_VALUES` varchar(50) DEFAULT NULLCOMMENT ……,
(限于篇幅问题这里省略该数据表的其他字段)
PRIMARY KEY (`ID`),
KEY`custId_product_res_type_spec_index`(`CUSTOMER_ID`,`RES_TYPE_CODE`,`RES_SPEC_CODE`,`RES_ATTR_VALUES`) USING BTREE)
ENGINE=InnoDBAUTO_INCREMENT=54 DEFAULT CHARSET=utf8 COMMENT='……'
其中,`ID`为主键索引,`CUSTOMER_ID`,`RES_TYPE_CODE`,`RES_SPEC_CODE`,`RES_ATTR_VALUES`等字段组成了非唯一的普通BTREE索引。
2、业务库的事务隔离级别
可以通过“SELECT @@tx_isolation”的SQL来查询当前数据库的事务隔离级别。
mysql>SELECT @@tx_isolation;
+-----------------+
|@@tx_isolation|
+-----------------+
|REPEATABLE-READ |
+-----------------+
1row in set (0.00 sec)
3、业务应用工程的Log日志
当业务应用工程出现异常或者报错时,绝大部分童鞋的第一反应肯定都是去工程对应的Log日志里面去排查定位问题。对应于该死锁问题Case的工程Log日志如下:org.springframework.dao.DeadlockLoserDataAccessException:###Error updating database.Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException:Deadlock found when trying to get lock; try restarting transaction###The error may involveHwBandWidthBillRecordMapper.deleteResBwBillsByIdAndSpecValues-Inline
###The error occurred while setting parameters
###SQL: delete from hw_band_width_bill_recordwhere CUSTOMER_ID = ?and CLOUD_SER_TYPE_CODE = ?and RES_TYPE_CODE = ?and RES_SPEC_CODE = ?and RES_ATTR_VALUES = ?
###Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException:Deadlock found when trying to get lock; try restarting transaction; SQL []; Deadlock
found when trying to get lock; try restarting transaction; nested exception is com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Deadlock found when trying to get lock;try restarting transaction ………(限于篇幅问题这里省略了部分日志) Caused by:com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Deadlockfound when trying to get lock; try restarting transaction
从以上打印的堆栈日志里面可以清楚的发现业务工程代码在多线程并发的环境下执行了Delete SQL语句后出现了死锁异常。不过,仅仅通过上述日志还不足以清楚地分析和查明出现死锁异常的根本原因,那怎么办?下面将通过MySQL的InnoDB的状态日志进行进一步的深入分析。
4、MySQL数据库死锁日志信息
可能很多做过开发的童鞋都没有自己登录过数据库服务器,排查过MySQL的InnoDB Status的状态日志信息来深入分析死锁问题。这里,我们可以先进入测试/线上环境数据库虚拟机的数据库安装bin目录下,通过“mysql-h localhost -P 3306 -u test -p”命令来连接登录。然后使用“SHOW ENGINE INNODB STATUS”命令查询数据库的最近一次死锁日志信息。这里需要注意的是,该命令只能查看到最近一条死锁日志信息,如果想看到多条历史死锁可以在MySQL中把死锁信息打印到错误日志里,开启如下变量即可:
set global innodb_print_all_deadlocks= 1;
本Case中的死锁日志信息如下:
------------------------
LATESTDETECTED DEADLOCK
------------------------
2017-12-0519:46:52 7f6d3e588700
***(1) TRANSACTION: TRANSACTION10375675, ACTIVE 0 sec fetching rows mysqltables in use 1, locked 1 LOCKWAIT 4 lock struct(s), heap size 1184, 2 row lock(s), undo log entries 4
MySQLthread id 550477, OS thread handle 0x7f6db6ab8700, query id 33896336 10.129.3.1test updating
deletefrom hw_band_width_bill_record where CUSTOMER_ID ='0314e4814d014eaabf4ab09f7fa97fed' and CLOUD_SER_TYPE_CODE ='hws.service.type.vpc' and RES_TYPE_CODE ='hws.resource.type.bandwidth' and RES_SPEC_CODE = '19_bgp' and RES_ATTR_VALUES ='{"specSize":1}'
***(1) WAITING FOR THIS LOCK TO BE GRANTED: RECORDLOCKS space id 1369 page no 3 n bits 104 index `PRIMARY` of table`res_hw_cloud_bill`.`hw_band_width_bill_record` trx id 10375675 lock_mode Xlocks rec but not gap waiting
***(2) TRANSACTION:
TRANSACTION10375676, ACTIVE 0 sec starting index read, thread declared inside InnoDB 5000 mysqltables in use 1, locked 1 4lock struct(s), heap size 1184, 3 row lock(s), undo log entries 5 MySQLthread id 550478, OS thread handle 0x7f6d3e588700, query id 33896338 10.129.3.1test updating
deletefrom hw_band_width_bill_record where CUSTOMER_ID = '0314e4814d014eaabf4ab09f7fa97fed' and CLOUD_SER_TYPE_CODE ='hws.service.type.vpc' and RES_TYPE_CODE ='hws.resource.type.bandwidth' and RES_SPEC_CODE = '19_bgp' and RES_ATTR_VALUES ='{"specSize":6}'
***(2) HOLDS THE LOCK(S):
RECORDLOCKS space id 1369 page no 3 n bits 104 index `PRIMARY` of table`res_hw_cloud_bill`.`hw_band_width_bill_record` trx id 10375676 lock_mode Xlocks rec but not gap
***(2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORDLOCKS space id 1369 page no 3 n bits 104 index `PRIMARY` of table`res_hw_cloud_bill`.`hw_band_width_bill_record` trx id 10375676 lock_mode Xlocks rec but not gap waiting
***WE ROLL BACK TRANSACTION (1)
------------
TRANSACTIONS
------------
从上面打印的这段日志中,我们可以进行一定的初步分析。从这段日志里可以看到,TRANSACTION 1和TRANSACTION 2分别持有一定数量的行锁,然后又等待对方的锁,最后MySQL检测到Deadlock,然后选择回滚了TRANSACTION 1:InnoDB目前处理死锁的方法是将持有最少行级排他锁的事务进行回滚。
二、对于业务库死锁的深入分析
在进一步深入分析MySQL的死锁日志之前有必要先了解下MySQL数据库的MVCC机制、锁的概念和事务隔离级别。
1、MySQL InnoDB的MVCC机制与锁的模型概念
MySQL InnoDB存储引擎,实现了基于多版本的并发控制协议—MVCC (Multi-Version Concurrency Control)。InnoDB存储引擎MVCC机制的优点可以总结为,“读不加锁,读写不冲突”。这在读多写少的业务应用中,读写不冲突是非常重要的,极大的增加了系统的并发度和解决各种性能问题。在InnoDB中常见的几种锁模型如下:
(1)LOCK_ORDINARY[next_key_lock],默认是LOCK_ORDINARY,即next-keylock,锁住行及其前面的间隙,其为行级记录锁和间隙锁的结合,用于解决幻读的问题。
(2)LOCK_GAP:间隙锁,锁住行以前的间隙,不锁住本行。
(3)LOCK_REC_NOT_GAP:行级锁,锁住行而不锁住任何间隙。
(4)LOCK_INSERT_INTENTION:插入意向锁,如果插入的记录在某个已经锁定的间隙内为这个锁。
因此在InnoDB中,读操作大致可以概括为两类:快照读(snapshot read)与当前读(current read)。快照读,读取的是记录的可见版本(有可能是历史版本),不用加锁。当前读,读取的是记录的最新版本,并当前读返回的记录,都会加上锁,保证其他事务不会再并发修改这条记录。
(a)快照读
一般来说,简单的Select SQL语句都属于快照读,例如“select * from where……”
(b)当前读
对于“insert/delete/update”等增删改的SQL语句,属于当前读,需要加锁。例如如下语句:
select * from tablewhere ? lock in share mode;
select * from tablewhere ? for update;
insert into tablevalues (…);
update table set ?where ?;
delete from tablewhere ?;
2、说说数据库的隔离级别
数据库的事务隔离级别—Isolation Level,是数据库的一个关键特性。相信对数据库原理有所了解的朋友,一定都对4种隔离级别:Read Uncommited,Read Committed,Repeatable Read,Serializable有了比较深入的认识。这里就不再对这4种隔离级别的定义进行详细的阐述了,而是主要跟大家介绍下在MySQL InnoDB存储引擎中对于上述的“当前读”,在这四种不同的隔离级别情况下加锁情况有何区别?(一般“快照读”可以忽略,基本一样的)
(1)Read Uncommited(未提交读)
在该级别下,可以读取未提交记录。此隔离级别,一般不太会使用。
(2)Read Committed(提交读)
在该级别下,针对“当前读”,RC隔离级别保证对读取到的记录加锁(记录锁),而不会在记录之间加间隙锁,允许新的记录插入到被锁定记录的附近,所以再多次使用查询语句时,可能得到不同的结果,允许不可重复读。
(3)Repeatable Read(可重复读)
在该级别下,针对“当前读”,RR隔离级别保证对读取到的记录加锁(记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入(间隙锁,但是在唯一索引和非唯一索引条件下还是有一定区别的),解决了不可重复读的问题,但可能存在幻读(幻读可以通过Next-Key锁解决)。
(4)Serializable(序列化)
在该级别下,InnoDB隐式将全部读操作视为“当前读”,并且要求事务序列化一个接一个执行。因此,并发度急剧下降,一般情况下也不太会使用该隔离级别。
3、分析死锁日志信息与降低死锁的方法
通过上文的初步分析和对MySQL InnoDB死锁的基本模型/DB事务隔离级别的介绍,现在再回过头来看下本Case中的死锁日志信息,应该就会有一些相对深刻的理解了。下面将进一步给大家做更深入的分析,在篇幅的最后给出自己总结的一些降低死锁发生频率的大致方法。
(1)死锁日志中信息提取
TRX1:10375675(出发死锁权重回滚)
LOCK HOLD:没有提供该事务获取到的锁
LOCKWAIT:
表:hw_band_width_bill_record
索引:`PRIMARY`
锁模式:LOCKX|LOCK_REC_NOT_GAP
记录:space id1369 page no 3 n bits 104
锁的信息:该事务总共有2个行锁,持有1个行锁,另外一个1锁处于锁等待状态
当前发生死锁的SQL语句:delete from hw_band_width_bill_record where CUSTOMER_ID = '0314e4814d014eaabf4ab09f7fa97fed' andCLOUD_SER_TYPE_CODE = 'hws.service.type.vpc' andRES_TYPE_CODE = 'hws.resource.type.bandwidth' andRES_SPEC_CODE = '19_bgp' andRES_ATTR_VALUES = '{"specSize":1}'
TRX2:10375676
LOCK HOLD:该事务持有锁的大致信息(锁的模式为:LOCK X|LOCK_REC_NOT_GAP)LOCKWAIT:
LOCKWAIT:
表:hw_band_width_bill_record
索引:`PRIMARY`
锁模式:LOCKX|LOCK_REC_NOT_GAP
记录:space id 1369 pageno 3 n bits 104
锁的信息:该事务总共有3个行锁,持有2个行锁,另外一个行锁处于锁等待状态
当前发生死锁的SQL语句:deletefrom hw_band_width_bill_record where CUSTOMER_ID ='0314e4814d014eaabf4ab09f7fa97fed' and CLOUD_SER_TYPE_CODE ='hws.service.type.vpc' and RES_TYPE_CODE ='hws.resource.type.bandwidth' and RES_SPEC_CODE = '19_bgp' and RES_ATTR_VALUES ='{"specSize":6}'、
从以上MySQL InnoDB死锁日志的提取信息中即可看到,事务1和事务2有分别在等待对方的锁释放,形成了一个环,因此产生了数据库的死锁。
(2)InnoDB行锁难道锁的不只是一行?
由于本Case中所建的数据库表是用InnoDB引擎的,InnoDB支持行锁和表锁。而InnoDB行锁的原理是通过给索引上的索引项加锁来实现的。而这一点MySQL与Oracle数据库有差别,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB这种行锁实现特点表示:只有通过索引条件检索数据,InnoDB才使用行级锁。如果未走到索引上,InnoDB将使用表锁,会把执行SQL语句中所有扫描过的行都锁定(这里需要注意的是,如果在RR事务隔离级别下且索引为非唯一索引,不仅会对数据表中的每一行加上LOCK_REC_NOT_GAP的行锁,而且还会两数据行的间隙加上LOCK_GAP间隙锁)。在实际的业务应用开发中,要特别注意InnoDB行锁的这一特性,否则可能导致大量的锁冲突,从而影响系统并发性能。由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁。所以虽然是访问不同行的记录,但是如果是使用相同的索引键,也同样会出现锁冲突的。当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁。
下面可以先看下在该Case中,我们业务表索引的情况。如下图可以看到执行的Delete SQL语句走的是范围扫描,未正确走到建立的索引上(对于如何正确建立索引的问题可以看下之间写的《大型分布式业务平台数据库常用优化方法(上)》篇,该篇幅介绍索引的原理和如何正确使用索引)
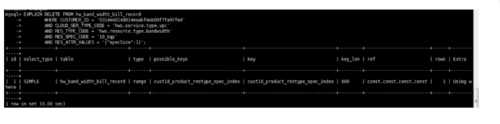
了解MySQL InnoDB的加锁原理和如何正确加索引后,只要调整下创建索引的字段(即为创建索引使用上图中的where条件的5个字段,然后执行Delete SQL语句即可实现覆盖索引,MySQL InnoDB加的锁为对应的行锁和行之间的GAP锁)即可让咱们的Delete SQL语句精确走到索引以缓解死锁的问题。实际上,我再更新索引后,死锁问题也确实得到了解决。
(3)MySQL InnoDB锁与索引/隔离级别的关系
从上述篇幅中可以得到的结论是,“InnoDB行锁的原理是通过给索引上的索引项加锁来实现”,我们知道InnoDB对于主键使用了聚簇索引,这是一种数据存储方式,表数据是和主键一起存储,主键索引的叶结点存储行数据。对于普通索引,其叶子节点存储的是主键值。相信仔细阅读了上面篇幅的同学,对执行未正确落到索引的“当前读”SQL,InnoDB引擎都会加表锁的这一行为比较熟悉,因此这里不再赘述业务表无索引这一情况。这一节将通过2个小例子,来进一步阐述大家,在InnoDB引擎中可能不太会被关注到的锁与索引/隔离级别的两种关系。
1.非唯一索引+RC隔离级别
在下面第一个的实例中,假设数据库的隔离级别为Read Committed隔离级别,表为table1(表字段由“id”、“token”和“message”组成,其中id字段为自增的主键,在token字段上建了一个非唯一索引),如果此时执行“delete from table1 where token = ‘asd’”,那么加锁的情况会怎么样呢?先来看下面这幅图:
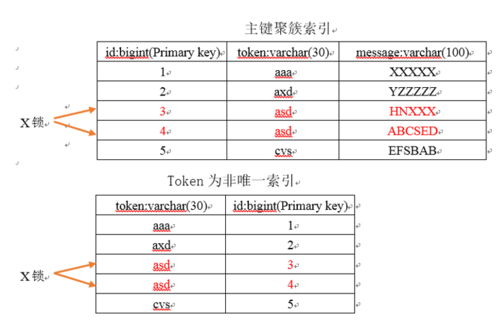
可以看到,由于token列上有非唯一索引,那么对应的所有满足SQL查询条件的记录,都会被加锁。同时,这些记录在主键索引上的记录,也会被加锁。
2.非唯一索引+RR隔离级别
在接下来的第二个实例中,假设将原来数据库的隔离级别为由上面的RC级别改为,Repeatable Read隔离级别,表table1字段和索引均不变(表字段由“id”、“token”和“message”组成,其中id字段为自增的主键,在token字段上建了一个非唯一索引),如果此时仍然执行上面这句SQL—“delete from table1 where token = ‘asd’”,那么最后的加锁行为会怎么样的呢?可以先来看下下面这幅图:
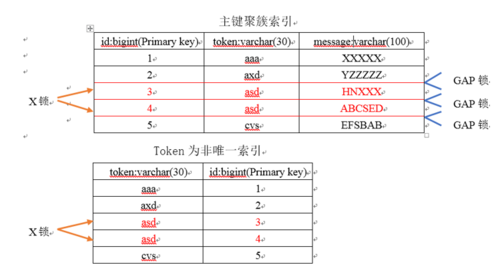
在上图中,相对于前面的[Read Committed级别下token非唯一索引条件]看似相同,其实却有很大的区别。主要区别在于,这幅图中多了一个GAP锁,而且GAP锁看起来不是加在记录上的,是加载两条记录之间的位置。这里的GAP锁,就是在RR隔离级别下,相对于RC隔离级别,不会出现的不可重复读的关键。确实,这个GAP锁,锁住的位置,也不是记录本身,而是两条记录之间的间隙。所谓不可重复读,就是同一个事务,连续做两次当前读 (例如:select * from table1 where token = ‘asd’ for update;),那么这两次当前读返回的是完全相同的记录 (记录数量一致,记录本身也一致),第二次的当前读,不会比第一次返回更多的记录 。然而在RR级别下,并不能解决幻影读的问题。在标准的数据库事务隔离级别中,幻读是由更高的隔离级别 SERIALIZABLE 解决的,但是它也可以通过上文提到过的MySQL的 Next-Key 锁解决(限于篇幅问题,这里就不展开介绍Next-Key锁了)。
因此,在RR隔离级别下,token列上有一个非唯一索引,对应SQL:delete from table1 where token = ‘asd’;首先,通过token索引定位到第一条满足查询条件的记录,先在记录上加X锁,在数据行之间的间隙加上GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录为止,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
(4)如何降低发生MySQL InnoDB死锁?
DB死锁在行锁及事务场景下很难完全消除,但可以通过表设计和SQL调整等措施减少锁冲突和死锁,下面列举了一些降低死锁发生的主要方法:
a.尽量使用较低的隔离级别,比如如果发生了GAP间隙锁,可以尝试把DB的事务隔离级别调整成为RC(read committed)级别来避免。当然在RC的隔离级别下需要考虑业务是否能够接受“不可重复读”的问题;
b.在业务上线之前精心设计并核查下业务表上创建的索引。业务工程DAO层中的SQL语句尽量使用索引访问数据(如果对于自己的业务SQL不确定,可以使用“Explain”关键字来查看对应的执行计划是怎么样的),使加锁更精确,从而减少锁冲突的机会;
c.选择合理的事务大小,小事务发生锁冲突的概率一般也更小;对于使用Spring Transaction注解的同学,也可以考虑使用其编程式声明Spring事务模板的方式来将类或者方法级别的事务划分给代码块更小级别的事务。
d.在不同线程中去访问一组DB的数据表时,尽量约定以相同的顺序进行访问;对于同一个单表而言,尽可能以固定的顺序存取表中的行。这样可以大大减少死锁的机会;
e.对于一些特定的业务流程,可以使用提升DB锁粒度的方式(在业务允许的情况下降低一定的并发度),比如表锁,来减少出现死锁的可能。
本文从一次测试环境的DB死锁Case出发,首先还原了发生死锁的当前场景,给出包括数据表结构、业务库的事务隔离级别、工程日志和数据库死锁日志在内的信息;然后从这些信息中逐步分析,先介绍了InnoDB的锁模型和MVCC机制,以及在四种不同隔离级别下当前读的不同区别;最后根据从死锁日志出提取的信息出发分析了死锁的根本原因,并给出降低死锁产生几率的一般方法。限于笔者的才疏学浅,对MySQL InnoDB的死锁可能还有理解不到位的地方,如有阐述不合理之处还望留言一起探讨。
作者:癫狂侠
链接:https://www.jianshu.com/p/db849c50f2dc
共同学习,写下你的评论
评论加载中...
作者其他优质文章


