
前几天搞清楚了spark是如何并行计算的,今天才想起来要记录一下,为什么突然搞清楚了?因为在此之前我才彻彻底底清楚了spark中RDD的前世今生,因为之前对RDD的概念模糊,所以导致对其余相关知识也是一知半解。
这是我上一篇结合hdfs对RDD的一个讲解(如果不明白,建议先看):对spark中RDD的partition通俗易懂的介绍
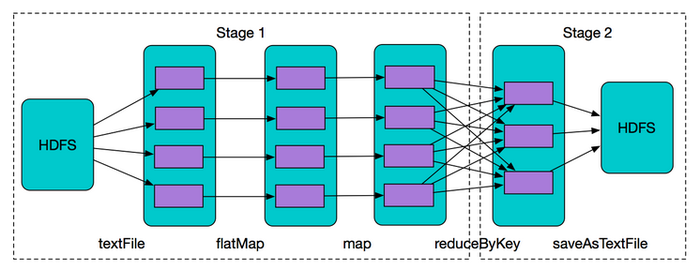
wordCount示意图
上图乃是一个非常传统的wordCount示意图,在这个程序中,Driver会把该application切分为多个job,因为每执行到一个action操作就会创建一个job,所以该程序只会有一个job,至于什么是action操作,道友网上找找就好,介绍这个东西的比比皆是。
随后,我们会有一个叫做DAGScheduler调度器的东西将上述的job切分为多个stage,从上图不难看出,stage的切分是通过宽依赖来切分的。
再随后,我们上述的每个stage下就会创建个TaskSet,这时,我们又有一个叫TaskScheduler的调度器将我们TaskSet中的每个task分配到各个worker上去执行,至于怎么分配,我上面的文章链接也说过。待执行完毕,返回Driver去汇总或存储。
可能有人还是对job,stage,task三者的关系不是很清楚,那么我们看下图。
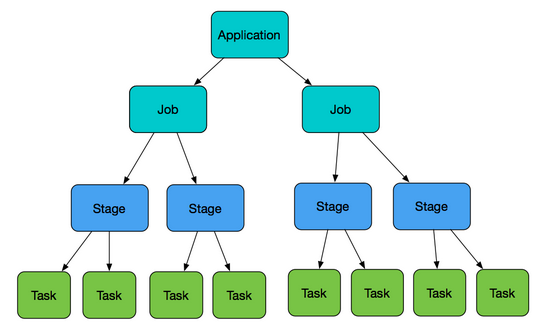
层次划分关系)
上述应该讲的很明确了,唯一没有说到的就是这个stage下的任务是如何划分的,stage下的每一个task实则对应操作RDD内的一个partition。所以说,浏览此文章之前应该先看一遍上方链接文章。
(如果对您有所帮助话,那就点个赞吧,嘻嘻~~)
作者:飞叔Brother
链接:https://www.jianshu.com/p/49b340bcd6a5
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



