
asyncio于Python3.4引入标准库,增加了对异步I/O的支持,asyncio基于事件循环,可以轻松实现异步I/O操作。接下来,我们用基于asyncio的库实现一个高性能爬虫。
准备工作
Earth View from Google Earth是一款Chrome插件,会在打开新标签页时自动加载一张来自Google Earth的背景图片。
Earth View from Google Earth
使用Chrome开发者工具观察插件的网络请求,我们发现插件会请求一个地址如https://www.gstatic.com/prettyearth/assets/data/v2/1234.json的JSON文件,文件中包含了经过Base64的图片内容,观察发现,图片的ID范围大致在1000-8000之间,我们的爬虫就要来爬取这些精美的背景图片。
实现主要逻辑
由于爬取目标是JSON文件,爬虫的主要逻辑就变成了爬取JSON-->提取图片-->保存图片。
requests是一个常用的http请求库,但是由于requests的请求都是同步的,我们使用aiohttp这个异步http请求库来代替。
async def fetch_image_by_id(item_id):
url = f'https://www.gstatic.com/prettyearth/assets/data/v2/{item_id}.json'
# 由于URL是https的,所以选择不验证SSL
async with aiohttp.ClientSession(connector=aiohttp.TCPConnector(verify_ssl=False)) as session: async with session.get(url) as response: # 获取后需要将JSON字符串转为对象
try:
json_obj = json.loads(await response.text()) except json.decoder.JSONDecodeError as e:
print(f'Download failed - {item_id}.jpg') return
# 获取JSON中的图片内容字段,经过Base64解码成二进制内容
image_str = json_obj['dataUri'].replace('data:image/jpeg;base64,', '')
image_data = base64.b64decode(image_str)
save_folder = dir_path = os.path.dirname(
os.path.realpath(__file__)) + '/google_earth/'
with open(f'{save_folder}{item_id}.jpg', 'wb') as f:
f.write(image_data)
print(f'Download complete - {item_id}.jpg')aiohttp基于asyncio,所以在调用时需要使用async/await语法糖,可以看到,由于aiohttp中提供了一个ClientSession上下文,代码中使用了async with的语法糖。
加入并行逻辑
上面的代码是抓取单张图片的逻辑,批量抓取图片,需要再嵌套一层方法:
async def fetch_all_images(): # 使用Semaphore限制最大并发数 sem = asyncio.Semaphore(10) ids = [id for id in range(1000, 8000)] for current_id in ids: async with sem: await fetch_image_by_id(current_id)
接下来,将这个方法加入到asyncio的事件循环中。
event_loop = asyncio.get_event_loop() future = asyncio.ensure_future(fetch_all_images()) results = event_loop.run_until_complete(future)
使用uvloop加速
uvloop基于libuv,libuv是一个使用C语言实现的高性能异步I/O库,uvloop用来代替asyncio默认事件循环,可以进一步加快异步I/O操作的速度。
uvloop的使用非常简单,只要在获取事件循环前,调用如下方法,将asyncio的事件循环策略设置为uvloop的事件循环策略。
asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
使用上面的代码,我们可以快速将大约1500张的图片爬取下来。
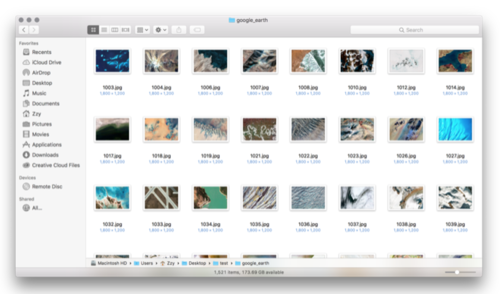
爬取下来的Google Earth图片
性能对比
为了验证aiohttp和uvloop的性能,笔者使用requests+concurrent库实现了一个多进程版的爬虫,分别爬取20个id,消耗的时间如图。
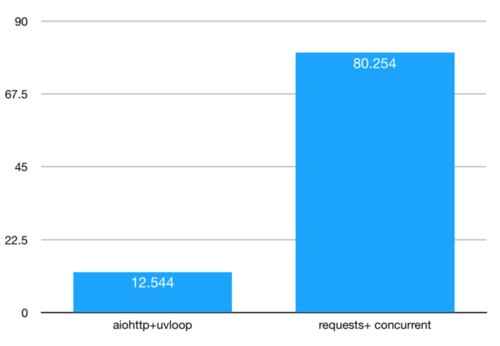
可以看到,耗时相差了大概7倍,aiohttp+uvloop的组合在爬虫这种I/O密集型的场景下,可以说具有压倒性优势。相信在不远的将来,基于asyncio的库会将无数爬虫工程师从加班中拯救出来。
作者:simpleapples
链接:https://www.jianshu.com/p/8f65e50f39b4
共同学习,写下你的评论
评论加载中...
作者其他优质文章



