
本文实现拉勾网的爬虫,抓取招聘需求,统计出的词频前70的关键词,当然数量可以自己定,以深圳市的python招聘岗位为例。
1、爬虫老套路,分析浏览器请求,然后模仿之
先手动打开拉勾的招聘链接,进行搜索,观察浏览器的行为
https://www.lagou.com/zhaopin/
搜索python后页面显示很多职位信息,然后打开 chrome 开发者工具查看这个页面的response,发现响应中找不到岗位信息
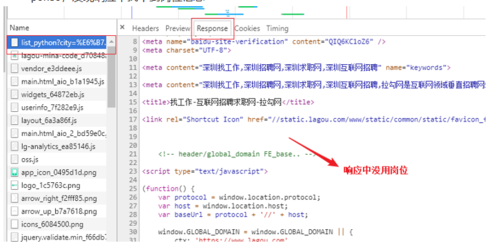
查看开发者工具中的响应
这样看来就是用ajax来请求的数据了,把这个ajax请求找到,发现岗位信息都在这个响请求中,form data中的pn就是页码,kd是关键字
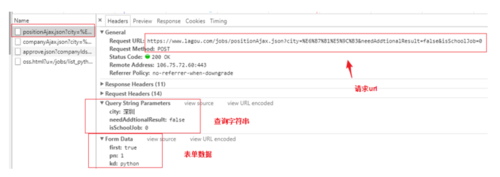
找到响应的ajax请求
于是模仿这个来发起请求,先获取第一页(这里有一个坑,如果请求头没有 Referer 字段,请求不到数据,反爬的常用手段,直接复制上面找到的请求中的就行)
import requestsimport json
class LagouCrawl(object):
def __init__(self):
self.url = "https://www.lagou.com/jobs/positionAjax.json"
# 请求头
self.headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36", "Referer": "https://www.lagou.com/jobs/list_python"
} # 查询字符串
self.params = { "city": "深圳", "needAddtionalResult": False, "isSchoolJob": 0
} # 表单数据
self.data = { "first": True, "pn": 1, "kd": 'python'
}
def start_crawl(self):
response = requests.post(self.url, params=self.params, data=self.data, headers=self.headers)
data = response.content.decode('utf-8')
dict_data = json.loads(data)
print(dict_data)
if __name__ == '__main__':
spider = LagouCrawl()
spider.start_crawl()这里得到一个 json 数据,里面有每条招聘的hr信息,招聘信息,我们需要的是以下的信息,都可以得到,以便于持续翻页得到所有的数据:
当前页的数量
总页数
符合条件的招聘条数
详情页的positionid,拼接出详情页url
整个数据比较长,只展示 positionId 的位置

部分json数据字段
拼接出详情页的url
def build_detail_url(self, data, num): # num 是一页的数量 for i in range(num): position_id = data['content']['positionResult']['result'][i]['positionId'] url = INFO_URL % position_id
然后再访问详情页,通过 xpath 提取详情页内的需求文字(需要掌握xpath提取规则),下面的 info_text 就是提取出的文字
from lxml import etree
def parse_html(self, html):
obj_xpath = etree.HTML(html)
node = obj_xpath.xpath("//dd[@class='job_bt']")
info_node = node[0]
info_text = info_node.xpath("string(.)").strip() return info_text调用下面方法,得到的数据保存到 txt 中
def save_data(self, data):
with open('info.txt', 'a', encoding='utf-8') as f:
f.write(data)这样得到的只是一页的,修改上面的代码把请求的页码做一个累加,爬取所有(连续爬取会出现问题,拉勾设置了访问频率,大概一分钟5次的样子,需要延时)
2、得到数据,利用它来干一些事情
用 jieba 分词读取所有内容进行分词,并使用 wordcloud 生成词频图,setting.py 设置一些频率高会影响结果的词与默认的停用词并集,一起过滤。
import jieba.analyse # 导入结巴分词import numpy as np # numpyfrom wordcloud import WordCloud, STOPWORDS # 词云工具和自带的的停用词from PIL import Image # 图片处理from setting import STOPWORD_NEW # 自定义了一个setting.py,过滤一些无关的词
def handle(filename, stopword):
with open(filename, 'r', encoding='utf-8') as f:
data = f.read()
wordlist = jieba.analyse.extract_tags(data, topK=70) # 分词,取前70
wordStr = " ".join(wordlist)
hand = np.array(Image.open('hand.jpg')) # 打开一张图片,词语以图片形状为背景分布
my_cloudword = WordCloud( # wordcloud参数配置
background_color = 'black', # 背景颜色
mask = hand, # 背景图片
max_words = 300, # 最大显示的字数
stopwords = stopword, # 停用词
max_font_size = 60, # 字体最大值
)
my_cloudword.generate(wordStr) # 生成图片
my_cloudword.to_file('wordcloud.png') # 保存
if __name__ == '__main__':
handle('python.txt', STOPWORDS | STOPWORD_NEW)3、最后把整个程序再修改一下
用协程进行多任务(因为拉勾限制了爬取频率,中间大部分时间用来休眠了,并所以没起到作用,可以用代理池解决,这里没使用)
增加了拉勾所有城市的爬取
可以手动输入城市和关键字进行职位搜索
修改后目录结构如下:

目录结构
整个过程:爬虫启动时,开启两个协程,一个请求获取json数据,构建详情页url,扔进队列中,另一个从队列拿取url,爬岗位需求(这里可以用多个协程一起爬的,但拉勾访问频率限制了,只用了一个,中间休眠很久,很慢),用 queue.join() 阻塞主进程,当队列任务执行完后调用 HandleData 模块的方法,读取数据生成图,效果图如下。

背景图

词云效果
END
作者:谦面客
链接:https://www.jianshu.com/p/16cd37a5355f
共同学习,写下你的评论
评论加载中...
作者其他优质文章



