
在爬虫时,某些网站会有封ip的现象,所以选择利用代理伪装我们的ip进行爬虫请求,但进行爬虫时可能需要很多ip,这时就要求维护一个代理池(池也就是代理队列),可放进代理,也可取出代理。
本文中选择的崔庆才老师维护的代理池,是用Flask和Redis维护的一个代理池。设计的基本思路
从各大网站获取免费的有用代理
用Redis来维护池的队列存储
维护池,剔除无用的代理,获得有用的代理
Flask是实现代理池的一个接口,返回到web上
抓取微信文章思路
通过搜狗爬取微信文章
前十页信息不需要验证,10页到100页需要微信登录验证
发现浏览多页后会返回302状态码,跳到反爬虫的页面,此时的ip已经被封,需要输入3次验证码才能继续浏览
具体抓取步骤
1.抓取索引页内容:利用requests请求目标站点,得到索引网页HTML代码,返回结果。
2.代理设置:如果遇到302状态码,则证明IP被封,切换代理重试
3.分析详情页内容:请求详情页,分析得到标题,正文等内容
4.将数据保存到数据库
抓取索引页内容
import requests
from requests.exceptions import RequestException
from urllib.parse import urlencode
base_url='http://weixin.sogou.com/weixin?'def get_index(keyword,page): #get请求参数
data={ 'query':keyword, 'type':2, 'page':page
}
queries=urlencode(data) #把key-value这样的键值对转换格式,返回a=1&b=1这样的字符串
url=base_url + queries
html=get_html(url) print(html)
headers={ "Cookie":"GOTO=Af12649; SUV=00E5B570B70C546D5978B8154B874361; IPLOC=CN4403; SUID=6D540CB73320910A000000005978B816; pgv_pvi=1861927936; ABTEST=0|1502751070|v1; weixinIndexVisited=1; SNUID=8CBAF940F7F2AE29D86AFAC9F8AC0210; ld=TZllllllll2BKv3rlllllVuUeVyllllltq7@nyllllwlllll9llll5@@@@@@@@@@; LSTMV=201%2C260; LCLKINT=27637; sw_uuid=3851573336; sg_uuid=3001557157; ssuid=8893341825; dt_ssuid=7044358220; usid=XUhtela4MuqO4WYt; pgv_si=s423112704; JSESSIONID=aaaJ940C2hKSEd-V85U3v; sct=24; ppinf=5|1503111208|1504320808|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo3Omluc2lnaHR8Y3J0OjEwOjE1MDMxMTEyMDh8cmVmbmljazo3Omluc2lnaHR8dXNlcmlkOjQ0Om85dDJsdU1zWmxsOWVLRTNwb0M5TTMwLXFVSU1Ad2VpeGluLnNvaHUuY29tfA; pprdig=r6cB7eM-w6v2tvRQ42QrnnZYg1bhefjDUAxJ3pkm2ZzalCVcFlv74Mx4Ubz7E8NroDnQ1oTPxNJkYeBCkI8yqM9VNk7bHeTyMqT8wWjMz6rgh2dzXUE7wb1LGbInPhNUN_A1dTW0QoyV4ZNWaEgik3hYqi1EQwUaVoHAmy-pHLc; sgid=08-30426875-AVmXqCiaDYuwr4vkbBuwLlw0; ppmdig=1503121994000000ef911d3ebbde56dd937521fdd5448948", "Host": "weixin.sogou.com", 'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3226.400 QQBrowser/9.6.11681.400'} #为了能够看到100页后的东西,我们必须登录,这里的cooies就包括我们登录的效果def get_html(url):
try:
response=requests.get(url,allow_redirects=False,headers=headers)#不让自动跳转????
if response.status_code==200: return response.text if response.status_code==302: #此时ip被封了,需要代理池poxy
pass
except ConnectionError: return get_html(url)if __name__ == '__main__':
get_index('风景',1)
输出的部分结果:
<!doctype html>
<html>
<head>
<link rel="shortcut icon" href="http://logo.www.sogou.com/images/logo2014/new/favicon.ico" type="image/x-icon">
<link href="/logo-safari.png?v=20170315" id="apple-touch-icon" rel="apple-touch-icon-precomposed"/>
<link href="https://www.sogou.com/sug/css/m3.min.v.7.css" rel="stylesheet" type="text/css">
<link href="/new/pc/css/weixin-public-new.min.css?v=20170315" rel="stylesheet" type="text/css">
<link href="/new/pc/css/datepicker.min.css?v=20161107" rel="stylesheet" type="text/css">
<meta http-equiv="X-UA-Compatible" content="IE=Edge">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta content="width=device-width,initial-scale=1.0" id="vp" name="viewport">
<title>风景的相关微信公众号文章 – 搜狗微信搜索</title>
<script>显然上面的请求是成功的,但是只要请求10十次以上,我们的ip就会出现被封的现象。下面我们加入一个for循环来验证一下。
import requestsfrom requests.exceptions import RequestExceptionfrom urllib.parse import urlencode
base_url='http://weixin.sogou.com/weixin?'def get_index(keyword,page): #get请求参数
data={ 'query':keyword, 'type':2, 'page':page
}
queries=urlencode(data) #把key-value这样的键值对转换格式,返回a=1&b=1这样的字符串
url=base_url + queries
html=get_html(url) return html
headers={ "Cookie":"GOTO=Af12649; SUV=00E5B570B70C546D5978B8154B874361; IPLOC=CN4403; SUID=6D540CB73320910A000000005978B816; pgv_pvi=1861927936; ABTEST=0|1502751070|v1; weixinIndexVisited=1; SNUID=8CBAF940F7F2AE29D86AFAC9F8AC0210; ld=TZllllllll2BKv3rlllllVuUeVyllllltq7@nyllllwlllll9llll5@@@@@@@@@@; LSTMV=201%2C260; LCLKINT=27637; sw_uuid=3851573336; sg_uuid=3001557157; ssuid=8893341825; dt_ssuid=7044358220; usid=XUhtela4MuqO4WYt; pgv_si=s423112704; JSESSIONID=aaaJ940C2hKSEd-V85U3v; sct=24; ppinf=5|1503111208|1504320808|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo3Omluc2lnaHR8Y3J0OjEwOjE1MDMxMTEyMDh8cmVmbmljazo3Omluc2lnaHR8dXNlcmlkOjQ0Om85dDJsdU1zWmxsOWVLRTNwb0M5TTMwLXFVSU1Ad2VpeGluLnNvaHUuY29tfA; pprdig=r6cB7eM-w6v2tvRQ42QrnnZYg1bhefjDUAxJ3pkm2ZzalCVcFlv74Mx4Ubz7E8NroDnQ1oTPxNJkYeBCkI8yqM9VNk7bHeTyMqT8wWjMz6rgh2dzXUE7wb1LGbInPhNUN_A1dTW0QoyV4ZNWaEgik3hYqi1EQwUaVoHAmy-pHLc; sgid=08-30426875-AVmXqCiaDYuwr4vkbBuwLlw0; ppmdig=1503121994000000ef911d3ebbde56dd937521fdd5448948", "Host": "weixin.sogou.com", 'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3226.400 QQBrowser/9.6.11681.400'}
keyword='风景'def get_html(url):
try:
response=requests.get(url,allow_redirects=False,headers=headers)#不让自动跳转????
if response.status_code==200: return response.text if response.status_code==302: #此时ip被封了,需要代理池poxy
print(302) except ConnectionError: return get_html(url)def main():
for page in range(1,100):
html=get_index(keyword,page) print (html)if __name__ == '__main__':
main()
输出的部分结果:302None302None302None302None所以接下为解决反爬虫这一问题,应该使用代理池
设置代理
from urllib.parse import urlencode
import pymongo
import requests
from lxml.etree import XMLSyntaxError
from requests.exceptions import ConnectionError
from pyquery import PyQuery as pq
from config2 import *
client = pymongo.MongoClient(MONGO_URI)
db = client[MONGO_DB]
base_url = 'http://weixin.sogou.com/weixin?'headers={ "Cookie":"GOTO=Af12649; SUV=00E5B570B70C546D5978B8154B874361; IPLOC=CN4403; SUID=6D540CB73320910A000000005978B816; pgv_pvi=1861927936; ABTEST=0|1502751070|v1; weixinIndexVisited=1; SNUID=8CBAF940F7F2AE29D86AFAC9F8AC0210; ld=TZllllllll2BKv3rlllllVuUeVyllllltq7@nyllllwlllll9llll5@@@@@@@@@@; LSTMV=201%2C260; LCLKINT=27637; sw_uuid=3851573336; sg_uuid=3001557157; ssuid=8893341825; dt_ssuid=7044358220; usid=XUhtela4MuqO4WYt; pgv_si=s423112704; JSESSIONID=aaaJ940C2hKSEd-V85U3v; sct=24; ppinf=5|1503111208|1504320808|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo3Omluc2lnaHR8Y3J0OjEwOjE1MDMxMTEyMDh8cmVmbmljazo3Omluc2lnaHR8dXNlcmlkOjQ0Om85dDJsdU1zWmxsOWVLRTNwb0M5TTMwLXFVSU1Ad2VpeGluLnNvaHUuY29tfA; pprdig=r6cB7eM-w6v2tvRQ42QrnnZYg1bhefjDUAxJ3pkm2ZzalCVcFlv74Mx4Ubz7E8NroDnQ1oTPxNJkYeBCkI8yqM9VNk7bHeTyMqT8wWjMz6rgh2dzXUE7wb1LGbInPhNUN_A1dTW0QoyV4ZNWaEgik3hYqi1EQwUaVoHAmy-pHLc; sgid=08-30426875-AVmXqCiaDYuwr4vkbBuwLlw0; ppmdig=1503121994000000ef911d3ebbde56dd937521fdd5448948", "Host": "weixin.sogou.com", 'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3226.400 QQBrowser/9.6.11681.400'}
proxy = None
keyword='风景'proxy_pool_url='http://127.0.0.1.5000/get'#这是获取的代理,呈现在本地客户端上proxy=None #一开始的时候是使用本机,不使用代理。并且设置为全局变量max_count=5 #防止发生死循环,在获取代理失败时,最多递归五次获取代理def get_proxy(): try:
response = requests.get(proxy_pool_url) if response.status_code == 200: return response.text return None
except ConnectionError: return None
def get_html(url, count=1): print('Crawling', url) print('Trying Count', count) global proxy if count >=max_count : print('Tried Too Many Counts') return None try: if proxy:
proxies = { 'http': 'http://' + proxy
}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies) else:
response = requests.get(url, allow_redirects=False, headers=headers) if response.status_code == 200: return response.text if response.status_code == 302: # Need Proxy
print('302')
proxy = get_proxy() if proxy: print('Using Proxy', proxy) return get_html(url) else: print('Get Proxy Failed') return None
except ConnectionError as e: print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)
def get_index(keyword, page):
data = { 'query': keyword, 'type': 2, 'page': page
}
queries = urlencode(data)
url = base_url + queries
html = get_html(url) return html
def main(): for page in range(1, 101):
html = get_index(keyword, page) print (html)if __name__ == '__main__':
main()
输出的部分结果
Crawling http://weixin.sogou.com/weixin?query=%E9%A3%8E%E6%99%AF&type=2&page=1Trying Count 1302Get Proxy Failed
None
Crawling http://weixin.sogou.com/weixin?query=%E9%A3%8E%E6%99%AF&type=2&page=2Trying Count 1302Get Proxy Failed
None
Crawling http://weixin.sogou.com/weixin?query=%E9%A3%8E%E6%99%AF&type=2&page=3Trying Count 1302Get Proxy Failed
None由于使用的是免费代理,可能会有很多人同时使用,就会出现代理不可用的的现象。
设置代理时注意:
先到此网址(https://github.com/germey/proxypool)下载维护一个代理池所需要的文件,并有具体的安装教程
把文件放入Pycharm中,Terminal 上运行run.py

Pycharm截图
在Terminal 上可以同时spider.py 和run.py ,但要注意的是要切换到所在文件下。
在Redis 的可视化工具Redis Desktop Manager 会显示如下图
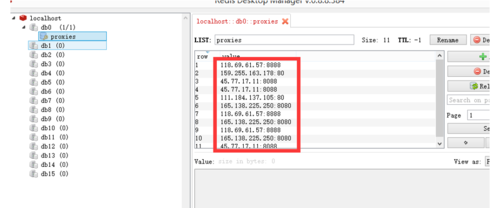
Redis Desktop Manager
在自己的浏览器上输入http://127.0.0.1.5000/get 得到如下的结果
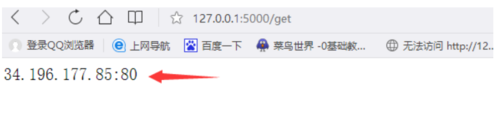
Paste_Image.png
获取详情页内容并存储数据
完整代码
config2.py
PROXY_POOL_URL = 'http://127.0.0.1:5000/get'KEYWORD = '风景'MONGO_URI = 'localhost'MONGO_DB = 'weixin'MAX_COUNT = 5#spider.pyfrom urllib.parse import urlencode
import pymongo
import requests
from lxml.etree import XMLSyntaxError
from requests.exceptions import ConnectionError
from pyquery import PyQuery as pq
from config2 import *
client = pymongo.MongoClient(MONGO_URI) #创建连接db = client[MONGO_DB]#数据库命名base_url = 'http://weixin.sogou.com/weixin?'headers={ "Cookie":"pgv_pvi=359512064; RK=TJdr85TKbn; noticeLoginFlag=0; cuid=9815965235; pgv_pvid=8398084628; o_cookie=893579569; ptui_loginuin=893579569; ptcz=8a66bc651eed7aa9d76cf6979edcfd818243e424466422c2b05b114da47da360; pt2gguin=o0893579569", "Host": "weixin.sogou.com", 'Upgrade-Insecure-Requests':'1', 'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.3226.400 QQBrowser/9.6.11681.400'} #这里的Cookies 会存在超时现象,可以时常更换。proxy=None #一开始的时候是使用本机,不使用代理。并且设置为全局变量#下面的几个变量写到了配置文件,之所以没有删除,参考使用#keyword='风景'#proxy_pool_url='http://127.0.0.1.5000/get'#这是获取的代理,呈现在本地客户端上#max_count=5 #防止发生死循环,在获取代理失败时,最多递归五次获取代理def get_proxy(): try:
response = requests.get(PROXY_POOL_URL) if response.status_code == 200: return response.text return None
except ConnectionError:
return Nonedef get_html(url, count=1):
print('Crawling', url)
print('Trying Count', count)
global proxy if count >=MAX_COUNT :
print('Tried Too Many Counts') return None try:
if proxy:
proxies = { 'http': 'http://' + proxy
}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies) else:
response = requests.get(url, allow_redirects=False, headers=headers) if response.status_code == 200: return response.text if response.status_code == 302: # Need Proxy
print('302')
proxy = get_proxy() if proxy:
print('Using Proxy', proxy) return get_html(url) else:
print('Get Proxy Failed') return None
except ConnectionError as e:
print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)def get_index(keyword, page):
data = { 'query': keyword, 'type': 2, 'page': page
}
queries = urlencode(data) ##把key-value这样的键值对转换格式,返回a=1&b=1这样的字符串
url = base_url + queries
html = get_html(url) return htmldef parse_index(html): #解析索引页
doc=pq(html)
items=doc('.new-box .new-list li .txt-box h3 a').items() for item in items:
yield item.attr('href')def get_detail(url): #获得详情页
try:
response=requests.get(url) if response.status_code==200: return response.text return None
except ConnectionError:
return Nonedef parse_detail(html): try:
doc=pq(html)
title=doc('.rich_media_title').text()
content=doc('.rich_media_content').text()
date=doc('#post-date').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat=doc('#js_profile_qrcode > div > p:nth-child(3)').text() return { 'title':title, 'content':content, 'date':date, 'nickname':nickname, 'wechat':wechat
}
except XMLSyntaxError: #pyquery 解析的出现了一个自符的错误,在这里捕捉下并返回为None
return Nonedef save_to_mongo(data): if db['articles'].update({'title': data['title']}, {'$set': data}, True): #{'title': data['title']}表示查询的范围;{'$set': data}表示要更新的内容;True的作用,如果查询到结果就更新,如果没查到结果就插入
print('Saved to Mongo', data['title']) else:
print('Saved to Mongo Failed', data['title'])def main(): for page in range(1, 101):
html = get_index(KEYWORD, page) if html:
article_urls=parse_index(html) for article_url in article_urls:
article_html=get_detail(article_url) if article_html:
article_datas=parse_detail(article_urls)
print (article_datas)if __name__ == '__main__':
main()
输出的部分结果
Crawling http://weixin.sogou.com/weixin?query=%E9%A3%8E%E6%99%AF&type=2&page=19Trying Count 1302Using Proxy 104.219.177.221:8080Crawling http://weixin.sogou.com/weixin?query=%E9%A3%8E%E6%99%AF&type=2&page=19Trying Count 1302Using Proxy 172.8.207.192:3128Crawling http://weixin.sogou.com/weixin?query=%E9%A3%8E%E6%99%AF&type=2&page=19Trying Count 1Redis安装
RedisDesktopManager安装
(选择0.8.8版本,下载exe文件即可)
作者:凡人求索
链接:https://www.jianshu.com/p/a3de396efc31
共同学习,写下你的评论
评论加载中...
作者其他优质文章



