
这个爬虫写得好累,就简单讲一下思路吧。雪球网股票的评论内容是不能直接访问的,必须要携带在第一次访问时雪球网写进本地的cookie(其实你随便打开一次官网就是属于第一次访问了,那时候 不需要cookie),先放上github地址:
https://github.com/xiaobeibei26/xueiqiu_spider
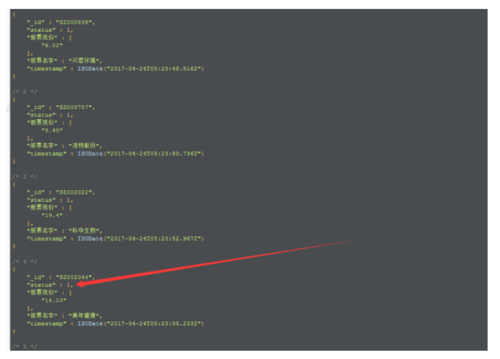
爬取思路是这样的,先挖取所有股票的代码,放进数据库,然后根据股票代码爬取每一只股票的评论,多了,一定要加入代理池,我这里用的上上一篇文章写的代理池,我们给每个股票代码赋予一个状态值,一开始是outstanding,也就是1.如图
Paste_Image.png
每个进程需要知道那些股票评论爬取过了、哪些股票需要爬取!我们来给每个URL设置三种状态:
outstanding:等待爬取的股票
complete:爬取完成的股票
processing:正在进行的股票,也可能是失败的爬取股票
嗯!当一个所有初始的股票状态都为outstanding;当开始爬取的时候状态改为:processing;爬取完成状态改为:complete;失败的股票重置状态为:outstanding。为了能够处理股票进程被终止的情况、我们设置一个计时参数,当超过这个值时;我们则将状态重置为outstanding。
股票代码的爬取很简单,直接访问主页就好了
Paste_Image.png
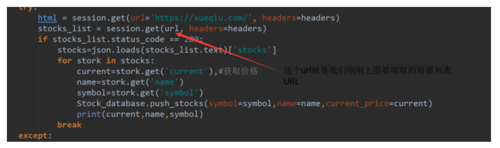
代码上比较简单,如图是其中一段
Paste_Image.png
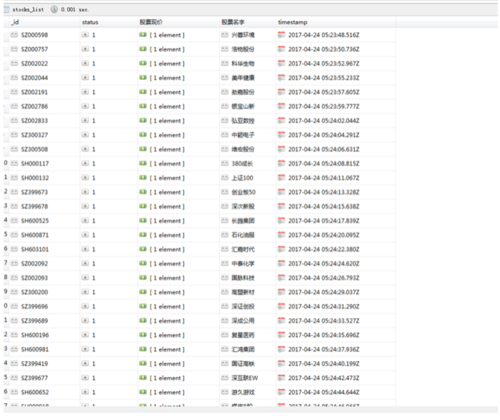
爬取之后我们看看数据库
Paste_Image.png
这里5000来只股票
接下来看看股票评论的ajax请求
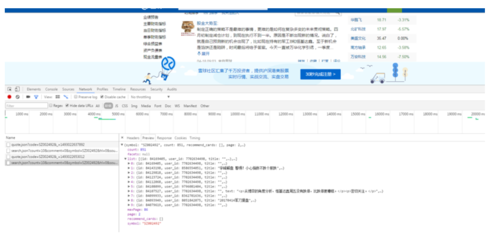
随便点开一只股票,然后点击里面的讨论就会触发该请求,评论时个json数据,解析之后直接提取就好了,这里简单说说URL里面的参数
如图
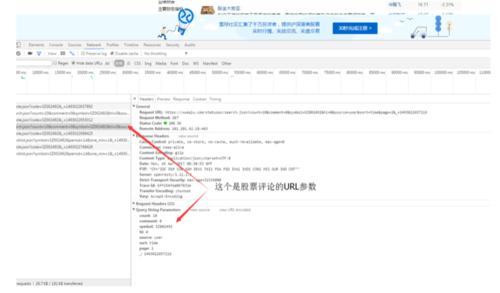
Paste_Image.png
这里count很好理解,是每页的评论数,访问的时候要加上,hl:0、source:user和comment:0这三个参数是一直不变的,加上就好,symbol是股票代码,访问时候必须要加上,page是评论的页数,重点需要提一提的是里面最下面那个参数,-:1493022641602,一开始看到这个我是有点懵逼的,在源代码里面各种找,确保不是在里面提取的之后,我看着这东西也是越来越眼熟,然后在Python里面试了一试,果不其然,如图
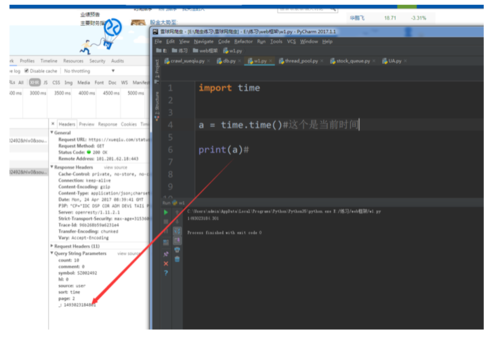
Paste_Image.png
我们再处理一下
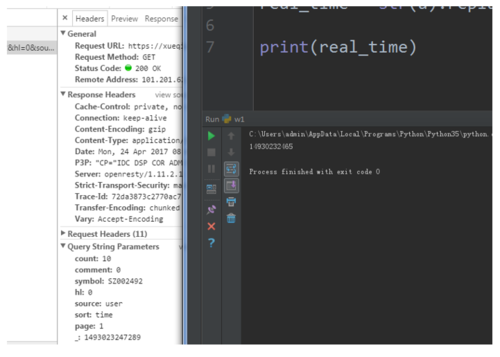
相差的就是最后的微秒,我心中有底之后就去翻源代码里面的JS代码,果不其然,就是利用JS生成的当前访问时间,虽然我试过不加时间也能访问,但为了保险,我还是加上了,不精要大规模访问,下面是主程序,代码很长,你们不用看,我自己当笔记
import requestsfrom spider.UA import agentsimport randomimport timeimport jsonfrom spider.stock_queue import StockMongofrom lxml import htmlimport multiprocessingfrom spider.thread_pool import ThreadPool#自己写的线程池headers={'User-Agent':random.choice(agents)
}
xueqiu_url='https://xueqiu.com/'#雪球官网comment_url= 'https://xueqiu.com/statuses/search.json?count=10&comment=0&symbol={symbol}&hl=0&source=user&sort=time&page={page}&_={real_time}'def get_comment():#默认是不使用dialing
Stock_database = StockMongo('xueqiu', 'stocks_list')#链接第一步抓取的股票代码数据表,根据股票代码抓取评论
# symbol = Stock_database.pop() # 获取股票代码
comment_database=StockMongo('xueqiu','comment_list')#评论要放进的数据库
a = time.time()
real_time = str(a).replace('.', '')[0:-1]#获取当前时间
def thread_get_comment(num):
while True:
session = requests.session()
proxy = requests.get('http://localhost:5000/get').text # 获取本地代理池代理
if proxy:
proxies = {'http': 'http://{}'.format(proxy), 'https': 'http://{}'.format(proxy), }
session.proxies = proxies # 携带代理
try:
url = comment_url.format(symbol=symbol, page=str(num[0]), real_time=real_time) # 股票列表URL
# print(url)
'''利用线程池传进去的num是个元组,必须提取出来'''
First_request = session.get(url='https://xueqiu.com/', headers=headers, timeout=10)
comments_list = session.get(url, headers=headers, timeout=10) if Stock_database.check_status(symbol):#如果已经爬取完成,直接结束循环
break
if str(comments_list.status_code) == str(200):#是否正常返回数据
stocks_comment = json.loads(comments_list.text)['list']
page = json.loads(comments_list.text)['maxPage']#获取最大页数
# print(page,num[0])
for stork in stocks_comment: try:
text = stork.get('text').strip()
selector = html.fromstring(text) # 里面的标签各种各样,各种嵌套,用正则调了很久,投降了,改用xpath
comment = selector.xpath('string(.)')
user_id = stork.get('user_id') # 评论者ID
user = stork.get('user') # 评论者信息
title = stork.get('title') # 标题
stock_code = symbol # 股票代码
comment_id = stork.get('id') # 每条评论都要唯一的ID
comment_database.push_stock_comment(comment_id=comment_id,symbol=stock_code,comment=comment, user_id=user_id,
user=user,title=title)
print('正在爬取第',num[0],'该股票一共',page) if str(page) == str(num[0]):#抓取到了最后一页
print(symbol,'该股票抓取成功')
Stock_database.complete(symbol=symbol) break
break
except: pass
break
except Exception as e: # print('获取失败,准备重新获取') # 失败后再来
time.sleep(10) continue
else:
time.sleep(15) # 等待重新获取代理
continue
def comment_crawler():
pool=ThreadPool(6) for num in range(1,101):#遍历一到100页
pool.run(func=thread_get_comment,args=(num,)) while Stock_database: try:
symbol = Stock_database.pop()
comment_crawler()
time.sleep(2) except KeyError:#队列没有数据了
print('队列没有数据') breakdef process_crawler():
process=[]
num_cups=multiprocessing.cpu_count()
print('将会启动的进程数为',num_cups) for i in range(int(num_cups)-2):
p=multiprocessing.Process(target=get_comment)#创建进程
p.start()
process.append(p) for p in process:
p.join()if __name__ == '__main__':
process_crawler()晚上开电脑跑了一个通宵,还以为自己的高性能电脑很吊,结果也只是跑了30万条数据,上两张结果图

Paste_Image.png
作者:蜗牛仔
链接:https://www.jianshu.com/p/4e63900306bf
共同学习,写下你的评论
评论加载中...
作者其他优质文章



