
读过前面一篇文章《系统架构升级之道,关注关键服务依赖》就知道,我们的应用系统中的关键服务绝大部分都会是对数据库的依赖。
如果只有一个数据库服务器,数据一致性问题也就不存在了。
可是,随着系统访问量、数据量的不断增长,数据库出现多个服务器,又出现缓存服务,又要拆分数据库,还要分拆到不同的子应用等等。
这样一来,数据一致性问题就会变得越来越突出。
这次,咱们就来分析下这个问题会涉及到哪些方面,严重程度,以及如何应对。

我们来看这样一个数据流程。
1 用户提交一个订单(2个不同商家各一件商品)——数据源头
2 应用服务器验证用户信息、订单信息、库存信息等等,然后将这个订单发送到订单消息队列——消息队列
3 订单处理服务器从消息队列中拿到新订单,接下来的处理,可能做的数据操作有:
3.1 生成一个订单/也可能会分拆为两个订单
3.2 更新两个商品库存数量
3.3 更新商家的销售数据
3.4 生成订单对应的支付信息
3.5 生成用户订单成功的状态信息
上面的数据处理中,涉及到的数据有:订单数据、商品数据、商家数据、支付数据、用户数据。
涉及到的应用和服务有:前端应用系统,消息队列,后端应用系统,数据库,缓存,甚至订单、商品、商家、支付、用户可能都是独立的子应用。
可能大部分系统不会像上面这么庞大。
如果前后端都是一起的,也就没有消息队列。
如果也没有这些子系统,数据库是集中的,那可能数据一致性问题会稍微小些。
这时候,只需要注意数据库更新的一致性就好了,比较容易想到的应对方法,就是用数据库事务来保证。
如果这些数据不只是一份数据库,还有缓存中一份,又要考虑缓存数据的更新,所以问题还是复杂了。
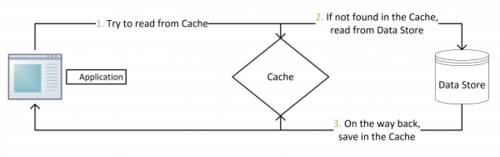
数据库更新,怎么保证缓存也能正常更新呢?
1 程序中处理,数据库更新后,就要马上更新缓存数据
2 如果缓存更新失败或者程序出现异常,要有异常处理方法
3 异常处理方法可以是程序中实时的纠正或者重试
4 异常处理方法也可以是针对数据库的更新,二次检查缓存数据的更新
这里还只是一个数据库和一个缓存的情况,已经要做出这么多事情。
那这些工作带来的影响有哪些呢?
1 程序开发更加复杂,不能有些许的遗漏
2 数据验证和重试带来的性能下降
3 数据库事务带来的数据库瓶颈明显
4 二次检查再次增加复杂度和额外开销

本来一个订单处理,如果不考虑数据一致性问题,数据库写入/更新5~10次,缓存写入/更新5~10次,整个过程应该在10ms内完成。
但是加上数据库事务之后,会把这些操作中涉及到的几个表都加锁,意味着数据的读、写都串行化了,整个应用系统的并发能力急剧下降。
当然,因为这里引入缓存,对数据库的依赖会减少很多,而且还有从库可以提供读的服务,应用系统的访问并发能力不至于下降太多。
但这些代价在交易处理中是难以避免的,为了解决数据一致性问题,牺牲的是订单处理的并发能力。
对于大部分商城、网站,订单并发量也不高,这类问题不太常发生,所以也就这么过去了。
但是在一些促销活动的时候,肯定还是会遇到下单等待太久的问题。
为了具备更大并发的订单处理能力,单数据库、缓存肯定是行不通了。
那么要在这么多的子应用、大量的数据库、缓存服务中保持数据一致性又要怎么做呢?
1 每个子应用都要支持分布式事务,共同保证数据库全部成功更新
2 每个子应用各自要保证自己的数据更新一致性(异常处理、重试、二次检查等方法同上)
上面看上去只有两条,但是要做的事情和困难会比上面要多十倍,难百倍。
看到这里,是不是对于数据一致性的问题都有点绝望了。
正因如此,大部分的分布式系统,大部分应用,是没有做到数据一致性,哪怕是弱一致性。
比如:论坛里面发帖,要更新10份左右的数据,出现脏数据是常有的,这就是没有做到数据一致性。
比如:商城里面库存超卖,订单状态不一致等,也是因为没有做到数据一致性。
之所以会这样,因为投入产出严重不成比例,是很无奈的选择。
数据不一致的情况毕竟比例极低,但是投入的代价却极大。
数据不一致引发的后果,可以忍受和容忍,哪怕是发现后再修正。
那么,还有什么办法可以避免或减少出现数据一致性问题呢?
下面有几个方法可以考虑:
1 将系统规模和容量降低,保证系统的稳定性和高效;
一个每秒钟上百万请求的应用系统能不能分拆为1000个每秒钟1000请求的独立集群呢?
一个上百万的商家、商品、订单库,能不能分拆为1000个只有1000个商家、商品、订单的子库呢?
2 将数据关联降低,减少更新次数,减少不一致问题的出现概率;
上面的订单、库存、商家、支付、用户几个数据,核心数据只有订单,其他的几个数据完全可以从订单数据推导出来,减少订单处理中的一致性要求。
3 将应用分拆,对性能和一致性要求高的应用独立实现;
减少业务耦合,集中资源重点投入。

解决数据一致性问题,现在还没有太好的方案,即经济实惠,又效果显著的方案,希望有大神可以造出来吧。
在实战课程 《PHP秒杀系统 高并发高性能的极致挑战》中,也是针对这类高并发的业务场景做了特定的性能优化以及分布式方案,大家可以参考学习。
共同学习,写下你的评论
评论加载中...
作者其他优质文章


