

一、分布式的两大场景
数据存储的分布式
服务的分布式
二、数据存储的分布式
比如海量数据,单机存储不下,需要多机,以集群的方式存储,即为数据的分布式存储,数据存储的分布式一般涉及如下几个方面
数据的分片策略
全局主键的实现机制
跨结点数据的聚合
分布式事务
数据容灾机制
2.1数据分片策略
2.1.1 基于数据范围来分
比如库1,存放id 1到1000w的数据,库2存放id 1000w到2000w的数据
优点 :
单库数据规模提前预估。超规模后,加机器,不需要迁移数据。
且相邻数据大都存放在一个库上,查询时,可以减少跨库聚合。
缺点
容易出现热点数据,比如项目初期,只有库1被高频率访问
待解决问题 :业务变更导致部分数据被删除后,如何做到数据容量的在平衡。一般也不用考虑这个问题。空间不值钱。
2.1.2 基于id hash来分
优点 :hash分配,数据分布均匀不会出现数据热点问题
缺点
数据的查询聚合可能需要频繁跨库。解决办法:hash算法和用于计算hash的key去保证,将业务关心的数据分片到同一库,甚至同一张表
集群扩容时,会导致重新hash。可能面临部分数据的迁移
2.1.3 怎么解决扩容时,数据重新hash的问题
方法来至于58沈剑。主要思想:分布式存储的每个库,出于数据可用性的考虑,设置一个主从库,这使得一份数据,有两份存储。扩容时,将每个从库,变成主库。于是容量就扩容了一倍,修改后的hash算法,依然能正确路由。同时由于新的主库包含了完整的数据,所以不需要做数据迁移,只需要做冗余数据的清理。图例如下:
扩容之前的状态
扩容,将从变主。%2=0的库,会变为%4=0与%4=2 。%2=1的部分,会变为%4=1与%4=3;
对扩容后的所有主数据库,新增从库,方便下次的翻倍扩容。删除冗余数据
2.2全局主键的实现机制
snowflake
2.3跨结点数据的聚合
对于跨节点聚合有两种思路,一是通过现有数据库,从查询算法上考虑。第二种,对于过于复杂的聚合统计查询,使用外置索引来实现,比如elasticsearch
第一种,几种跨库分页的方式
http://www.10tiao.com/html/249/201702/2651959942/1.html
第二种,索引外置,比如使用elasticsearch。参看elasticsearch 原理
三、服务的分布式
服务的分布式,一般涉及如下几个方面
服务注册
服务发现
负载均衡
分布式事务
服务的降级熔断
3.1服务的注册
3.2服务的发现
3.3负载均衡
以上三点的大概模式,可以参看之前的笔记微服务的注册与发现 https://chen-jun.me/wei-fu-wu-de-zhu-ce-yu-fa-xian/
3.4分布式事务
3.5服务的降级熔断
服务的降级熔断,可以在两方面做文章。比如A服务调用B服务。当B服务处理失败,导致A服务故障时。在A端,可以设置熔断,当故障率达到一定,A服务可以有一个默认值,不在调用B服务。B服务本身,也可以在A调用自己出故障时,不走计算流程,直接返回一个默认值。这方面的框架有Spring Cloud Hystrix
Spring Cloud Hystrix是基于Netflix的开源框架Hystrix实现,该框架实现了服务熔断、线程隔离等一系列服务保护功能。
对于熔断机制的实现,Hystrix设计了三种状态:
1.熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制。
2.熔断开启状态(Open)
在固定时间窗口内(Hystrix默认是10秒),接口调用出错比率达到一个阈值(Hystrix默认为50%),会进入熔断开启状态。进入熔断状态后,后续对该服务接口的调用不再经过网络,直接执行本地的fallback方法。
3.半熔断状态(Half-Open)
在进入熔断开启状态一段时间之后(Hystrix默认是5秒),熔断器会进入半熔断状态。所谓半熔断就是尝试恢复服务调用,允许有限的流量调用该服务,并监控调用成功率。如果成功率达到预期,则说明服务已恢复,进入熔断关闭状态;如果成功率仍旧很低,则重新进入熔断关闭状态。
关系转换图如下
四、 分布式事务
4.1 CAP理论
CAP理论是 Eric Brewer提出的一种分布式状况下,面临的三个无法同时兼顾的问题
Consistency所有分布式节点,对同一份数据,拥有相同的副本。不会出现数据不一致的情况
Availability对数据的更新和读写,具有高可用性。即服务不能无响应,或出错
Partition Tolerance分区的容忍性,这里的分区不是指数据分布式存储中的shard分区。而是指,由于诸如网络等原因,导致分布式节点之间,无法正常同性时,导致的结点隔离,成为分区。在分区时,整个系统还能允许多大程度的对外服务,成为分区容忍性。
假设一个分布式系统中,有两个节点,处于分区状态。若允许分区中节点可以更新数据,那么会丧失一致性 C 。如果要保证一致性 C ,那处于分区状态的节点将不允许提供服务,这又会丧失可用性 A 。如果一定要保证 CA ,必须保证节点之间能够互相通信,那分区就不能容忍,就无从谈起分区容忍性 P
Eric Brewer提出,在分布式环境下,一个系统只能同时满足以上两点特性,而无法同时满足所有特性。在大多数的分布式系统设计中,人们多会选择满足 AP 两点特性。而放弃强一致性,转而追求最终一致性。这种选择还有另外一个描述叫: B asically A vailable, S oft-state, E ventually consistent 简称 BASE
以上CAP理论的简洁抽象,容易让人们大概理解分布式系统中的难处,但也容易产生一些误导。那就是CAP中的3选2,并不是绝对的。所有Eric Brewer后来又做了一次澄清解释。为什么有误导?
1、很多时候,如果我们不能保证P,那CA也无从谈起
比如用户是通过html访问服务的,这个服务对应的节点,出现分区,导致html都无法访问时。那CA 就不用提了。只有在html能在客户端缓存,支持用户离线模式,才可以说系统保证了 P ,同时保证了 A
2、保证AP,并不是完全放弃C,当恢复分区时,我们依然要采取各种方式解决分区导致的不一致。
由于网络延迟,或网络断连,甚至一个写请求,同步至所有节点,由于节点跨机房,写完成的时间不同步,都可能导致分区。只是分区的时间长短不一而已。为了解决最终的一致性,这就涉及到分布式事务。对于分布式数据库中,某个值的写,保证其一致性,可以使用paxos,raft协议算法。对于业务类型的事务。可以使用TCC或者消息通知的模式来进行事务管理
4.2 最终一致性方案——paxos,raft
zookeeper就是使用的paxos协议
4.3最终一致性方案——TCC
分为 T ry , C onfirm, C ancel ,简称TCC。
Try:尝试锁定事务涉及的资源,进行资源预留
Confirm:对预留的资源做确认提交
Cancel:如果confirm失败,则进行补偿操作,回滚业务处理,解锁预留资源
可以看到这种,try , confrm/cancel。也是两阶段。那跟传统JAT支持的两阶段事务有什么区别?
JTA支持的传统两阶段事务,需要涉及的资源支持XA协议标准,但TCC则需要遵循什么工业标准,可以是完全的业务实现。传统的两阶段提交,任然要求满足事务的ACID,这导致资源的可用性很差。
传统两阶段提交的特点:
TCC事务的特点:
4.4 最终一致性方案——消息通知
这类事务的特点是,需要借助消息通知,来使得事务涉及的多个分布式服务能够协调,完成业务期望。这种方式,也有几种细分的设计。
4.4.1 使用本地事务
同一个共用的消息表,来协调服务双方的业务执行状况
4.4.2 使用MQ
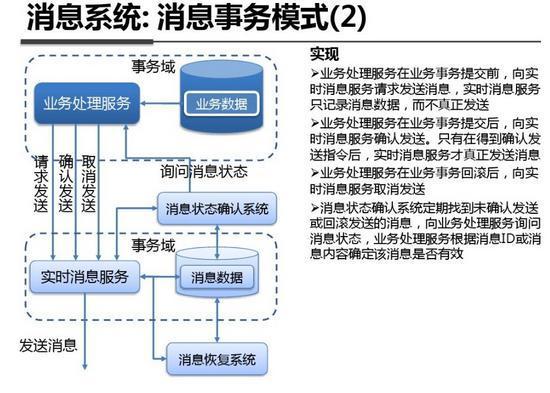
4.4.3 另外一种使用MQ的方式
作者:伊竹凌
链接:https://www.jianshu.com/p/b244456677f2
共同学习,写下你的评论
评论加载中...
作者其他优质文章


