
关键词:
MCP、A2A、ADK、Manus、DeepSeek、Computer Use、LangGraph
语言模型中的路径示意图如图7-8所示。在训练大语言模型时,大家希望对大语言模型进行微调,使选择的下一个标记能够最大化所获得的奖励。
对于语言模型而言,路径是一系列提示词(状态)及对应的下一个标记(行动)。
当使用语言模型为一个问题生成回答,或者根据提示词生成文本时,大家可以看到一系列的状态和行动,这些内容定义了一条路径。例如,输入问题Where is Shanghai? 作为初始状态s_0,语言模型对于这个问题生成第一个标记Shanghai,这可以作为一个行动 a_0。然后,Shanghai加入上下文,成为新的状态s_1,生成的标记is作为行动 a_1。依此类推, is加入状态s_2 ,in是行动 a_2 ;in加入状态s_3 ,China为行动a_3。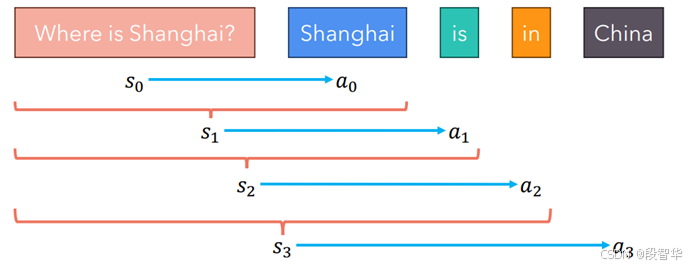
图7-8 语言模型中的路径
整个模型的路径是一个不断自回归的过程,s_1在(s_0,a_0)的基础上形成,s_3是在(s_2,a_2)的基础上形成,这天然地和强化学习契合。强化学习不断与环境进行交互,环境是当前的计算机或用户,然后调整下一个输出。
随着模型本身能力的增强,尤其是DeepSeek-R1,人们惊奇地发现模型可以有逻辑地表达信息,把一种混乱的几乎难以驾驭的(intractable)的状态,变成能够驾驭(tractable)的状态。这是DeepSeek-R1面临的重大时代机遇,极大程度的成功也有幸运的成分。它之所以能够成功,不仅因为它做了强化学习,更因为DeepSeek-V3基座模型很强大,能够把一种混乱的环境或现实世界,以比较一致(consistently)的方式来表达。如果强化学习时面临混乱及不一致,就无法实现强化学习。而DeepSeek-V3是一个强大的基础模型,能把这个混乱的信息世界以一致的方式表达出来,减少或屏蔽掉了混乱度。DeepSeek-V3相当于一个代理,把现实世界和DeepSeek-R1之间进行了一个转换,让DeepSeek-R1不直接面对混乱的现实世界,所以DeepSeek-R1的强化学习就能够有效。
有了这样一条路径,大家要去计算它,因为要更新策略或代理,也就是当前的DeepSeek网络或其他网络。优化时会涉及一个梯度的问题,梯度是当前处于一个点,要达到目标时有几个不同的方向,要选择一条能够最快到达目标的路径,同时要尽量避免局部最优点,因为这样永远到达不了目标,这都是深度学习的一些基础内容。
在实现的过程中有很多技术,其实最根本的是采样技术。因为一个神经网络面临的问题域或者行动空间,这是大家能够操作的空间,比如操作一个浏览器,点击回退按钮、填一个表单、或者提交按钮等,这些都是具体的行动。从神经网络的角度,理论上行动空间无限大,数据分布有很多种,这时需要进行很好地抽样。无论深度学习还是强化学习,这都是一个很大的挑战。在某种程度上,概率统计比线性代数和微积分更重要。从强化学习或机器学习的角度,DeepSeek的成功从概率分布的角度讲,它知道哪些更重要或者使用另外一种方式来表达同样的效果,例如GRPO算法表达了某个元素在同一群组中相对其它元素更优的关系。这确实是很强的内容。
假设有一个由θ参数化的策略π_θ,希望改变这个策略的参数,在使用策略时最大化期望回报,最大化以下公式: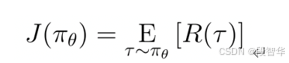
当使用深度神经网络时,目标是迭代改变网络的参数,从而最小化损失函数,这是随机
梯度下降的方式。这里大家想要最大化一个函数,可以使用随机梯度上升: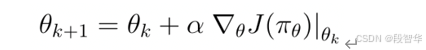
策略的梯度被称为策略梯度,使用这种方式优化策略的方法被称为策略梯度算法。不过有一个问题,为了计算梯度,大家需要在所有可能的路径上进行探索,除非状态空间非常小,否则在计算上是比较难以处理的。策略梯度算法其实是一个已经解决掉的问题,这里有两个层面,一是Pytorch之类的框架或者平台,都有自动化的工具帮大家完成。二是基于大模型的强化学习方法,基本上考虑了各种不同场景,大家有直接的算法和工具可以去使用。虽然在最开始时看来,它是不可处理的,是一件无法完成的事情,对于一个智能体或者大模型,总能够用数学精准地找出最优路径或最优解,这个问题没解决,如果能解决这个问题,会没有悬念或没有争议地获得图灵奖或诺贝尔奖。但是从一个开发者或者做一个产品的角度讲,在当前点选择更佳的路径,这个默认已经解决,因为工具已经足够多、足够成熟,尤其是DeepSeek带来的工具或库。
策略梯度优化示意图如图7-9所示。这里面的一些基本内容不再赘述,这都是高二、高三的学习内容。在分享源码时,大家还会再次学习这些内容。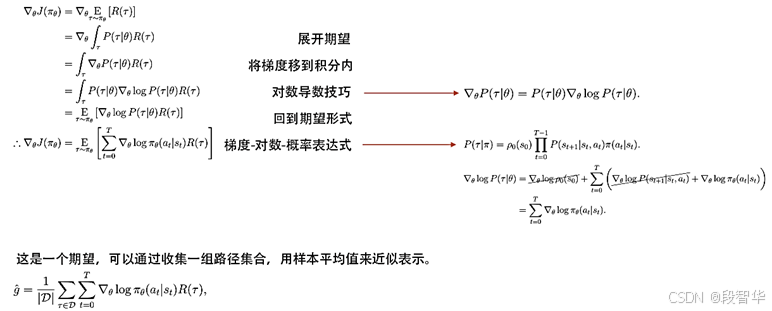
图7-9 策略梯度优化
基于Transformer层的策略梯度计算示意图如图7-10所示,展示了基于 Transformer 层策略的计算流程:
① 从强化学习的视角,大模型本身也叫策略(Policy),根据输入的信息,由策略来生成一系列的标记内容,能够同时代表前面的信息,因果模型(Causal model)大家应该很清楚。
② 有了这个信息之后,可以基于一个线性投影层(Linear Projection)获得一个logits值,可以简单地把它想象成价值函数(Value Function)或者奖励值(Reward)。从Transformer的角度,可以看最后一个标记(Logits 08)的奖励值。
③ 使用Softmax操作产生概率分布,可以把所有的奖励值放在一个[0,1]的范围之内,从而选出想要的概率。
④ 在解码时有很多策略或算法,这是生成下一个标记的概率。选择哪一个标记是一个核心问题。这个过程会有很多采样的策略,之所以复杂是因为代表了无数种数据的可能性。在实际做强化学习时,会围绕采样技术做很多工作。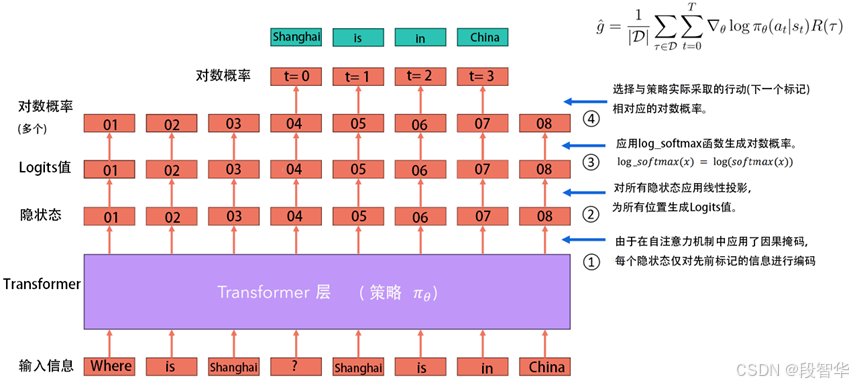
图7-10 基于 Transformer 层的策略梯度计算
在DeepSeek之前,如果不是从DeepSeek或成熟大模型的角度,大家学习强化学习是一件极为艰难的事情。现在有了DeepSeek,使用MIT开源开放的协议,大家可以任意修改DeepSeek的代码及模型,做商业级别的使用,这对于全世界而言是一件很大的事情。基于DeepSeek的开源模型及协议,能够把业务规则、评价系统和数据融入其中,这非常有价值。
在探索大模型智能体的过程中,如需进一步交流或获取更多信息,可通过以下方式联系:
微信交流:NLP_Matrix_Space 或 NLP_ChatGPT_LLM
电话沟通:+1 650-603-1290
邮件咨询:hiheartfirst@gmail.com
期待与您共同探讨大模型智能体领域的知识,分享见解,共同成长。
本文由博客一文多发平台 OpenWrite 发布!
共同学习,写下你的评论
评论加载中...
作者其他优质文章


