
什么是数据挖掘
数据挖掘(Data Mining)又称为:数据中的知识发现(KDD),也就是通过数据清理,数据集成,数据选择,数据变换,数据挖掘,模式评估,知识表示等一系列步骤,对数据进行分类,聚类,发现其中的关系或者离群点,来发现新的知识,新的价值。
(一)数据类型
1)数据库数据
数据库系统,又称为数据库管理系统(DBMS),一种关系型数据库。有唯一的关键字标识来表示一个对象,每个对象有若干属性,又包括若干元组。
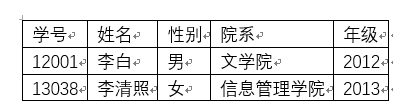
一个二维表
2)数据仓库数据
多个数据库数据加上不同的维度,组成了数据仓库。
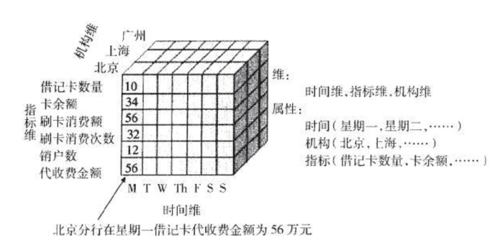
数据库立方体
3)数据库的事务
事务数据库中的每个记录都是一次事务,例如一次商品订单
4)其他数据
前1,2,3点都是结构化数据,还包含非结构化数据,例如音频,超文本,地图等
(二)数据挖掘的步骤
1)数据清理:消除噪声数据
2)数据集成:多种数据组合在一起
3)数据选择:选择相关数据
4)数据变换:汇总等操作将数据变换成适合挖掘的数据
5)数据挖掘:对数据进行
6)模式评估:根据某种模式来评估某种价值
7)知识表示:可视化表现
(三)数据挖掘模式
1)类和概念:特征化与区分
对数据汇总和分类,考察其具有什么样的特征
2)挖掘频繁模式:关联和相关性
1 频繁出现的序列;
2 出现次数最多的事件;
3 频繁出现的子序列;
4 事件之间的关联性;
3)预测分析的分类和回归
1 分类:决策树 、神经网络
2 回归:相关性描述和预测、描述解释变量与被解释变量之间的相关性,并构造数学模型来预测被解释变量
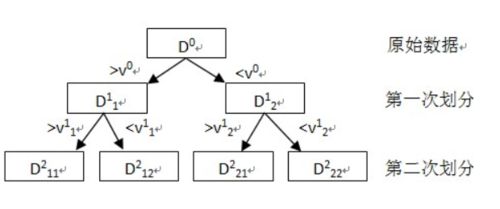
决策树分类
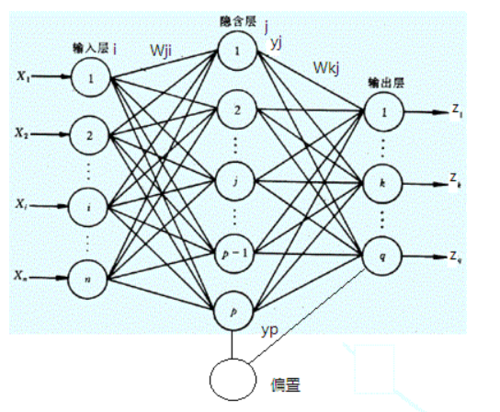
神经网络分类
4)聚类
根据最大化类内相似,最小化类间相似性的原则进行聚类和分组
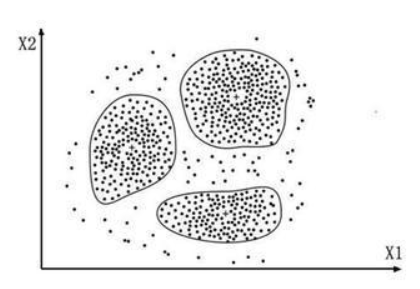
聚类
5)离群点
异常的值,有的时候需要抛弃异常值,但有时通过异常值可以发现问题,如欺诈行为
(四)数据挖掘相关内容
1)统计学
1 数值描述(如均值、中位数、众数、方差,柱状图、散点图等),
2 回归分析(线性回归、非线性回归、一元回归、多元回归),
3 离散型和连续性数据的概率分布、描述性统计和推断性统计
2)机器学习
用数据对机器不断训练以来提高机器性能,类似条件反射
3)数据库和数据仓库
对数据的管理,其包含的海量数据可以用来做OLTP,OLAP(这两个暂时不知道)
4)信息检索
作者:徐代龙
链接:https://www.jianshu.com/p/ff48bc35ea08
共同学习,写下你的评论
评论加载中...
作者其他优质文章


