
Hello, 感觉好久没有写简书了,最近一直在忙支付和新需求,忙里偷闲学了一下 python 的简单使用,然后尝试的爬了一下"今日头条",效果还不错,下面简单介绍下我的第一个爬虫.不足之处请多多指教.
1.首先要捕获到目标的链接请求地址以及相应的参数
我是通过 chrome 自带工具,找到相应的 Request Url 和 parameters
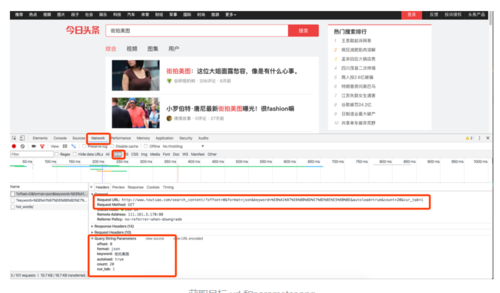
获取目标 url 和parameter.png
2.获取到相应的链接地址和参数之后,然后我们接下来要用 python 请求数据
首先导入数据请求库
import urllib.request as ur
通过观察发现,在请求参数中只有 offset 和 keyword 是变化的,所以我们创建一个数据请求方法将参数传入
def get_page_index(offset,keyword):
data = { 'offset': offset, 'format': 'json', 'keyword': keyword, 'autoload': 'true', 'count': '20', 'cur_tab': '1'
} try:
url = 'http://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E4%B8%89%E9%87%8C%E5%B1%AF%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1' + urlaa.urlencode(data)
reponse = ur.urlopen(url)
text = reponse.read()
text = text.decode('utf-8') return text except BaseException as e:
print(e)3.请求数据结束后需要解析返回的相应数据,得到相应数据之后我们需要对数据进行解析,然后得到我们有用的图片链接地址
解析数据方法代码如下:
def parse_page_index(html): data = json.loads(html) if data and 'data' in data.keys(): for item in data['data']: yield item['article_url']
首先将返回的数据解析为 json 数据,然后再通过看 json 串的结构来找到相应数据.
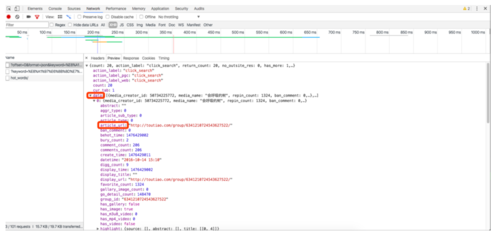
json 数据结构图.png
首先找到 data 字段,然后遍历其中的数组,获取到每个元素的article_url字段,观察发现article_url此字段为详情链接,然后我们需要进入详情界面分别获取到各文章相应的图片.
4.解析新闻详情界面数据
在解析详情界面时,我们需要用到 BeautifulSoup ,首先导入from bs4 import BeautifulSoup
之后建立获取详情数据方法
def parse_page_detail(html, url):
soup = BeautifulSoup(html, 'html.parser')
title = soup.select('title')[0].get_text() #正则表达式对象
images_pattern = re.compile(r'var gallery = (.*?);', re.S)
result = re.search(images_pattern, html) if result:
data = json.loads(result.group(1)) if data and 'sub_images' in data.keys():
sub_images = data['sub_images']
images = [item.get('url') for item in sub_images] return { 'title': title, 'url': url, 'images': images
}通过传入的链接地址,用BeautifulSoup库抓取网页数据,然后通过 select 方法获取到其标题为 title 的字段数据,之后将其转化为 json 串,然后找到相应新闻的标题,新闻链接和图片的链接地址数组.
以上为数据的抓取过程,之后部分为数据的存储
数据的存储我用到了两种方式:
1.MySQL
2.存取到本地
先来看存储到数据库
存取到数据库首先要创建数据库,导入pymysqlimport pymysql
之后链接到远程数据库
连接远程数据库.png
链接成功后我们先创建表格然后插入�相应的数据
def create_table_db():
sql = "create table if not exists tank_python_one(id INT primary key not null auto_increment ,title VARCHAR(100),url VARCHAR (100),images VARCHAR (1000))"
cursor.execute(sql)def save_info_sql(info, num):
sql = "insert into tank_python_one(title, url, images) VALUES(%s, %s, %s)"
images_str = ','.join(str(i) for i in info['images'])
data = (info['title'], info['url'], images_str)
cursor.execute(sql, data)
connect.commit() # print('成功插入', cursor.rowcount, '条数据')
save_file(info['title'], info['images'], num)到这里就可以将爬取下来的数据存储到相应的数据库表中了.
接下来看存储到本地
存储到本地用到了 urllib 库的urlretrieve方法,将图片的路径和创建文件的名称传入即可实现将网络图片下载到本地,十分简便
def save_file(filename, images, num): # 保存到本地 temp = 0 for url in images: pathname = '/Users/MyMac/Desktop/图片/%sx%sy%s.jpg' % (filename, num, temp) ur.urlretrieve(url, pathname) temp += 1 # print(pathname + '保存成功')
完整代码请看 github链接 https://github.com/spj393988297/python_toutiao.git
好啦,这样我的第一个 python 爬虫就完成啦,中间安装各种库也出现了一些的问题,但终于一一克服了,程序有许多的不完美之处,希望各位大神指点一二,毕竟刚学没经验.希望我们在求知的路上勇往直前.
Tank 无畏艰难险阻!
作者:Tank丶Farmer
链接:https://www.jianshu.com/p/d6a053f5eacb
共同学习,写下你的评论
评论加载中...
作者其他优质文章


