
一些网页,比如微博,只有在登录状态才能进行页面的访问,或者对数据有比较复杂的验证和保护,直接通过网络请求进行登录并获取数据就会比较麻烦。这种时候,就该本篇的主角 selenium 上场了。
Selenium 是一个用于 Web 应用程序测试的工具。它的优点在于,浏览器能打开的页面,使用 selenium 就一定能获取到。但 selenium 也有其局限性,相对于脚本方式,selenium 获取内容的效率不高。
本篇文章简单介绍 Selenium 下 webdriver 组件,它直接在浏览器中运行,其行为跟真实用户一样,打开浏览器、模拟输入内容、模拟点击按钮等等。Selenium 测试可以在市面上主流操作平台主流浏览器上运行。
1、安装
Selenium 本身的安装十分简单 ,使用 pip install selenium 即可,配置相应的 web 环境才是关键,Selenium 支持主流的 IE 、Chrome、Firefox、Opera、Safari、phantomjs等浏览器。
其中 Firefox 浏览器不需要任何配置可以直接调用,但 IE 、Chrome 等浏览器需要添加一个 driver 文件,以最常用的 Chrome 为例:
下载 chromedriver.exe
下载解压之后,将 chromedriver.exe 添加到和 python安装的根目录下,如图:
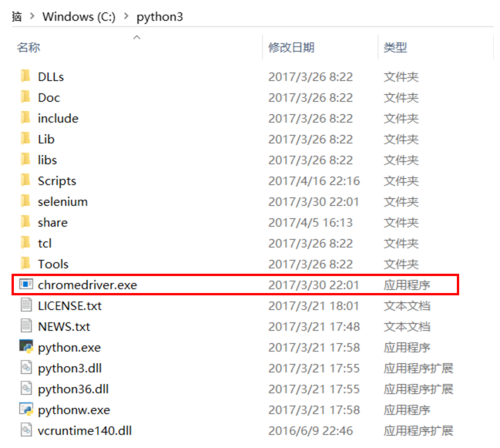
image.png
然后就可以在脚本中正常使用 selenium 调用 Chrome 了,IE 的配置方法类似。
很多同学使用 selenium 的初衷是作为爬虫使用或者对付反爬虫手段,用不着浏览器界面,希望程序在后台运行就可以了。我们推荐有这样需求的同学使用无界面的 PhantomJS 代替 Chrome 或者 Firefox。
安装过程如下:
下载 PhantomJS
将下载完成的 phantomjs.exe 添加到 python 安装路径中的 scripts 文件夹中,如图:
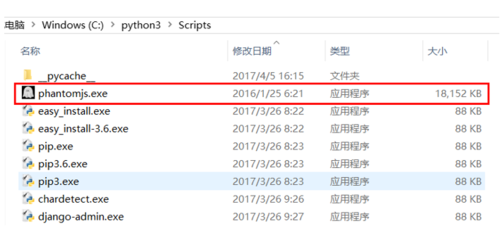
image.png
接着,就可以正常使用了。
2、基本使用方法
2.启动
完成安装以及环境配置之后,就可以正式的在脚本中调用了,我们以打开百度首页为例:
from selenium import webdriver# 调用 Chrome 浏览器driver = webdriver.Chrome()# 转到 百度 首页driver.get('http://www.baidu.com')以上就是一个最简单的打开网页的例子,当你使用 Firefox 时,调用方法:
driver = webdriver.Firefox()
使用 PhantomJS 时:
deriver = webdriver.PhantomJS()
2.2 选择器
selenium 定位一个网页中的元素有许多方式,可以使用 html 标签中的 id、name、class 等属性,也可以使用 XPath 路径,甚至 js 代码。
我们依然以百度为例,去定位页面中的输入框以及搜索按钮。
首先是 F12 启动开发者工具,然后点击页面元素选择按钮 ---> 点击需定位的元素 ---> 查看定位元素的源代码
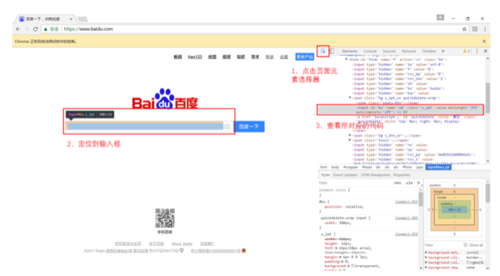
image.png
经过上图的流程,我们可以清楚的看到输入框的源代码为:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
根据源代码内容,我们可以以 id 、name、class 名等方式来定位该输入框,代码如下:
ele_input_id = driver.find_element_by_id('kw')
ele_input_name = driver.find_element_by_name('wd')
ele_input_cls = driver.find_element_by_class_name('s_ipt')使用相同的方式,我们可以定位 百度一下 这个搜索按钮:
按钮的源代码:
<input type="submit" id="su" value="百度一下" class="bg s_btn">
定位代码如下:
ele_btn = driver.find_element_by_id('su')以上就是简单的选择器知识
2.3 基本的页面操作方法
定位到页面的元素之后,我们会需要对该元素进行一些操作,比如输入内容、点击按钮等等。
继续以百度为例,定位到输入框和搜索按钮之后,依次输入搜索内容并点击搜索按钮。send_keys() 函数向浏览器发送信息,click() 函数模拟点击事件。
# 输入搜索内容ele_input_id.send_keys('Crossin的编程教室')# 点击搜索按钮ele_btn.click()结果如下:
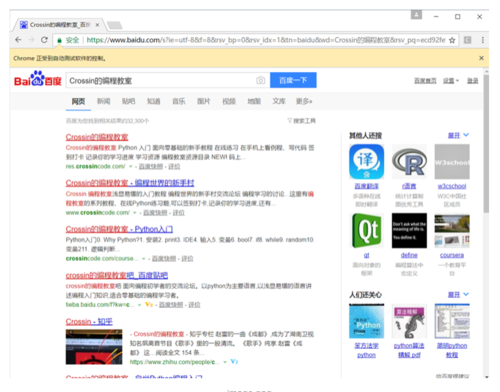
image.png
3、Selenium 获取 cookies
在爬虫领域中,常常使用 selenium 获取 cookies 应付反爬虫。
比如,爬取微博的内容,需要登陆状态,而保存的 cookies 会在一定时间后失效,这时候 selenium 就派上了用场,使用预先设置的账号密码登陆,然后获取 cookies 发送给脚本使用。
3.1 使用内置函数
获取 cookies 使用 get_cookies 函数,依然以百度为例:
cookie_r = driver.get_cookies()
打印出 cookie_r 是这样的:
[{'domain': '.baidu.com', 'httpOnly': False, 'name': 'H_PS_PSSID', 'path': '/', 'secure': False, 'value': '22584_1465_21087_18560_22581'}, {'domain': '.baidu.com', 'expiry': 3639883283.649732, 'httpOnly': False, 'name': 'BAIDUID', 'path': '/', 'secure': False, 'value': '69F8E8C5CF050F0C8CA3C358CB08BAC6:FG=1'}, {'domain': '.baidu.com', 'expiry': 3639883283.649952, 'httpOnly': False, 'name': 'PSTM', 'path': '/', 'secure': False, 'value': '1492399635'}, {'domain': '.baidu.com', 'expiry': 3639883283.649925, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': '69F8E8C5CF050F0C8CA3C358CB08BAC6'}, {'domain': 'www.baidu.com', 'expiry': 1493263637, 'httpOnly': False, 'name': 'BD_UPN', 'path': '/', 'secure': False, 'value': '12314753'}, {'domain': 'www.baidu.com', 'expiry': 1492399637.649969, 'httpOnly': False, 'name': 'BD_LAST_QID', 'path': '/', 'secure': False, 'value': '18362646771513028098'}, {'domain': 'www.baidu.com', 'httpOnly': False, 'name': 'BD_HOME', 'path': '/', 'secure': False, 'value': '0'}, {'domain': '.www.baidu.com', 'expiry': 1492399642.240359, 'httpOnly': False, 'name': '__bsi', 'path': '/', 'secure': False, 'value': '16804089554912194086_00_0_I_R_3_0303_C02F_N_I_I_0'}, {'domain': 'www.baidu.com', 'expiry': 1492399647, 'httpOnly': False, 'name': 'WWW_ST', 'path': '/', 'secure': False, 'value': '1492399637585'}]此形式的 cookies 是不能直接传递给脚本使用的,我们需要进一步的处理,提取出每个字典 name 和 value 值,将其组合在一起。
cookies_list = []for i in cookie_r: cookie = i['name'] + '=' + i['value'] cookies_list.append(cookie) cookies_str = ';'.join(cookies_list)
经过处理的 cookies_str 就可以直接发送给 脚本使用了,打印出 cookies_str 如下:
H_PS_PSSID=22583_1433_21106_17001_20929;BAIDUID=456846B8C2CECBC077CA6A700DA24A89:FG=1;PSTM=1492400387;BIDUPSID=456846B8C2CECBC077CA6A700DA24A89;BD_HOME=0;BD_UPN=12314753;__bsi=16211205307050373314_00_0_I_R_2_0303_C02F_N_I_I_0;WWW_ST=1492400389401
3.2 执行 js 函数
获取 cookies 不仅仅可以通过 get_cookies 函数,还可以直接使用 javascript 代码,示例:
# 字符串形式的 js 代码js_code = 'return document.cookie'# 执行 js 代码cookies = driver.execute_script(js_code) print(cookies)
此时获取的 cookies 可以直接发给脚本使用,结果如下:
BAIDUID=7ABCBA83953DC58B59943B0967D10098:FG=1; BIDUPSID=7ABCBA83953DC58B59943B0967D10098; PSTM=1492400818; BD_HOME=0; H_PS_PSSID=22584_1457_21106_17001_21673_20927; BD_UPN=12314753; __bsi=17435099398291019533_00_0_I_R_2_0303_C02F_N_I_I_0; WWW_ST=1492400820362
这里我们只简单介绍一下获取 cookies 的方法,在 selenium 中执行 javasript 代码还有更多更精彩的玩法,就不在这里展开讲了。
4、结语
在本篇文章中,我们简单的介绍了 selenium 的安装使用过程,以操作百度首页为例,演示了如何定位、如何启用事件、如何获取 cookies 应对基本的反爬虫手段。
当然,selenium 所包含得内容远不止此,详细内容请查看官方文档:
http://www.seleniumhq.org/docs/
作者:zx576
链接:https://www.jianshu.com/p/b6fc84e7ee0e
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



