
NeurIPS 2025论文已正式公布——信息量庞大。此可视化项目(建议在电脑端浏览)通过聚类分析、摘要生成和大语言模型(LLM)解析,让您能够以交互方式探索完整的研究版图,轻松把握领域动态。
 点击探索NeurIPS 2025(建议在电脑端查看)
点击探索NeurIPS 2025(建议在电脑端查看)
该可视化项目整合了Cohere的生成与嵌入模型,并采用下文所述的工作流程,实现对海量文本数据的探索。数据最终通过定制化的datamapplot进行可视化呈现。
突破信息过载:探索前沿研究的重要性
NeurIPS作为机器学习领域的顶级会议,一直是重要研究成果的发布平台。基于多次参会经验,这一盛会在以下方面存在挑战:
- 领域发展迅速:从5月投稿截止到12月会议召开期间,机器学习领域往往已发生显著演进。提前研读论文具有重要价值
- 规模庞大:需要更有效的工具来应对信息过载,人工智能与可视化的结合提供了可行的解决方案
- 跨领域理解难度大:对于非专业领域的研究工作,大语言模型能够提供通俗易懂的解析
过去几年中,我经常构建交互式可视化工具来辅助论文探索。鉴于本届录用论文名单刚刚发布,现将该可视化项目分享供大家自行探索。
可视化功能导览
 左侧浏览主题层级结构,右侧直接操作图谱
左侧浏览主题层级结构,右侧直接操作图谱
放大显示可查看更精细的子聚类名称。用户也可以展开顶层分类查看内部的主要聚类。点击主题树中的聚类名称可将图谱聚焦到该聚类区域。聚类名称由大语言模型生成建议后经人工修订。
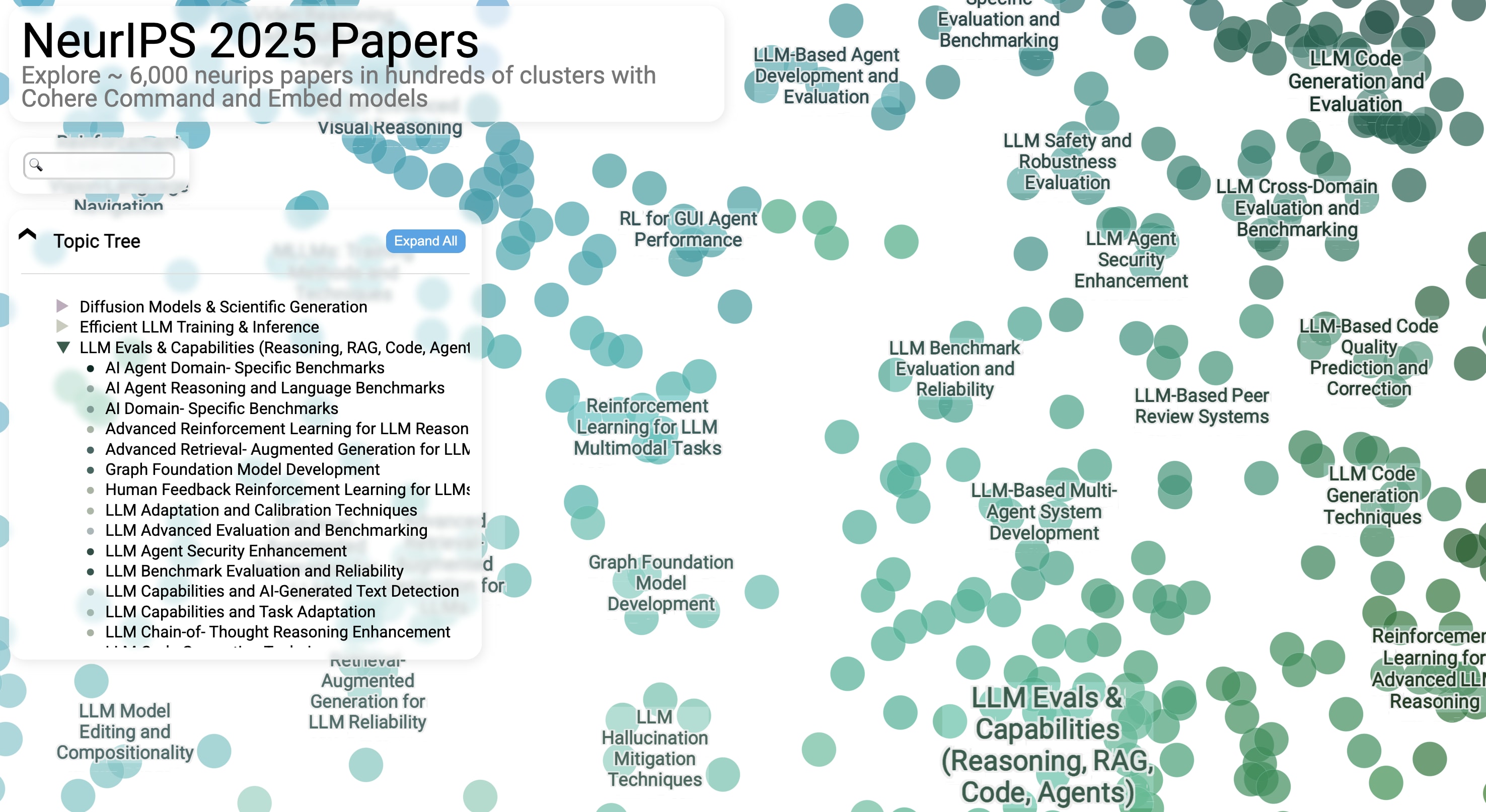 放大显示更精细研究领域的论文名称
放大显示更精细研究领域的论文名称
悬停论文节点可显示包含标题和摘要的信息。为了提供更深入的分析,系统还展示了大语言模型提取的摘要、问题陈述和方法论,以及"面向五岁孩童的解释(Explain Like I’m 5, ELI5)"——这一功能在探索非专业领域时尤为实用。
 悬停论文显示标题、作者和摘要等详细信息
悬停论文显示标题、作者和摘要等详细信息
提示框除了展示摘要外,还提供其他解析部分:
 除标题和摘要外,还可阅读大语言模型生成的总结、ELI5解释、问题陈述、方法论和实际应用
除标题和摘要外,还可阅读大语言模型生成的总结、ELI5解释、问题陈述、方法论和实际应用
会议观察
主要研究方向:大语言模型、多模态与强化学习
这三类研究构成了最显著的集群。它们不仅是主要的聚类类别,还经常作为子主题出现在其他集群中(通过多标签分类处理,单篇论文可属于多个聚类)。根据统计,约28%的论文以多模态为主要研究方向,13%聚焦强化学习(存在交叉)。另有13%的论文涉及评估方法和推理研究。
大语言模型推理研究显著增加。由于O1模型的发布,推理能力成为NeurIPS 2024会议的热点话题。这一趋势在本次录用论文中得到延续。统计显示766篇论文以推理为核心研究方向。
 推理成为2025年最突出的突破性主题之一
推理成为2025年最突出的突破性主题之一
扩散模型与大语言模型、强化学习共同构成会议的三大主题
图谱顶部区域以计算机视觉和多模态研究为主,其西部区域集中探索扩散模型的各个方面。
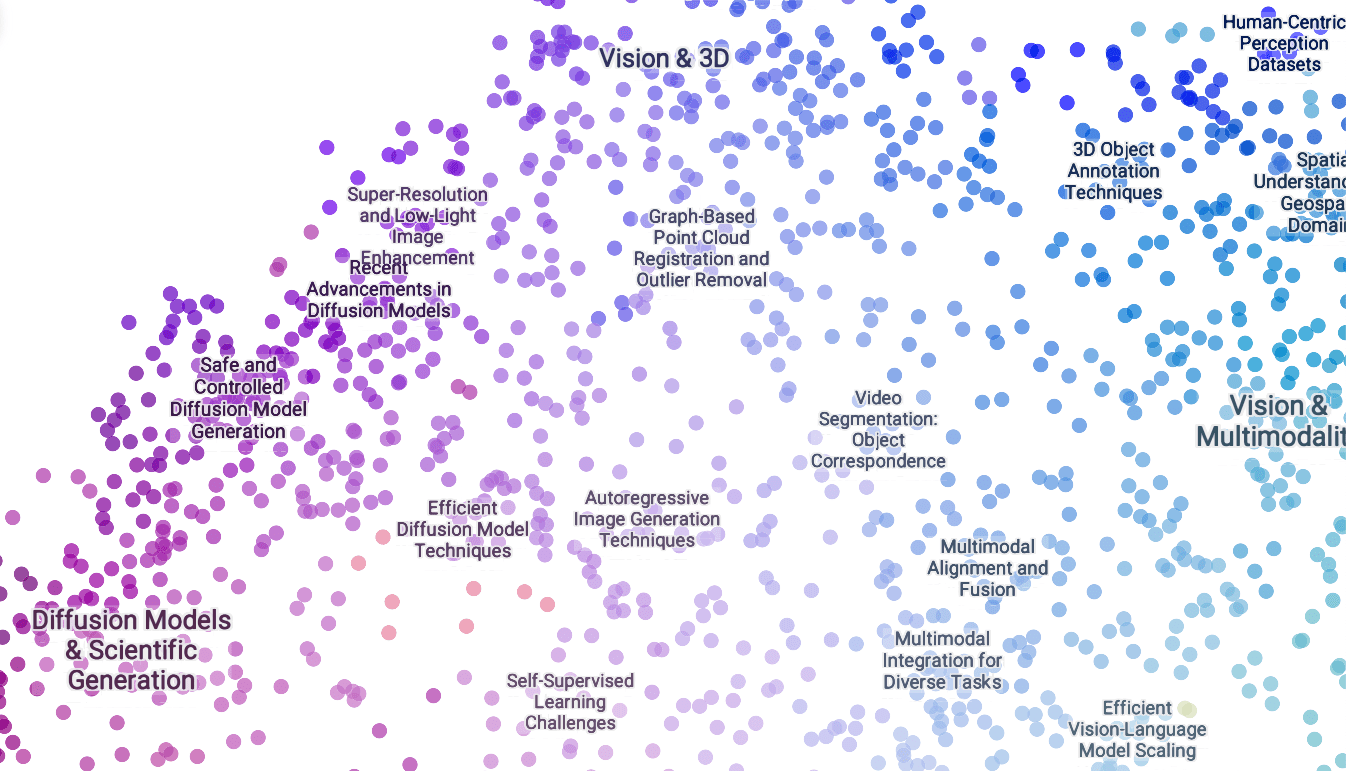 计算机视觉紧随文本之后成为第二大模态,在生成和表征领域均有重要子类别
计算机视觉紧随文本之后成为第二大模态,在生成和表征领域均有重要子类别
主题树中显示多个扩散模型的主要聚类:
 扩散模型应用的广泛性
扩散模型应用的广泛性
在科学领域探索时,ELI5功能具有重要价值。我的阅读策略是:先看摘要,如果理解有困难,就转向ELI5解释,然后再回顾摘要,这样通常就能更好地理解内容。这种辅助理解复杂概念的方式展现了扩展人类认知的潜力。
 ELI5帮助理解生僻领域(附加思考题:什么是薛定谔桥问题?)
ELI5帮助理解生僻领域(附加思考题:什么是薛定谔桥问题?)
另一个示例:
 阅读流程:先读摘要,不理解时查看ELI5,再回看摘要,理解就更清晰了
阅读流程:先读摘要,不理解时查看ELI5,再回看摘要,理解就更清晰了
人工智能对人类认知的扩展作用
本方案将人工智能技术应用于多个子问题,以降低海量文本的阅读难度。
个体文本分析
部分处理步骤作用于单个文本,部分应用于群体(聚类)以辅助导航:
- 文本提取
- 分类处理
- 问答解析
- 摘要生成
文本到文本模型的优势在于可以一站式完成所有任务:准备提示词模板,将每篇文本注入模板,最终生成5,787个提示词(对应会议录用论文数量)。
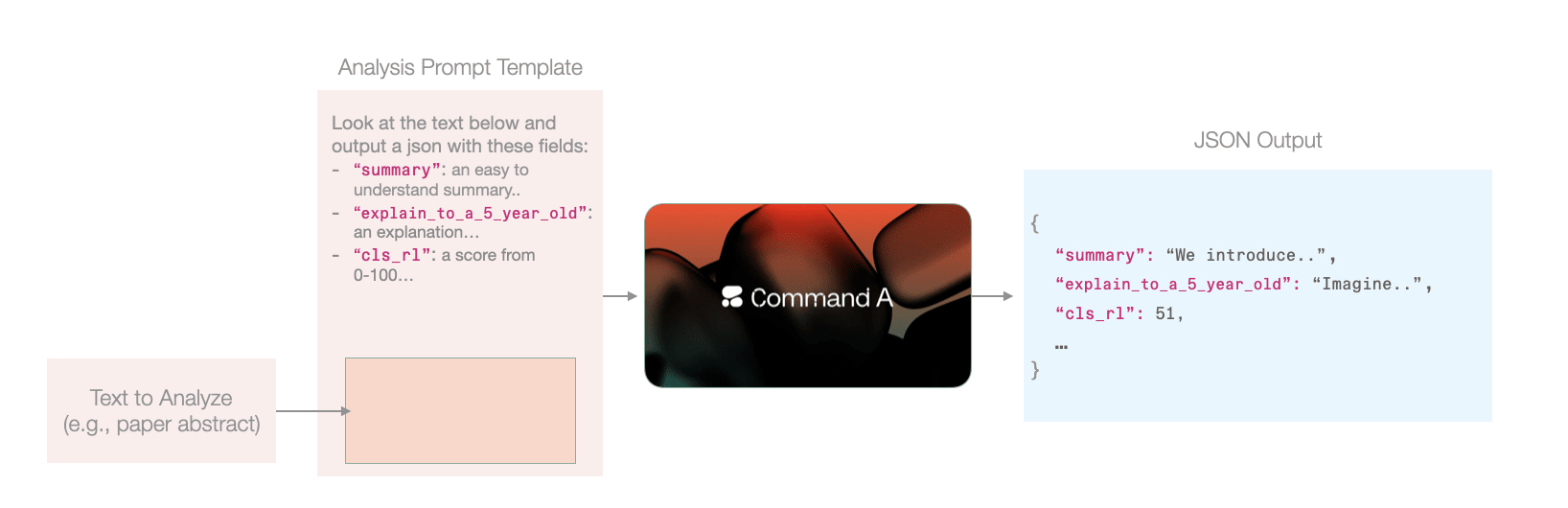 批量分析数千文本时,使用可插入待分析文本的提示词模板,再将各提示词提交大语言模型
批量分析数千文本时,使用可插入待分析文本的提示词模板,再将各提示词提交大语言模型
如果仅通过交互界面使用大语言模型,将无法发挥处理数千提示词的能力。考虑到成本因素,目前尚不宜委托多个智能体执行此类任务。因此这些任务通常由人工触发,通过独立脚本或工作流运行。
细粒度聚类分析
三年前撰写的《通过文本聚类从万篇Hacker News帖子中挖掘洞察》所述流程与本方案高度吻合:
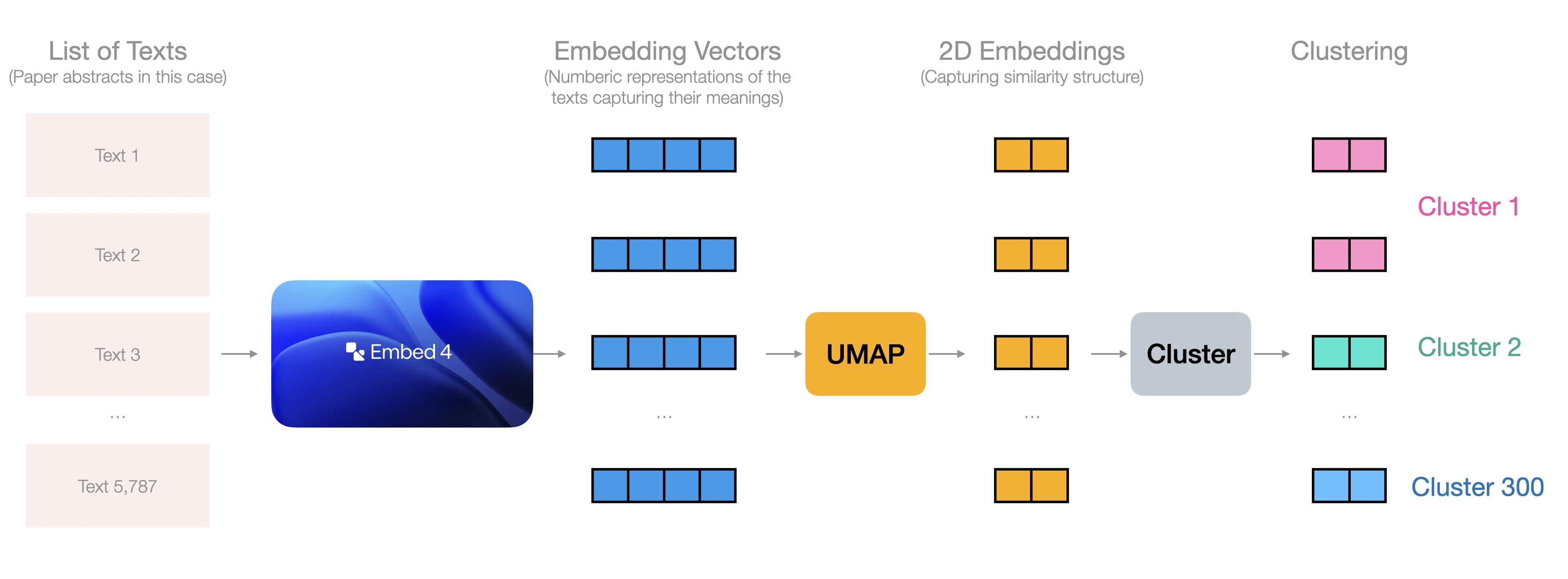 嵌入捕捉文本信息,UMAP将表征降维至二维并保持相似文本邻近
嵌入捕捉文本信息,UMAP将表征降维至二维并保持相似文本邻近
论文摘要经嵌入处理后,通过UMAP降维至二维,再通过K均值聚类算法划分为多个小集群。这些集群后续提交模型进行命名。UMAP降维步骤虽然导致大量信息损失,但为了保障图谱连贯性(确保相似聚类真正聚集),这种折衷是可以接受的。在其他应用场景中,可以选择直接对嵌入向量进行聚类或降维至中间维度。
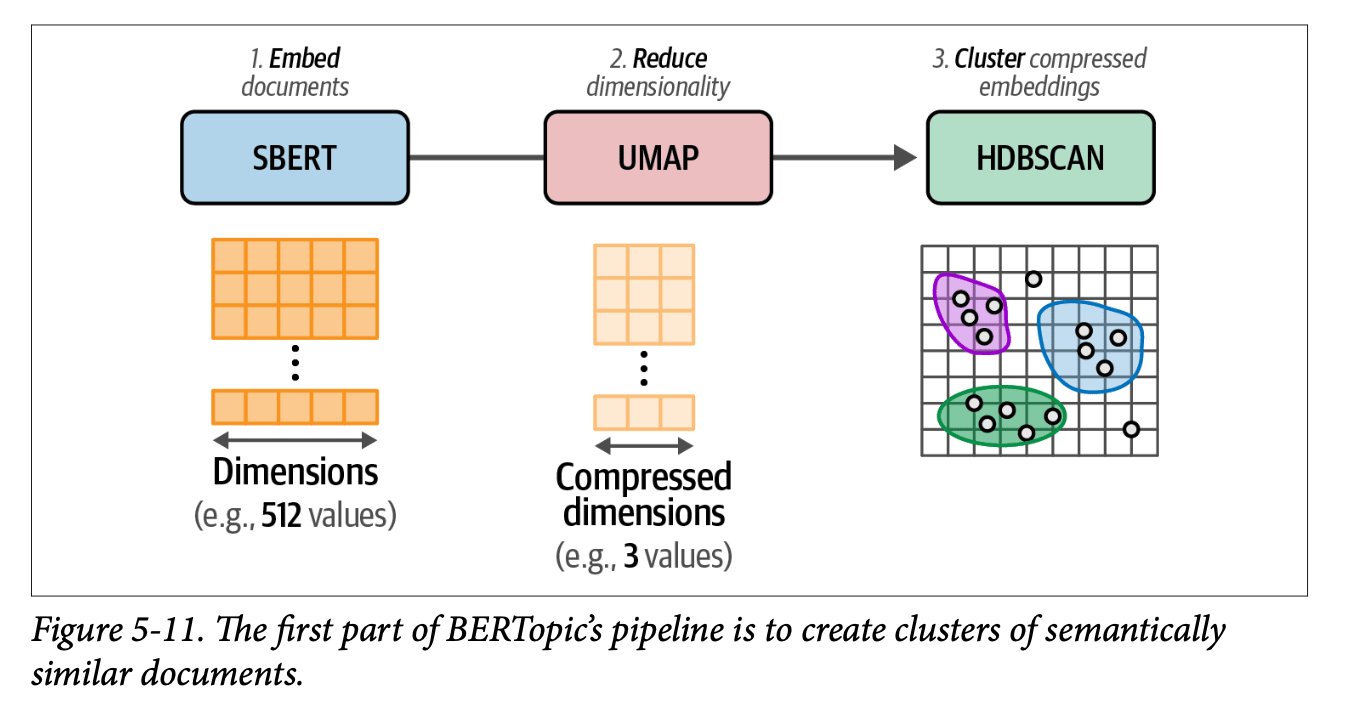
更多流程细节可参阅《动手学大语言模型》第五章。
层级聚类整合
通过向量绘图清晰展示聚类效果:
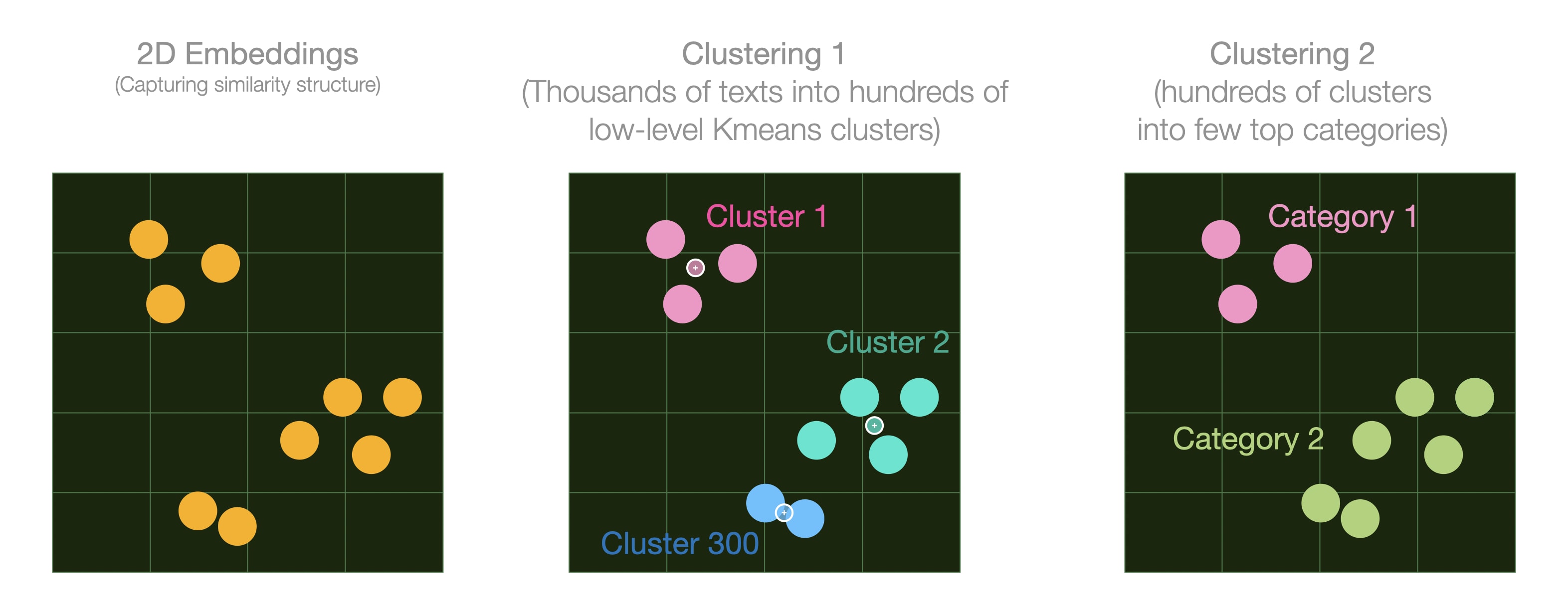 双层聚类实现层级命名(类似谷歌地图的城市和国家层级)
双层聚类实现层级命名(类似谷歌地图的城市和国家层级)
第二网格中的小圆点为聚类中心(即聚类质心,由K均值算法生成)。对这些中心再次聚类可生成高层分类(如10个顶层类别)。这一步骤已经为图谱添加了大量信息,但为聚类赋予有意义的名称能进一步释放其价值。
聚类命名策略
此时嵌入模型与生成模型开始协同工作:基于嵌入聚类与摘要,将每个聚类提交生成模型命名。可以选择使用完整摘要或前一步生成的摘要。
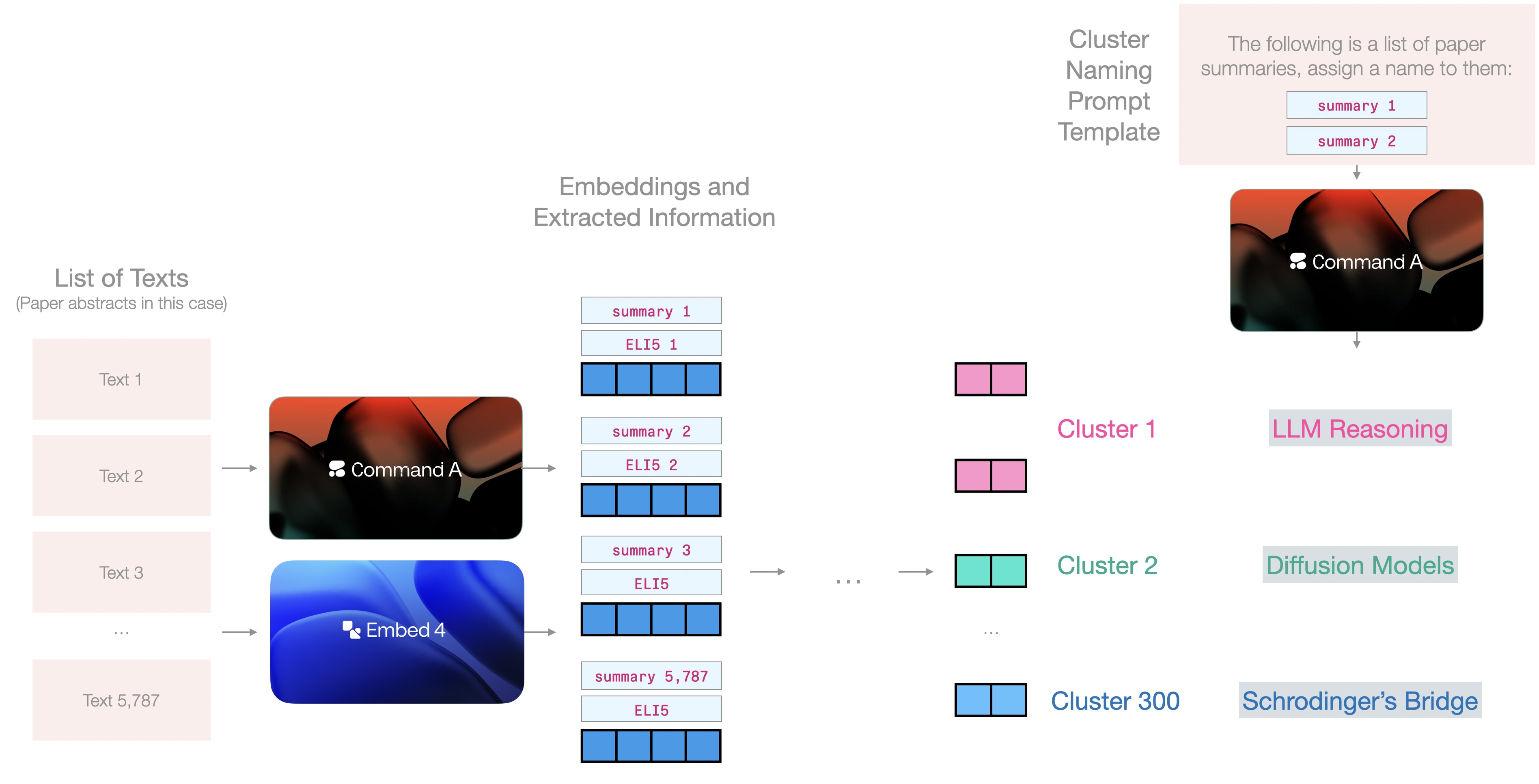 大语言模型通过提取和聚类命名等多种任务丰富处理流程
大语言模型通过提取和聚类命名等多种任务丰富处理流程
除了简单采样外,还有多种命名技术。最后将数据导入datamapplot并定制参数,即可得到最终图谱。
上下文传递与宏观聚类命名
本工作流凸显了处理流程中各环节间上下文传递的重要性。提示工程与上下文工程是大语言模型应用的关键,这在处理流程中尤为突出。
如果模型仅接触单个聚类的论文,相邻聚类可能都被命名为"LLM推理":
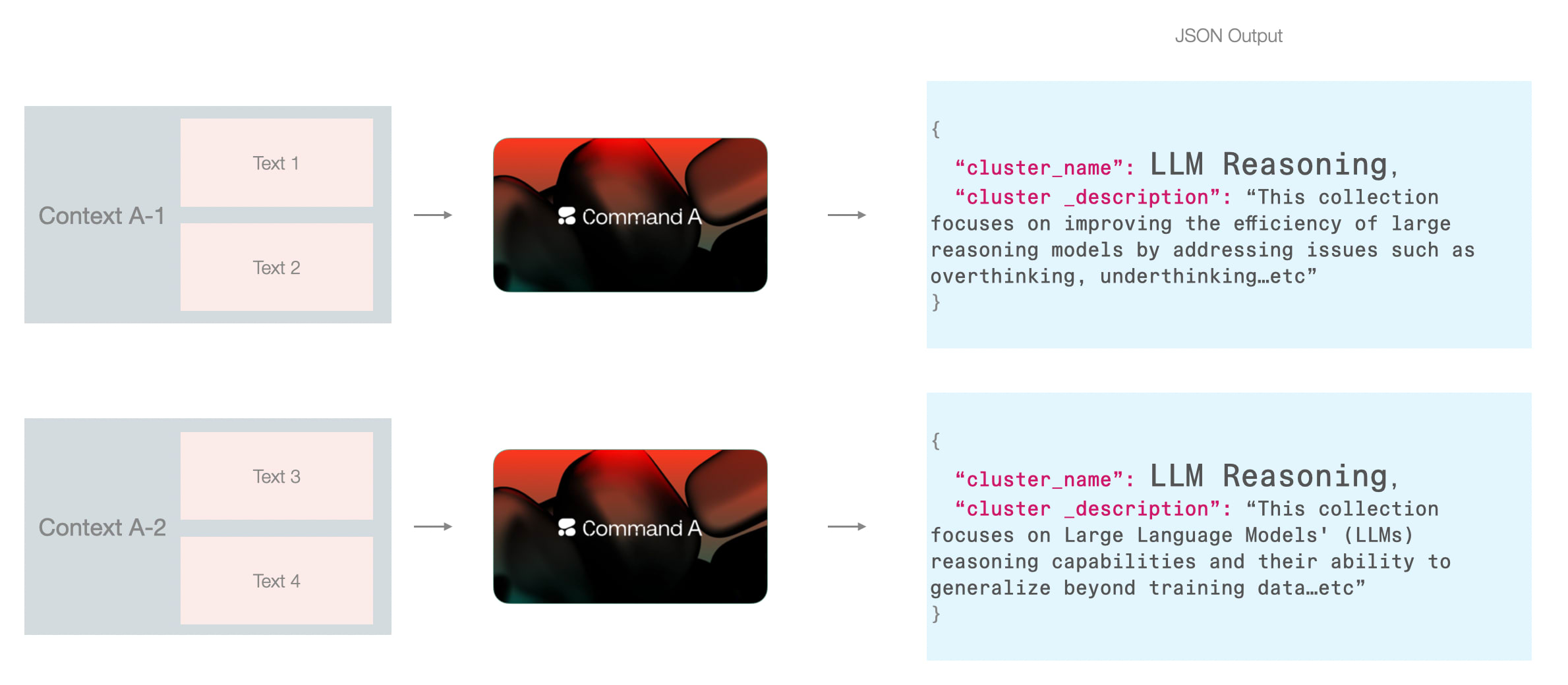 仅基于单个聚类的论文进行命名
仅基于单个聚类的论文进行命名
解决方案包括:打包其他聚类的论文进行协同命名:
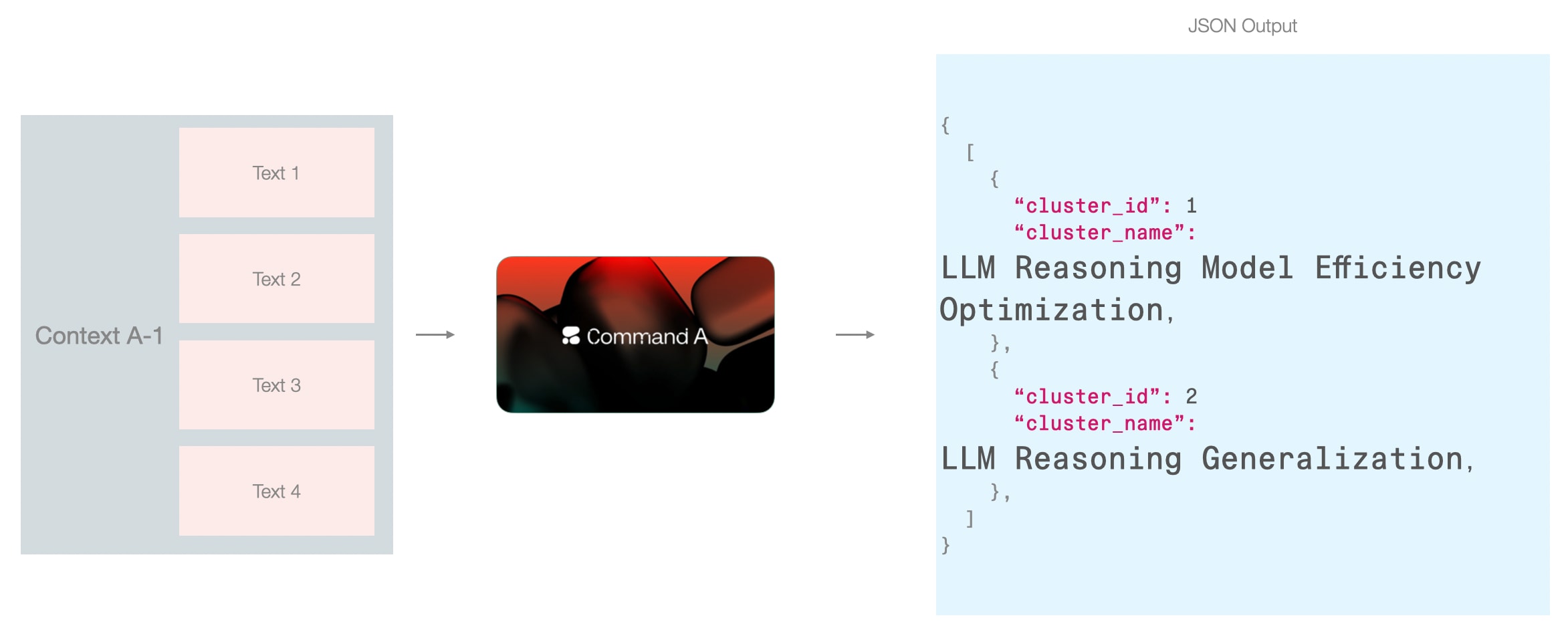 当模型能够同时处理多个聚类的文本时,可以获得全局视野,但可能超出上下文长度限制
当模型能够同时处理多个聚类的文本时,可以获得全局视野,但可能超出上下文长度限制
如果数据量适合模型的上下文长度,此方案可行。另一种方案分两步进行:1)基于单个聚类初步命名,2)让模型在首次命名后重新审视所有聚类。
 两阶段方案兼顾独立命名与全局优化
两阶段方案兼顾独立命名与全局优化
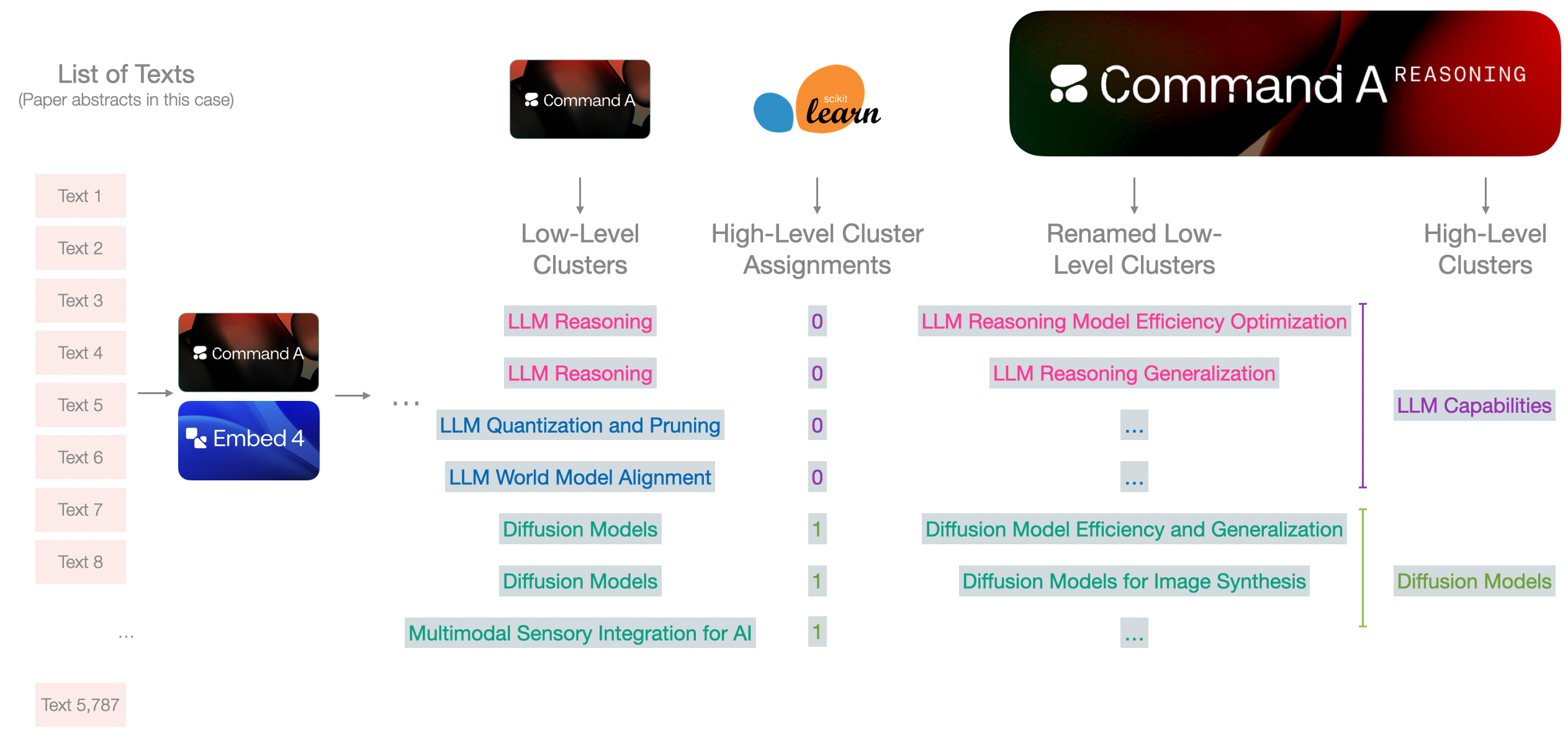
本流程采用此方案,因其与高层聚类(或称"类别")命名步骤自然契合。第一阶段让模型专注于单个聚类,第二阶段通过生成的聚类描述(包含足够细节)实现上下文传递,避免重命名阶段信息过载。
提示词模板结构示例如下:
 第二阶段大语言模型同时完成高层命名与底层聚类去重优化
第二阶段大语言模型同时完成高层命名与底层聚类去重优化
由于调用次数有限,可以使用更高级的模型(如Command-A Reasoning)进行推理。以下为类别命名的推理轨迹示例:
对于高层类别命名,应该概括这个主题。"LLM推理"和"评估"等术语浮现脑海。由于该类别属于更大的机器学习研究集合,需要具体命名。"**LLM推理与评估**"似乎很合适,因为它同时涵盖了开发和评估两个方面。
模型信息
Command A、Command A Reasoning和Embed 4于2025年初发布。可以通过55页的Command A技术报告了解其构建细节。
未来工作与局限
本方案仅为可行流程之一,仍有改进空间。期待更多人创新方法与界面,赋能个体以更高效的方式处理海量信息。
需要进一步发展的方向包括:
- 细粒度聚类审阅自动化:目前可通过电子表格快速扫描集群,重点审阅大聚类名称。但当集群数量达到数百个时,需要更多工具辅助
- 噪声处理更强的聚类流程:HDBSCAN在此有优势。通常采用K均值初步聚类后,将包含少量论文的集群视为噪声(尽管语义相似,但可能无法形成连贯分组)
- 支持多拓扑切换的交互界面:Datamapplot已具备部分功能,计划深入探索
致谢
感谢Adrien Morisot、Ahmet Ustun、Case Ploeg、Eugene Cho、Irem Ergun、Keith Hall、Komal Kumar Teru、Madeline Smith、Nick Frosst、Patrick Lewis、Rafid Al-Humaimidi、Sarra Habchi、Sophia Althammer、Suhas Pai、Thomas Euyang、Trent Fowler和Varun Kumethi提供的反馈、建议与讨论。
您是否尝试过类似方法?欢迎在评论区分享经验!
共同学习,写下你的评论
评论加载中...
作者其他优质文章



