
文生图(Text-to-Image)已能精准理解”一个人站在远处”。但当你试图将一张独立的人物素材”合成”到一张风景背景中时,比例崩溃却依然是最高频的翻车现场。本教程将从AI的空间认知缺陷讲起,系统传授”语义锚定”和”视觉围栏”两大核心技法,覆盖单人物卡位、多人物协同、局部换脸三大场景,帮你彻底拿回对画面空间的控制权。

第一章:为什么你的图生图总是”比例翻车”?——AI空间认知的结构性缺陷
在动手修图之前,我们必须先弄懂一个根本问题:AI对”空间”的理解,远没有你想象中聪明。 理解了这一点,后续所有技巧才不会变成死记硬背的操作手册,而是你真正能举一反三的底层认知。作为找到AI的讲师现在就给你们拆解整个流程
1.1 文生图 vs 图生图:AI的”两种思维模式”
你也许已经体验过2026年文生图的惊人能力——无论是即梦AI基于Seedream 4.0模型,还是Midjourney V7(以及其V8 Alpha测试版),只要你用文字写下”一位身穿白衣的剑客,站在云海翻涌的仙山之巅,远处是层峦叠嶂的群峰”,AI几乎都能给你一张比例完美、透视合理的画面。

但图生图(Image-to-Image)的工作模式完全不同。 当你上传一张剑客素材和一张仙山背景,要求AI”把人放进景里”时,你实际上是在强制要求AI融合两个各自拥有独立视觉上下文的图像资产。每张图都有自己的构图逻辑、光影体系和空间比例尺——AI需要在后处理阶段”硬拼”它们。
下面这张对比表,清晰地展示了两种模式的本质差异:
|
维度
|
文生图
|
图生图合成
| 输入形式 |
统一的文本描述
|
多张独立图像 + 文本指令
|
| 空间协调方式 |
全局注意力机制自动协调
|
缺乏跨图像的统一空间坐标
|
| 比例确定时机 |
生成过程中实时计算
|
需要在生成之前人为约束
|
| 典型失败模式 |
极少出现比例问题
|
人物偏大/偏小/位置随机
|
| 类比理解 |
画家在同一张画布上同时构思所有元素
|
要求画家把两张剪好的纸片贴到一起
|
💡 核心认知:文生图 = AI在一个统一世界里”从零创造”;图生图合成 = AI被迫把两个”平行世界”的东西强行缝合。缝合的裂缝,就是比例崩溃的根源。
1.2 语义孤岛效应(Semantic Isolation):AI看到的不是”人在景中”,而是”两坨像素”
2026年3月,北京大学与字节跳动Seed团队联合发表的SpatialScore研究,从技术层面精准验证了一个事实:当前AI图像生成模型的空间位置理解能力,远远落后于其画面美学水平。
将这一结论应用到图生图场景中,问题就更加突出。当你把”古风剑客”的人物素材和”仙山云海”的背景素材分别上传时:
一处位于仙峰之巅的宽阔平坦山顶台地,开阔的地形覆盖着光滑的古老石面,部分区域生长着青苔与野草,台地边缘骤然落入四面八方延伸至天际的无尽云海,几根风化的石柱和破碎的古代祭坛遗迹散落在平地之上,稀疏的古松以优雅的轮廓从石面裂缝中生长而出,精致的野花和发光的灵草点缀在台地地面上,薄薄的雾气在地面轻轻飘过,远处相邻的仙山峰顶若隐若现地从遥远的云海中探出,台地远端一条古老石阶向下延伸消失在云层之中,微妙的发光灵气粒子如萤火虫般漂浮在空中,温暖的黄金时刻阳光在平坦地形上投下柔和的长影,天空从地平线附近的淡琥珀色过渡到头顶的深邃天蓝色并隐约可见星轨。低角度机位从地面水平视角眺望整个台地,强调广阔平坦的开放空间与壮观的云海背景。写实风格融合中国仙侠奇幻美学,UE5游戏渲染,光线追踪体积雾,大气散射,照片级环境,下一代开放世界游戏品质,宽银幕电影构图,中心留有适合放置人物的开阔空间。

4张纯白背景的人物参考表:左边是特写头像,右边3张是纯白背景的全身视图(正面,侧面,背面)。一个饱经风霜的中国古代剑客,采用逼真的UE5游戏引擎风格:穿着高度精细的多层传统汉服系统,采用基于物理渲染(PBR)的丝绸和麻布材质,外层深色长袍带有逼真的磨损边缘和因多年漂泊留下的战斗撕裂痕迹,胸前斜挎一条磨旧的皮革剑带,黄铜扣件呈现铜绿氧化质感,内层白色中衣在衣领和袖口处隐约可见精致的云纹刺绣,头戴一只松松系着的古铜发冠,几缕黑色长发在风中自由飘动,腰间丝绦悬挂一枚玉佩——半透明玉石上呈现逼真的次表面散射效果,一柄纤细的直刃长剑置于古旧漆木剑鞘中,鞘面漆面龟裂并缠有丝绳,双前臂佩戴布皮结合的护腕并带有缝线细节,脚穿草编旅行草鞋配裹踝绑带显示真实的泥土磨损,背后用细绳挂着一顶竹编斗笠,腰间系着一只小葫芦酒壶。面部特征:棱角分明的下颌线,冷静锐利的眼眸带有细微的鱼尾纹暗示丰富阅历,左颊一道细长刀疤,淡淡的胡茬。配色方案:深墨黑外袍,柔和象牙白内衣,陈旧青铜与黄铜金属配件,风化棕色皮革,翠玉色玉佩,微妙的酒红色腰带。逼真的3D游戏角色概念,虚幻引擎5风格渲染,光线追踪照明,逼真的毛发与布料模拟细节,下一代游戏资产质量,高细节纹理,中国武侠美学与写实风格结合。

-
你脑中的指令
:”把这个剑客放到画面中景偏右的位置,大约占画面高度的五分之一,站在一块突出的悬崖上。”
-
AI接收到的信息
:两组独立的像素矩阵 + 一条模糊的文本指令。
AI在融合这两组像素时,缺乏一个关键信息——空间锚点(Spatial Anchor)。它不知道剑客在三维空间中”距离镜头多远”,不知道剑客的身高和仙山中某棵松树的比例关系是什么,更不知道你希望他出现在画面的哪个精确位置。
于是,AI只能退而求其次,依赖训练数据中的”统计平均值”进行盲目猜测。
1.3 两种典型失败模式
基于上述原理,图生图的比例翻车本质上只有两种模式:
❌ 失败模式一:人物偏大,吃掉环境纵深
这是最高频的翻车现场。例如,当我们尝试将详细的剑客‘丢’进仙山中时,AI为了尽可能保留人物素材上的服饰细节、面部特征,会倾向于把人物放大、放到画面中心。结果呢?你精心准备的万丈云海,看起来就像人物身后两米远的一幅背景布。原本应该壮阔到令人敬畏的仙山,被压缩成了影楼幕布。
将图2人物自然的放到图1中

❌ 失败模式二:人物过小,被环境吞噬
反过来,如果AI过度”尊重”背景图的完整性,它就可能把人物缩成一个几乎不可辨认的米粒大小的黑点,塞进画面的某个角落。你的主角变成了”找不同”游戏中的隐藏目标。
⚠️ 注意:最难处理的其实不是上述两种极端,而是**“差之毫厘”的微妙失调**——人物不是大得离谱,但就是比”正确”大了那么一点点。这种程度的偏差会让整个画面丧失真实的透视感,观者虽然说不出哪里不对,但就是觉得”假”。这就是视觉领域著名的”恐怖谷效应”(Uncanny Valley)在构图层面的体现。
第二章:单人物精准卡位——两大核心武器
理解了AI”不懂空间”的底层原因后,解决方案的方向就非常清晰了:你必须在AI开始生成之前,就替它把空间信息”算好”。
2026年的主流工具提供了两条路径:一条靠”写好文字”,另一条靠”画好框”。
2.1 武器一:语义锚定法——用文字给AI画”刻度尺”
核心逻辑:既然AI缺乏空间锚点,那你就在提示词中用文字手动植入这个锚点。方法是加入具体的、可量化的物理参照描述。
看下面的案例对比:
📋 场景:将一位古风白衣剑客合成到一幅仙山云海的宏大背景中。
| |
模糊写法 ❌
|
精准写法 ✅
| 提示词 |
“把剑客放到仙山背景中”
|
“把剑客放到仙山画面的中景偏右处,人物高度约占画面垂直高度的六分之一,脚踩一块突出的岩石,体现出人物的渺小与山河的壮阔,光影与背景统一重构”
|
| AI理解 |
两张图需要拼在一起
|
人物有明确的大小限制和位置约束
|
| 典型输出 |
剑客占据画面一半高度,仙山变背景布
|
剑客在远景岩石上,如一粒白点,仙山气势磅礴
|
具体来看精准写法的关键构成:
将图2中的白衣剑客自然融入图1的仙山云海场景中, 人物位于画面中景偏右的突出崖壁上, 人物高度约占画面垂直高度的六分之一, 体现出人物在天地间的渺小感, 光影与环境统一重构,风格保持一致

逐句拆解:
-
将图2中的白衣剑客自然融入图1→ 明确哪张是人物、哪张是背景
-
位于画面中景偏右的突出崖壁上→ 锚定位置(中景 + 偏右)
-
人物高度约占画面垂直高度的六分之一→ 锚定大小(最关键!)
-
体现出人物在天地间的渺小感→ 给AI一个情感意图辅助判断
-
光影与环境统一重构→ 避免”贴图感”(重构可能让场景更改,但是融合的更加好)
💡 进阶Tips:语义锚定法的三种实用表达模板
除了”占画面高度的几分之几”外,你还可以用以下三种方式表达比例约束:
-
环境参照物法
:”人物大约只有背景中瀑布落差的十分之一高”
-
透视层级法
:”人物处于画面的远景层,大小与远处树木相当”
-
画面占比法
:”人物整体面积不超过画面总面积的3%”
三种方式可以叠加使用,给AI越多的约束信号,输出越准确。
⚠️ 语义锚定法的局限:这种方法依赖AI对文字的理解精度。在大多数情况下,AI能大致遵守你的比例描述,但”六分之一”和”七分之一”的细微差别,它未必能百分之百还原。如果你需要像素级别的精准控制,请直接使用下面的第二种武器。
2.2 武器二:视觉围栏法(区域框选)——最推荐的”物理答案”
这是本教程最核心的技巧,没有之一。
核心逻辑:与其用文字”描述”比例,不如直接用鼠标”画出”比例。在背景图上画一个框——这个框的大小就是人物的大小,这个框的位置就是人物的位置。
「框」就是你替AI做出的空间决策。
📐 分步操作指引(以献丑AI为例)
第1步:准备背景图并绘制位置框
打开你的仙山云海背景图,在你希望剑客出现的位置,用红色(或任何醒目颜色)手动画一个矩形框。
-
想要剑客显得渺小 → 把框画小
-
想要剑客充满力量感 → 把框画大
-
想要剑客在远处 → 把框画在画面上方偏远处(符合近大远小的透视逻辑)
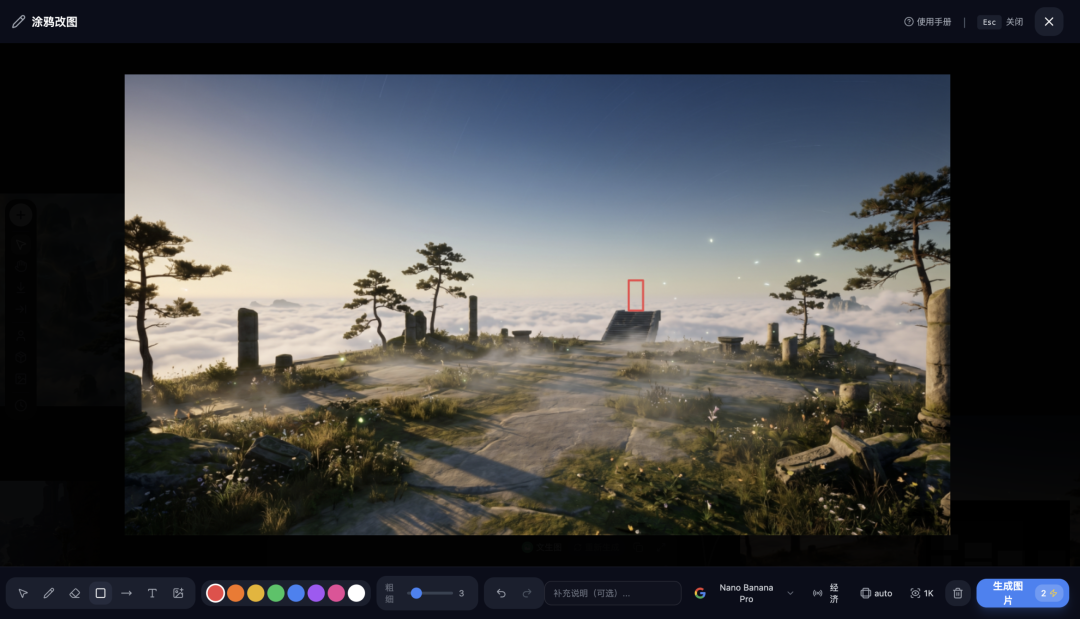
第2步:上传素材
-
上传带有标记框的背景图
-
上传你的剑客人物素材图
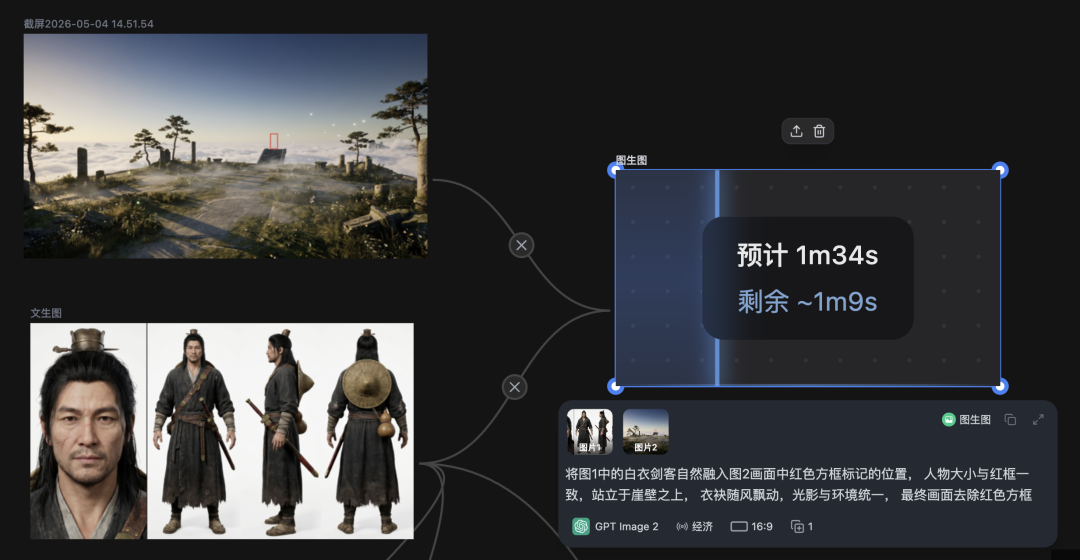
第3步:输入精准提示词
将图1中的剑客自然融入图2画面中红色方框标记的位置, 人物大小与红框一致,站立于崖壁之上, 衣袂随风飘动,光影与环境重构统一, 最终画面去除红色方框

第4步:生成并检验
AI会严格遵照框的位置和大小来放置人物。最后一句”去除红色方框”会让AI在输出时自动擦除标记。
💡 关键心法:框的大小 = 人物的大小,框的位置 = 人物的位置。 这是一条可以背下来反复使用的铁律。
📊 框大小 vs 画面效果的对应关系
|
框的大小(占画面高度)
|
视觉效果
|
适用场景
< 1/10
|
极度渺小感,人物几乎融入环境
|
展现自然壮阔、孤独感、史诗构图
|
|
1/8 ~ 1/5
|
远景人物,主体可辨但环境为主
|
开放世界概念图、场景主导型构图
|
|
1/4 ~ 1/3
|
中景人物,人景并重
|
角色海报、游戏截图感
|
|
> 1/2
|
近景人物,人物为绝对主体
|
人物特写、角色立绘放入环境
|
第三章:多人物协同编排——用”框阵”构建画面纵深
单个人物的比例定位掌握之后,进阶问题来了:如何在一张背景图中精准放入两个甚至三个以上的人物,且他们之间有合理的纵深层次和自然互动?
3.1 多人物合成的经典翻车:所有人”排排坐”
假设我们的场景是一间灯火昏黄、弥漫着市井烟火气的武侠客栈。我们要往里面放入三个角色:
-
站在柜台后面的掌柜(近景偏左)
-
坐在中间桌旁喝酒的游侠(中景居中)
-
角落里小声说书的说书人(远景偏右)

如果你只写一句”把三个人物放到客栈里”,AI大概率会:
-
把三个人挤在画面同一个深度平面上
-
三个人大小基本一致(无视近大远小)
-
彼此之间没有任何空间层次,像三张纸片贴在同一面墙上

这是因为AI在没有框选约束的情况下,默认将所有元素放在同一Z轴深度上。 它不会主动帮你区分”谁在前、谁在后”。
3.2 差异化框选:近大远小自己定义
解决方案极其直观:给每个角色画不同大小、不同位置的框。
操作原理:
-
掌柜
(近景)→ 画一个大框,放在画面左侧偏下方
-
游侠
(中景)→ 画一个中等框,放在画面中部
-
说书人
(远景)→ 画一个小框,放在画面右上方的角落

将图1的掌柜角色放入背景图蓝框位置, 将图2的游侠角色放入绿框位置, 将图3的说书人角色放入红框位置, 三人姿态自然各异,光影与客栈环境统一, 最终画面去除所有彩色方框

AI的空间”脑补”能力:即梦AI等2026年的主流工具有一个巧妙的隐含逻辑——只要你把框的大小和高低位置错开了,AI在生成时会自动推断出空间的Z轴(深度)。
具体表现为:
-
前景大框中的掌柜 → 高清细节清晰可见,衣纹、胡须纤毫毕现
-
中景中框中的游侠 → 细节适度,自然融入环境光影
-
远景小框中的说书人 → 自动带上景深模糊和环境阴影,完美融入背景角落
你不需要在提示词中写”请模拟近大远小的透视效果”之类的废话。框的大小差异,就是透视信息本身。
📊 多人物框选策略速查表
|
人物角色
|
叙事位置
|
框的大小
|
框在画面中的位置
|
AI自动效果
掌柜
|
前景
|
大(约画面高度的1/3)
|
左下方
|
高清细节 + 浅景深
|
|
游侠
|
中景
|
中(约画面高度的1/5)
|
中部偏下
|
适度细节 + 自然光影
|
|
说书人
|
远景
|
小(约画面高度的1/8)
|
右上角落
|
模糊虚化 + 环境融入
|
3.3 互动法则:框要”打架”才有戏
以上解决了”各站各位”的问题。但如果你需要两个角色之间有肢体互动——比如你希望生成”掌柜正从柜台后面递出一碗热汤给游侠”,或者”两个食客正在凑在一起耳语”?
这里有一条铁律,务必记死:
⚠️ 两个角色的框完全分开 = 两人各干各的,互不往来。
✅ 两个角色的框有部分重叠 = AI理解为两人在空间上有接触,会自动生成互动肢体。
这背后的原理是:AI在处理框选区域时,重叠的像素区域会被同时关联到两个角色的语义信息上。只有当两个角色在像素层面有共享区域时,AI才会在这个区域中尝试”连接”两个人物——伸出的手、递出的物品、交错的目光等。
操作要点:
-
为掌柜画一个框(蓝色)
-
为游侠画一个框(绿色)
-
两个框在”递汤”的交接区域有约20%~30%的面积重叠
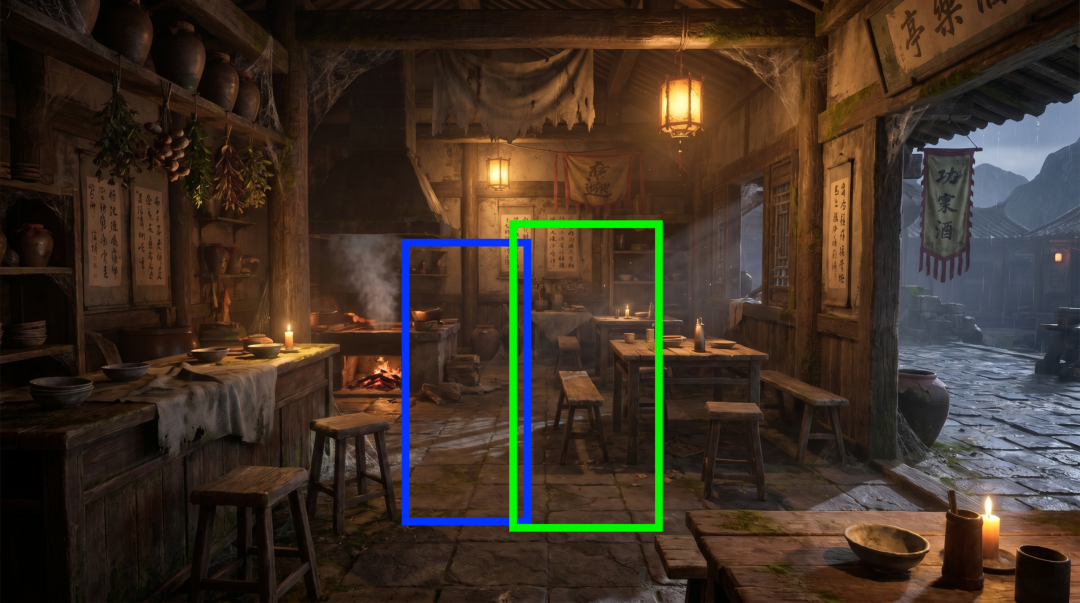
蓝色框中的掌柜正将一碗热汤从柜台递出, 绿色框中的游侠伸手接过热汤, 两人有自然的眼神交流和肢体接触, 光影与客栈环境统一重构, 最终画面去除所有彩色方框

💡 框重叠比例的经验建议
-
轻微互动
(对视、点头):重叠面积约 10%~15%
-
中等互动
(递物、握手):重叠面积约 20%~30%
-
紧密互动
(拥抱、搏斗):重叠面积约 40%~60%
重叠过多容易导致两人”粘”在一起轮廓模糊;重叠过少则互动不够自然。建议从30%开始尝试,根据输出结果微调。
第四章:局部换脸的”大头陷阱”——参考图构图比才是元凶
经过前三章的训练,你已经能让人物以完美的比例”站”进环境中了。但很多创作者在最后一步”精装修”时栽了跟头——换脸。
场景是这样的:你生成了一位原始部落的妇女弓箭手。现在你想把角色的面容替换成一张你指定的美女脸部参考图。
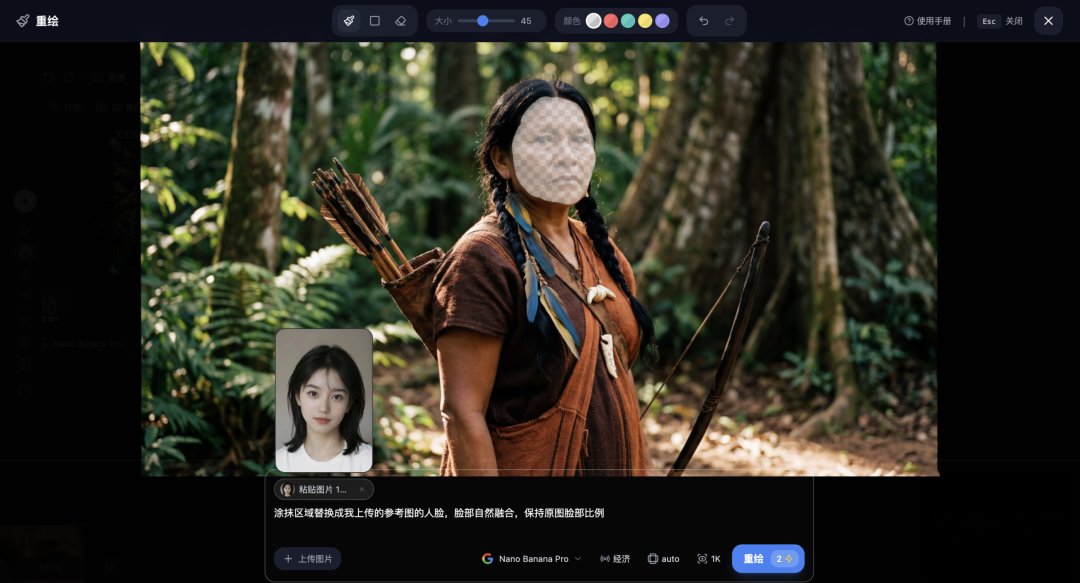
你使用局部重绘(Inpainting)功能,框选头部区域,上传参考脸部照片。结果出来一看——一个硕大无比的脑袋突兀地安在了妇女身体上,直接从原始部落风格变成了Q版搞笑表情包。

4.1 “大头娃娃”的真正原因
你可能会怀疑是参数设错了、权重调歪了。但真正的原因远比你想的简单,也远比你想的容易忽略:
参考图中面部的画面占比与选框区域不匹配。
这是你喂给AI的要替换的参考图人脸的图片:

让我们还原这个错误的完整链条:
-
你的全身图中,头部只占画面高度的约 1/8
-
你用框选工具圈了头部区域,框也大约是画面的 1/8
-
但你喂给AI的参考照片是一张大头特写,脸占了照片面积的 90%
-
AI的”死脑筋”逻辑
:它在处理局部重绘时,会严格参考参考图的”构图逻辑”。它看到参考照片里脸占了90%的面积,于是它就在你框选的那1/8区域内,试图也把脸填满90%……
结果就是:AI强行把脸部像素拉大,塞满整个选框区域,原本的脖子、肩膀、衣领全被超大号脑袋吞噬了。
💡 一句话归因:参考图的面部占比太大,与选框区域的实际可用空间严重不匹配。AI忠实地”复制”了参考图的构图比例,结果就崩了。
4.2 一招根治:对齐参考图的面部占比
解决方案极其简单,完全不需要调整任何权重或高级参数:
使用面部画面占比更小的参考图。
| |
错误做法 ❌
|
正确做法 ✅
| 参考图类型 |
脸部塞满画面的极致大头特写
|
半身照、胸像照或包含头肩部的特写
|
| 参考图中面部占比 |
80%~95%
|
30%~50%
|
| AI的处理逻辑 |
试图在选框内也把脸放到80%,导致脸部巨大化
|
脸部比例适中,与选框区域自然匹配
|
| 输出效果 |
大头娃娃
|
面容自然过渡,头身比协调
|
具体操作:
-
将你的脸部参考图裁剪为包含完整头部 + 脖子 + 部分肩膀的构图
-
确保面部在参考图中的占比不超过50%
-
上传这张调整后的参考图进行局部重绘
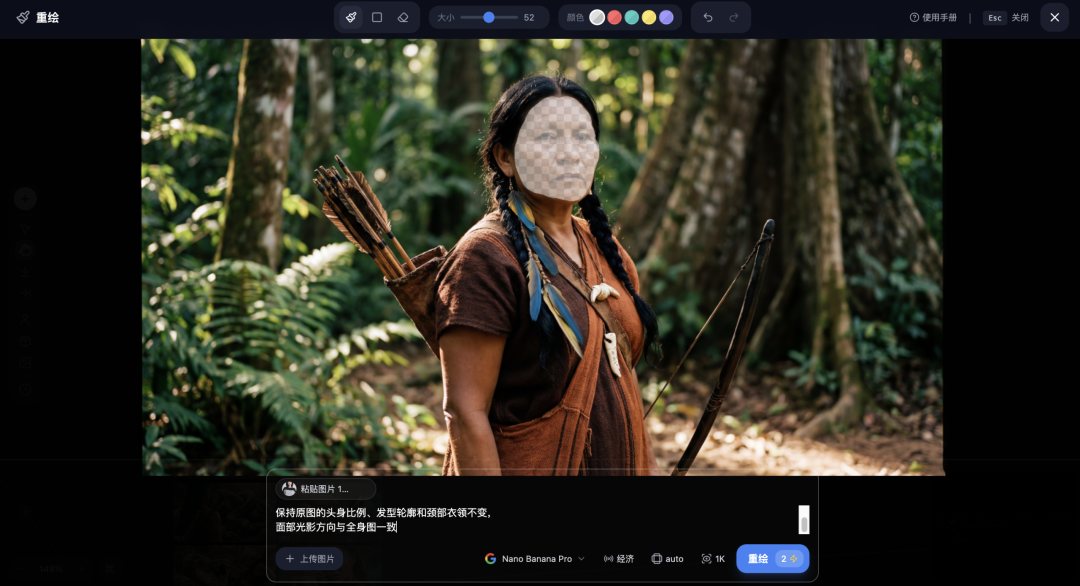
将选框区域内的面部替换为参考图中的面部特征, 保持原图的头身比例、发型轮廓和颈部衣领不变, 面部光影方向与全身图一致

⚠️ 注意:这个技巧的本质是——你喂给AI的参考图,其构图比例应该尽可能接近你所框选区域在全图中的构图比例。参考图的”面部占比”和选框的”头部占比”对齐了,比例问题就自然消失了。
第五章:总结与行动清单
核心口诀回顾
如果你只记住这篇教程的一句话,请记住这个:
「提示词管内容,选框管比例。」
提示词负责告诉AI**“是什么”——什么角色、什么姿态、什么风格。而选框负责告诉AI“多大、在哪”**——这才是解决比例失控的物理答案。
✅ 四条即刻可执行的行动法则
-
单人物入景
:在背景图上画一个框。想要纵深感 → 框画小;想要压迫感 → 框画大。提示词中加上”人物大小与框一致,最终去除框”即可。
-
多人物编排
:每人一个框,用框的大小差异来模拟近大远小。前景角色 = 大框,远景角色 = 小框。AI会自动脑补深度和景深。
-
角色互动
:需要两人有肢体接触?让两人的框重叠约20%~30%。完全分开的框 = 两人毫无关系。
-
局部换脸
:永远不要用脸部塞满画面的大头特写做参考。使用半身照或胸像照,让参考图中的面部占比与选框区域匹配。
🔁 举一反三:这套逻辑还能用在哪?
“选框定比例”的方法论并不只适用于人物合成。以下场景同样适用:
-
产品图合成
:将一瓶饮料”放入”户外野餐场景 → 画框确定产品大小
-
建筑可视化
:将概念建筑模型”放入”城市天际线 → 画框确定建筑体量
-
宠物萌图
:将宠物素材”放入”微缩模型场景 → 画框制造”小人国”效果
-
电商场景图
:多个产品在同一场景中展示 → 多框控制每个产品的位置和大小
掌握了这套最直观的视觉引导逻辑,你就不再需要盲目”抽卡”碰运气,也不再需要堆叠冗长的提示词去”恳求”AI给出正确的比例。你只需要——画一个框。
声明:找到AI所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得找到AI同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若找到AI内容侵犯了原著者的合法权益,可联系我们进行处理。
共同学习,写下你的评论
评论加载中...
作者其他优质文章



