
一文看懂即将开源的 JimuChatBI积木问数(Chat2BI):是什么、解决什么问题、怎么用

一、JimuChatBI 是什么
JimuChatBI积木问数(Chat2BI) 是积木报表推出的对话式智能数据分析产品,即将开源。
它的定位很简单——让数据开口说话:业务同学不用写 SQL、不懂建模,用自然语言提问,就能秒级完成取数、生成 SQL 和可视化图表。它是 JimuReport积木报表继 AI 报表、AI 大屏之后补上的又一块拼图,专门解决企业里"找数难、取数慢"的老问题。
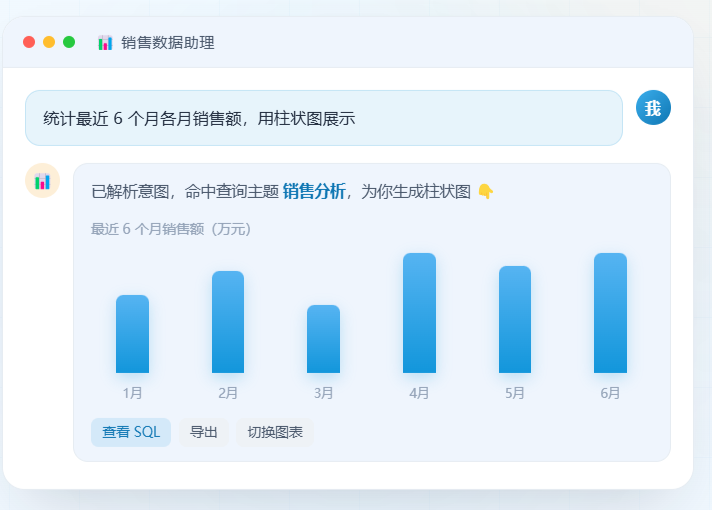
简单说,你问一句"统计最近 6 个月各月销售额,用柱状图展示",它就直接给你一张柱状图,外加明细表格和背后的 SQL。
二、它能解决什么问题
在没有 JimuChatBI 之前,企业取数通常是这样的:业务提需求 → 产品转工单 → 分析师写 SQL → 排期 → 出报表,一来一回两三天,改个维度又得重来一遍。
JimuChatBI 要解决的就是这条又长又慢的链路,核心价值落在三点:
一句话:它让"问数据"这件事,既像聊天一样简单,又能保证算得准、对得上。
三、核心能力一览

- 自然语言取数:用大白话提问,自动出表格、图表和一句话结论,支持 9+ 种图表类型。
- 指标 / 维度即时调整:看完一张图想换个角度,直接在对话里切维度、换图表,改完即时重算。
- 多形态输出:表格 + 图表 + 可查看的 SQL,还能一键导出 Excel、存为报表或加入大屏。
- 语义建模可信底座:表注册、字段识别、多表关联、查询主题、术语映射,把数据库翻译成 AI 听得懂的业务语言。
- 企业级权限:管理员授权、公开/私有控制、行级/列级权限、敏感度分级,敏感数据按需开放。
四、怎么用:三步上线
JimuChatBI 的使用流程收敛成清晰的三步,3 步建模即可上线。
第一步:搭数据底座(语义建模)
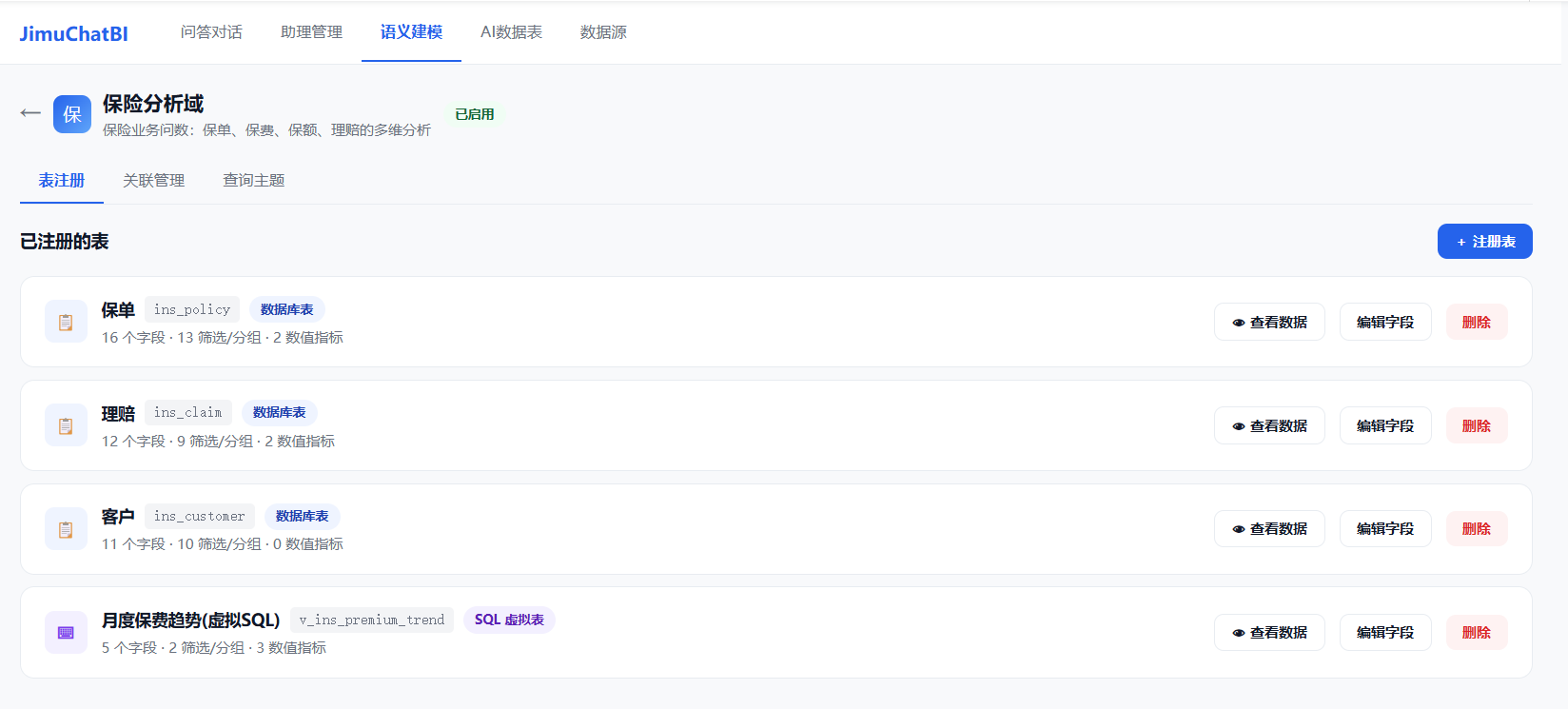
注册数据库表或 SQL 虚拟表,AI 自动识别主键、维度、指标,再配置多表关联、查询主题和业务术语。这一步是地基,决定了 AI 查得准不准。
数据域
查询主题
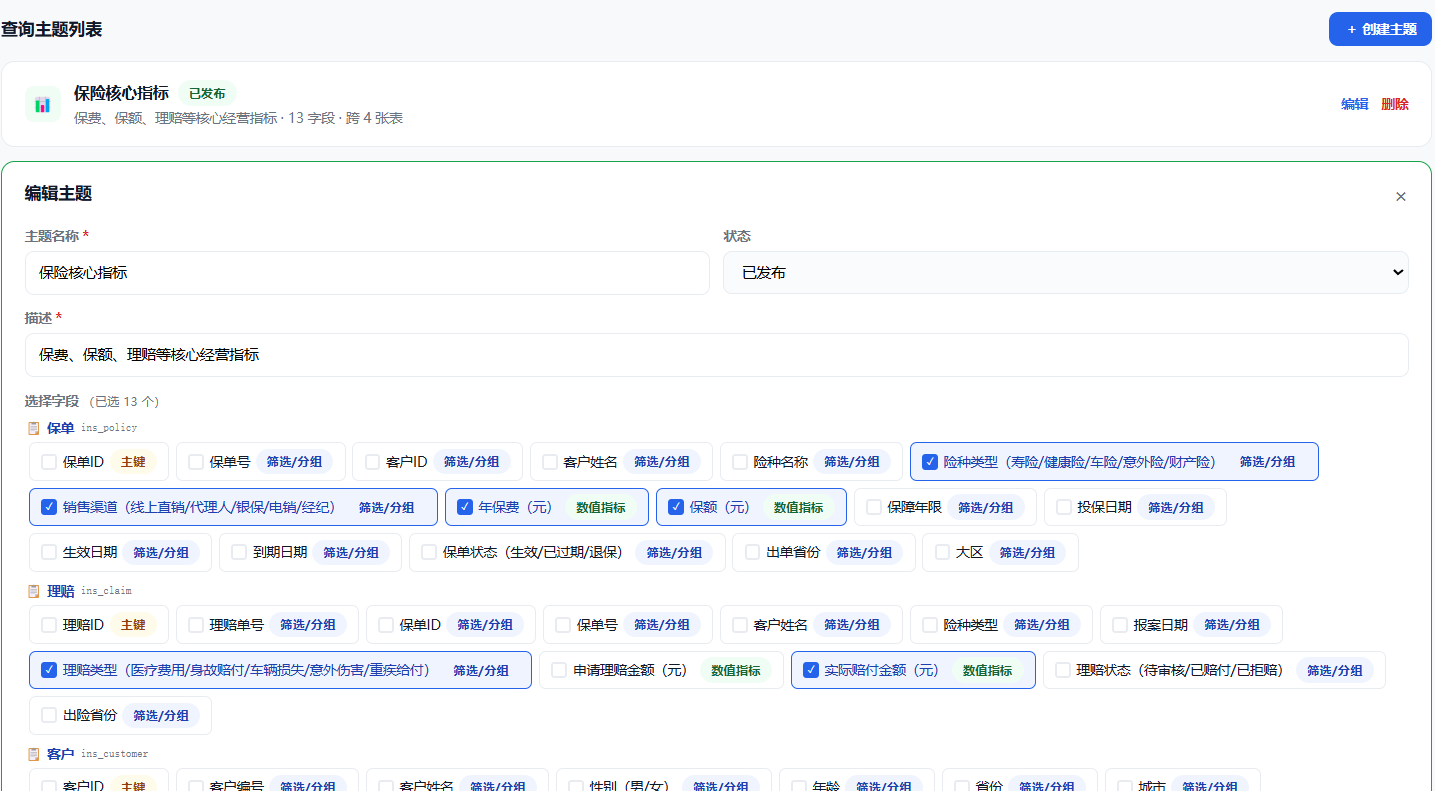
比如一张销售订单表,order_no 是主键(订单号),region、channel 是维度(地区、渠道),amount、qty 是指标(销售额、销量,按 SUM 聚合)——这些"身份"标好,AI 才知道该怎么分组、对什么求和。
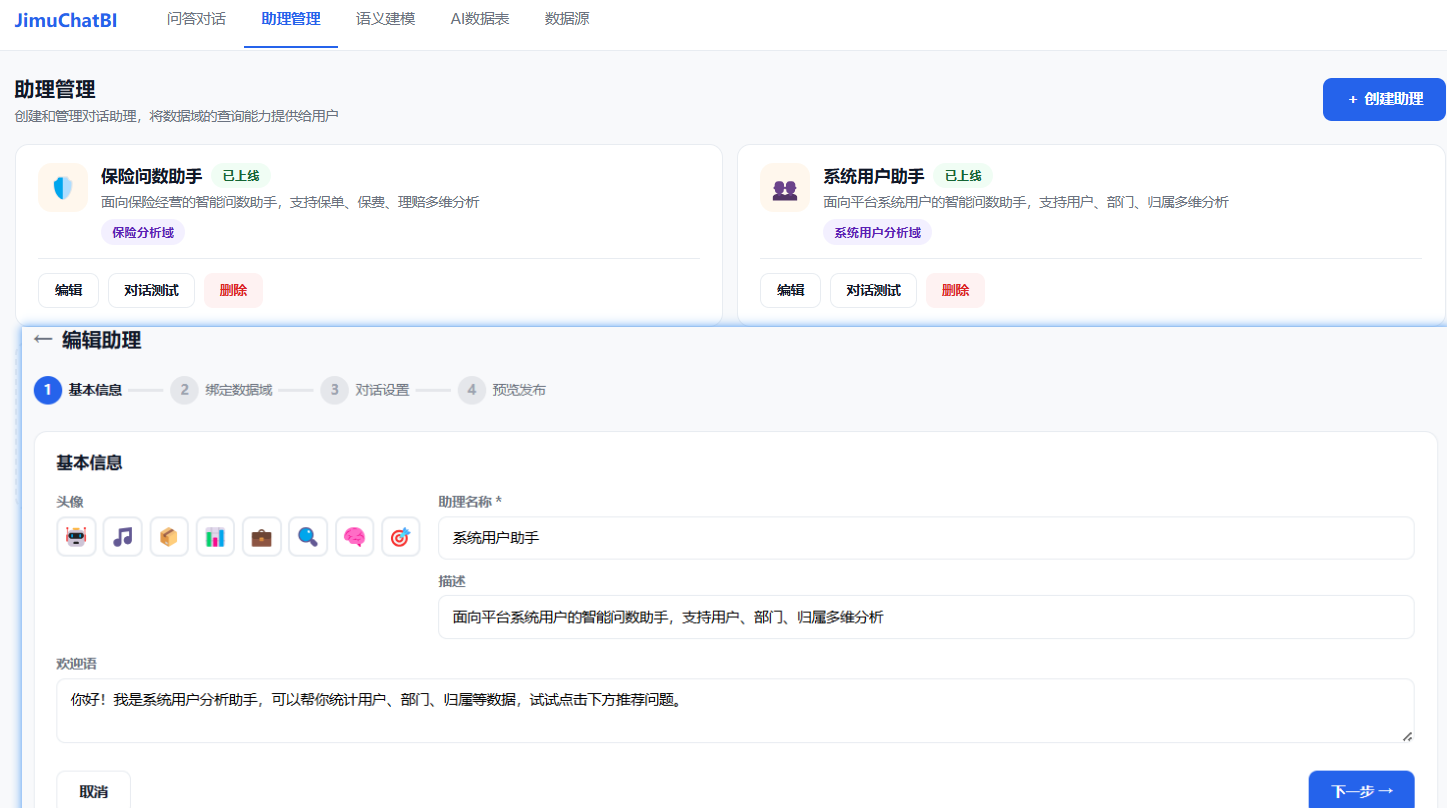
第二步:创建 AI 助理
四步向导即可完成:填基本信息(头像、名称、欢迎语)→ 绑定数据域 → 配置推荐问题、是否展示 SQL → 预览效果后一键发布上线。发布后,这个助理就能精准服务对应的业务团队。
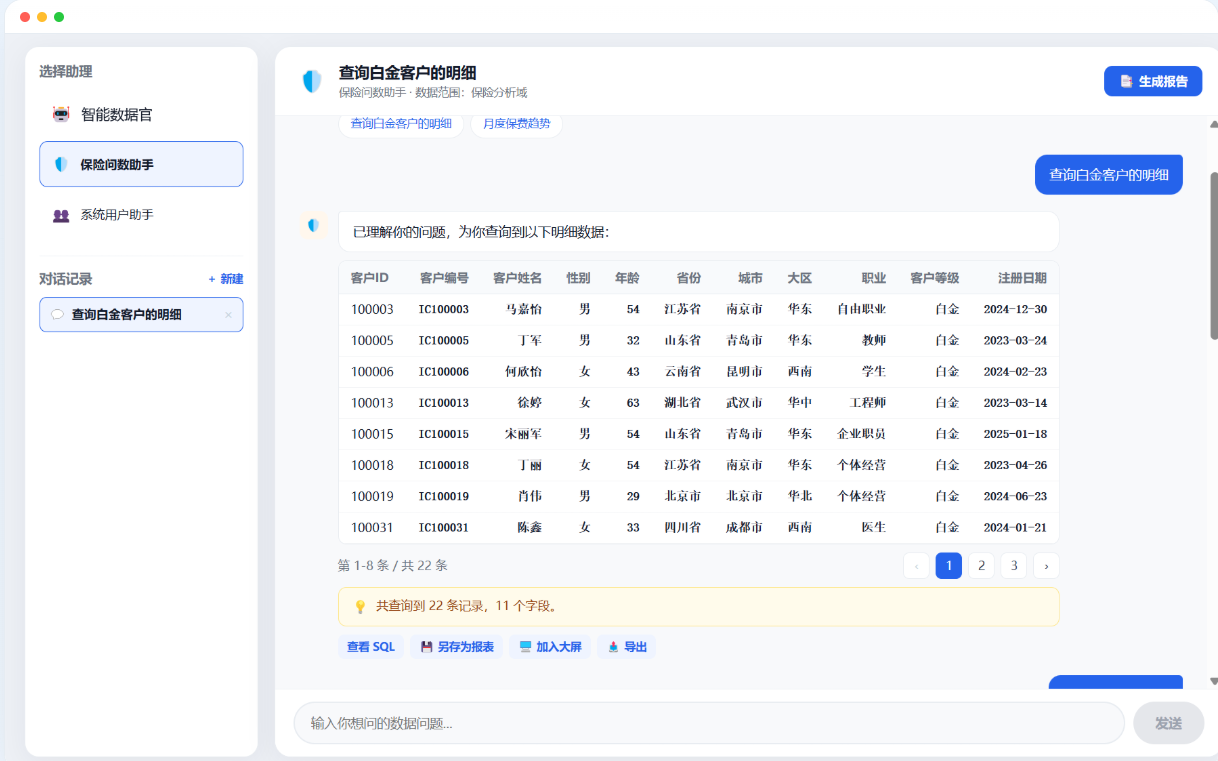
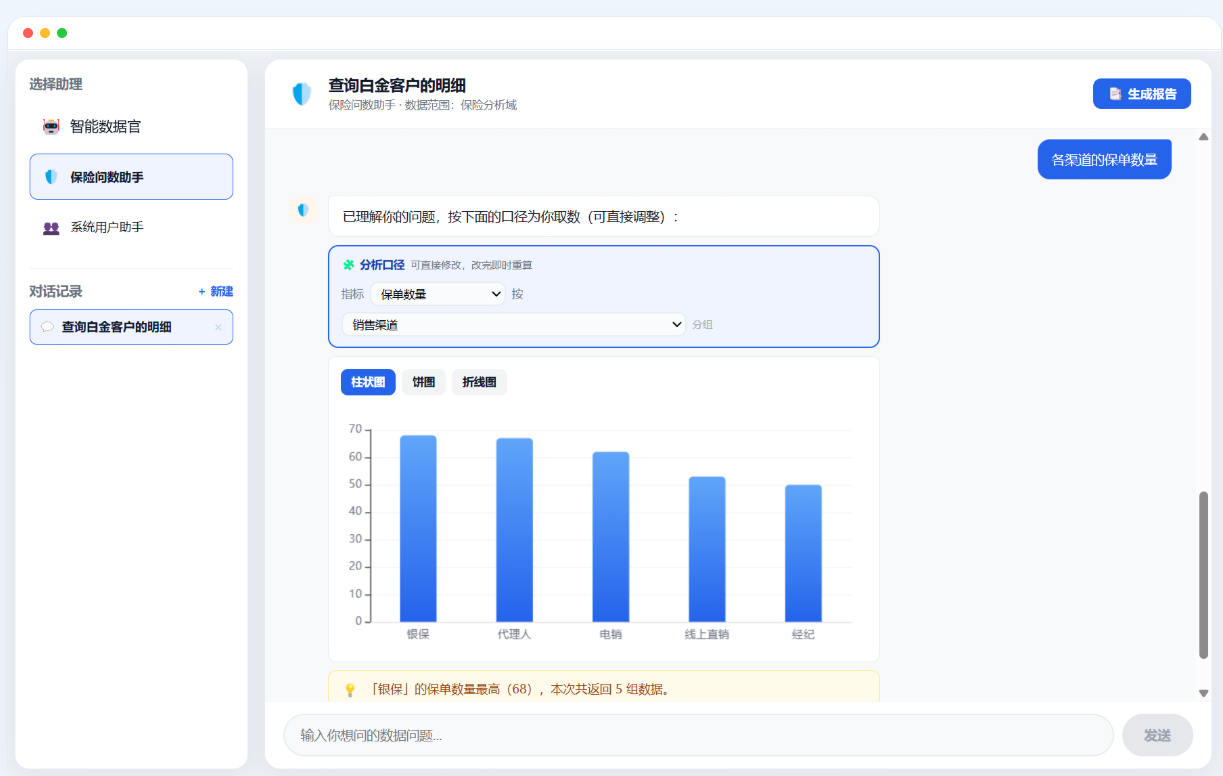
第三步:对话即分析
业务同学打开助理,用自然语言提问,秒级返回数据表格和可下钻图表,并可查看生成的 SQL、导出结果。这些都是真实可问的问题:
- “统计本年度各产品线的销售额,从高到低排列。”
- “各区域销售额对比”
- “本月销量 Top10 渠道”
- “近期客单价走势”
提问后系统会告诉你"已命中查询主题『销售分析』,维度产品线、指标销售额(SUM),按降序返回",然后给出表格 + 柱状图,旁边挂着"查看 SQL"“导出 Excel”“切换图表”。想换角度,接着问就行。
五、快速集成
JimuChatBI 是一个独立 JAR(Spring Boot starter),自动装配嵌入宿主应用,兼容 Spring Boot 2 / Spring Boot 3,集成像积木报表一样简单。前提:宿主应用已集成积木报表。
1. 引入依赖(宿主 pom.xml,自动注册,无需手动 ComponentScan):
<dependency>
<groupId>org.jeecgframework.jimureport</groupId>
<artifactId>jimuchatbi-spring-boot-starter</artifactId>
<version>尚未发布</version>
</dependency>
jeecg:
jmreport:
ai:
# OpenAI 兼容 base 地址(必填)
base-url: https://api.deepseek.com
# API Key(必填,留空则 AI 不可用)
api-key: sk-??
# 模型名
model: deepseek-v4-pro
# 采样温度,可选
temperature: 0
# chat-completions 路径,可选,默认 /v1/chat/completions
completions-path: /v1/chat/completions
# 单次生成最大 token 数(传给大模型的 max_tokens),DeepSeek 合法范围[1,393216]
max-tokens: 4096
总结
JimuChatBI(Chat2BI) 用一句话就能讲清楚:让业务同学用聊天的方式查数据,而且查得准、对得上、看得懂。它靠 Text2DSL 语义层把生成过程做得可控,靠语义建模把结果做得可信,再用三步流程把上线门槛降到最低。
即将开源、免费可商用、独立 JAR 轻量集成——想先体验或了解更多
共同学习,写下你的评论
评论加载中...
作者其他优质文章



