
sklearn.model_selection.train_test_split随机划分训练集和测试集
官网文档:
一般形式:
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和testdata,形式为:
X_train,X_test, y_train, y_test =
cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_state=0)
参数解释:
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
示例
data=pd.read_csv('C:\\Users\\lenovo\\Desktop\\file\\04_add_lastword259_jieba_stopword_506 _all_city.csv')print(data.info())# resultList=random.sample(range(1,20),10)X_train, X_test, y_train, y_test=train_test_split(data,data,test_size = 0.2)print(len(X_train))print(len(X_test))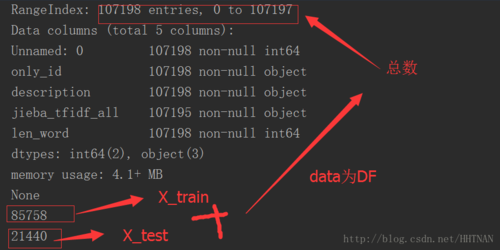
点击查看更多内容
为 TA 点赞
评论
共同学习,写下你的评论
评论加载中...
作者其他优质文章
正在加载中




感谢您的支持,我会继续努力的~
扫码打赏,你说多少就多少
赞赏金额会直接到老师账户
支付方式
打开微信扫一扫,即可进行扫码打赏哦