
一.概念
有句成语可以将协同过滤这个思想表现的淋漓尽致,那就是物以类聚,人以群分
——出处:《易经·系辞上》:
天尊地卑,乾坤定矣。卑高以陈,贵贱位矣。动静有常,刚柔断矣。方以类聚,物以群分,吉凶生矣。在天成象,在地成形,变化见矣。是故刚柔相摩,八卦相荡,鼓之以雷霆,润之以风雨,日月运行,一寒一暑。乾道成男,坤道成女。乾知大始,坤作成物。乾以易知,坤以简能。易则易知,简则易从。易知则有亲,易从则有功。有亲则可久,有功则可大。可久则贤人之德,可大则贤人之业。易简,而天下之理得矣。天下之理得,而成位乎其中矣。

以上内容纯属装逼
协同过滤是在海量数据中挖掘出小部分与你品味类似的用户,你们将成为“一类人”。然后根据他们喜欢的东西组织成一个有优先级的目录推荐给你。所以协同过滤主要干的就这两件事:
一、寻找与你品味类似的用户
二、根据他们喜欢的东西的强度排成一个目录
二.算法
协同过滤在学术界和工业界已经得到了广泛的研究并提出了很多算法。其中比较常见的有基于最近邻方法(包括基于用户最近邻和基于物品最近邻的方法)、Slope One、隐因子模型(主要包括受限玻尔兹曼机模型和矩阵分解技术)、也包括前几章介绍的贝叶斯、决策树等等,实际上任何聚类分类的技术都可以作用于此。不过其中最常用的就是最近邻方法。
三.最近邻算法
就是找到距离测试样例点最近的已知数据点并返回其类,计算距离有许多种不同的方法,如欧式距离、余弦距离、汉明距离、曼哈顿距离等,最常用的是欧几里得距离,说白了就是我们熟知的两点间距离公式。多维距离公式为ρ(A,B) = sqrt(∑(a[i] - b[i]^2)(i = 1,2,…,n))
#coding:utf-8import sysfrom numpy import *import operatorimport matplotlib.pyplot as pltdef classify(input,dataSet,label):dataSize = dataSet.shape[0]####计算欧式距离diff = tile(input,(dataSize,1)) - dataSetsqdiff = diff ** 2squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量dist = list(squareDist ** 0.5)return label[dist.index(min(dist))] #返回最近邻dataSet = array([[0.1,2.8],[1.9,0.6],[1.0,2.0],[3.0,2.5],[2.0,2.5],[1.8,3.0],[0.1,0.1],[0.5,0.5],[1.5,0.5],[1.5,1.5],[1.7,0.1],[2.5,0.2],])labels = ['A','A','A','B','B','B','C','C','C','D','D','D']input = array([1.9,0.5])print("input = ",input)output = classify(input,dataSet,labels)print("class = ",output)plt.figure(figsize=(5,5))for i,j in enumerate(dataSet):if labels[i] == 'A':plt.scatter(j[0],j[1],marker ="^",c="blue",s=80)elif labels[i] == 'B':plt.scatter(j[0],j[1],marker ="D",c ="green",s=80)elif labels[i] == 'C':plt.scatter(j[0],j[1],marker ="o",c ="darkorange",s=80)elif labels[i] == 'D':plt.scatter(j[0],j[1],marker ="s",c ="purple",s=80)plt.scatter(input[0],input[1],marker ="*",c ="red",s=200)plt.axis('tight')plt.show()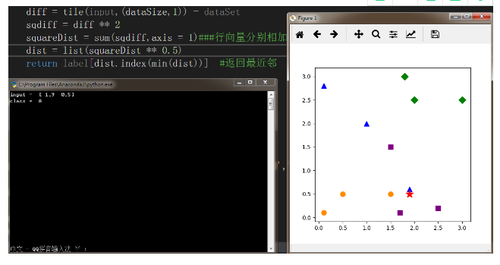
四.K近邻算法
最近邻算法的最大缺陷是对干扰数据过于敏感,为了解决这个问题,我们可以把未知样本周边的多个邻近样本计算在内,扩大参与决策的样本量,以避免个别数据直接决定决策结果。由此,我们引进K-最近邻算法(KNN)。K近邻算法是最近邻算法的一个延伸。基本思路是:选择未知样本一定范围内确定个数的K个样本,该K个样本大多数属于某一类型,则未知样本判定为该类型。如何选择一个最佳的K值取决于数据。一般情况下,在分类时较大的K值能够减小干扰数据的影响,但会使类别之间的界限变得模糊
#coding:utf-8import sysfrom numpy import *import operatorimport matplotlib.pyplot as plt###通过KNN进行分类def classify(input,dataSet,label,k):dataSize = dataSet.shape[0]####计算欧式距离diff = tile(input,(dataSize,1)) - dataSetsqdiff = diff ** 2squareDist = sum(sqdiff,axis = 1)###行向量分别相加,从而得到新的一个行向量dist = squareDist ** 0.5##对距离进行排序sortedDistIndex = argsort(dist)##argsort()根据元素的值从大到小对元素进行排序,返回下标classCount={}for i in range(k):voteLabel = label[sortedDistIndex[i]]###对选取的K个样本所属的类别个数进行统计classCount[voteLabel] = classCount.get(voteLabel,0) + 1###选取出现的类别次数最多的类别maxCount = 0for key,value in classCount.items():if value > maxCount:maxCount = valueclasses = keyreturn classesdataSet = array([[0.1,2.8],[1.9,0.6],[1.0,2.0],[3.0,2.5],[2.0,2.5],[1.8,3.0],[0.1,0.1],[0.5,0.5],[1.5,0.5],[1.5,1.5],[1.7,0.1],[2.5,0.2],])labels = ['A','A','A','B','B','B','C','C','C','D','D','D']input = array([1.9,0.5])print("input = ",input)for K in range(1,13):output = classify(input,dataSet,labels,K)print("K = ",K,"class = ",output)plt.figure(figsize=(5,5))for i,j in enumerate(dataSet):if labels[i] == 'A':plt.scatter(j[0],j[1],marker ="^",c="blue",s=80)elif labels[i] == 'B':plt.scatter(j[0],j[1],marker ="D",c ="green",s=80)elif labels[i] == 'C':plt.scatter(j[0],j[1],marker ="o",c ="darkorange",s=80)elif labels[i] == 'D':plt.scatter(j[0],j[1],marker ="s",c ="purple",s=80)plt.scatter(input[0],input[1],marker ="*",c ="red",s=200)plt.axis('tight')plt.show()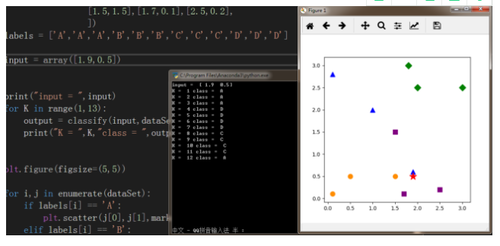
我们可以看到,当K值过小,其会选取最近的一个参考邻居A类(蓝),原因在于分类结果易受噪声点影响,若K值过大,其又会选择C类(黄),因为近邻中又可能包含太多的其它类别的点。实际我们的期望是他选择普遍与测试点相近的D类(紫),所以我们可以看到,K值的选择非常的重要,从大数据样本的经验来说,k一般低于训练样本数的平方根,不过具体怎样设立,还需要看具体的情况。
另外,也可以根据距离对影响值加权,即距离更近的近邻也许更应该决定最终的分类,也就是加权投票法。
五.总结
协同过滤作为一种经典的推荐算法种类,它的优点很多,模型通用性强,不需要太多对应数据领域的专业知识,工程实现简单,效果也不错。这些都是它流行的原因。当然,协同过滤也有些难以避免的难题,比如令人头疼的“冷启动”问题,我们没有新用户任何数据的时候,无法较好的为新用户推荐物品。同时也没有考虑情景的差异,又或者物品的类别(比如很多物品都是一次性消费的)等情况。
再说KNN,KNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。虽然其构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。也可以用压缩训练样本量等方法提高计算的效率。
KNN作为推荐算法时,即为每个内容寻找K个与其最相似的内容,并直接推荐给用户。相比之下,传统的协同过滤需要多一层处理,先看关注相同内容的用户,然后通过用户喜欢的内容来推荐。归根结底是因为无法计算内容之间的相似度,而把看了相同内容的用户再看的内容作为相似度的考量。
六.相关学习资源
https://www.cnblogs.com/charlesblc/p/6193979.html
http://blog.csdn.net/acdreamers/article/details/44672305
http://blog.csdn.net/u013414741/article/details/47108317
https://www.cnblogs.com/ybjourney/p/4702562.html
共同学习,写下你的评论
评论加载中...
作者其他优质文章



