
CTC 的工作原理

Fig. 1. How CTC combine a word (source: https://distill.pub/2017/ctc/)
这篇文章主要解释CTC 的工作原理。
Motivation
CTC 的全称是Connectionist Temporal Classification. 这个方法主要是解决神经网络label 和output 不对齐的问题(Alignment problem). 这种问题经常出现在scene text recognition, speech recognition, handwriting recognition 这样的应用里。 比如 Fig. 1 中的语音识别, 就会识别出很多个ww, 很多个r, 如果不做处理, 就会变成wworrrlld 我忽略了空白(blank). 有一种简单粗暴的方法就是把重复的都当做一个字母。 但是这样 就会出现不识别单词 happy 这样的单词。 这个时候, 空白的作用就非常大了, 在这里他把同一个字母隔开, 比如happy, 就会变成和hhh aaaa ppp ppp yyyy --> happy.
用数学的表达式来说, 这个是一个mapping, X-> Y 而且是一个 monotonic mapping (单调映射), 同时多个X 会映射到同一个Y. 最后一个特性就比较让人头疼, 就是Y 的长度不能 长于X 的长度。 想必用过tensorflow tf.nn.ctc_loss 应该都知道这样的 error message 把
“No valid path found, Loss: inf ”
出现这个warning/Error message 的原因就是 Y 的长度大于X 的长度, 导致CTC 无法计算。 解决方案就是检查训练集 中的label 和 实际内容是否相符。 比如, 对于 scene text recognition, 图像中是 hello, how are you doing。 而label 是 hello. 这样的训练集肯定会出问题的。
与传统方法做对比
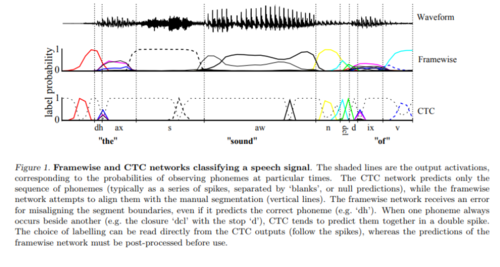
Source: Ref [1]
这个图解释了 framewise 的方法和CTC 的方法。 Framewise 的方法需要做每个音素的标记 (independent labelling of each time-step or frame of the input sequence) 而CTC 没有这个需要。 CTC 只是预测了一系列 峰值 (spikes) 紧接着 一些 可能空白 (blanks)用来区分字母。 但是 Framewise 基于的方法出现了 mis allignling segment boundaries error. 就是说两个 label 的概率分布图太近了, 比如 在发音 dh, dh 和ax 有明显重叠而CTC 的方法却没有。
CTC Loss 的计算
CTC Loss 的计算比较复杂,参考链接有比较详细的推到过程。 所以这边的解释主要通过截图论文 [1] 公式加以解释。 以下公式和图片都来自于论文 [1].
CTC 的计算包含一个softmax output layer, 而且也会多一个label (blank).
一个路径path 的概率计算如下。

这里, x 是输入数据, y 是输出数据, 都是序列。 L 是 序列标签的label, L‘ 是序列标签+blank. 其中公式(2), 解释了 给定一个输入, 从时间t=1 到T 每个时间点的概率相乘, 最后就得到了对应的路径的概率。
接下来就是定义 多对1 映射的概率计算了 (many-to-one mapping ), 论文中的内容截图如下

这里边B 就是映射, 把所有多对一的映射的集合。 这样就算出来对应一个真正的sequence label (L) 的概率了。 这里是求和。 求和的原因就是 aab 和abb 都是对应成ab, 所以 aab 的概率+abb 的概率 才是生成ab 的概率。 这个只是一个简单的例子。
接下来就是 生成分类器。 这里主要有两种 分类方法 (decoding method.)
Best path decoding. 按照正常分类问题, 那就是概率最大的sequence 就是分类器的输出。 这个就是用每一个 time step的输出做最后的结果。 但是这样的方法不能保证一定会找到最大概率的sequence.
prefix search decoding. 这个方法据说给定足够的计算资源和时间, 能找到最优解。 但是复杂度会指数增长 随着输入sequence 长度的变化。 这里推荐用有限长度的prefix search decode 来做。 但是具体考虑多长的sequence 做判断 还需具体问题具体分析。 这里的理论基础和就是 每一个node 都是condition 在上一个输出的前提下 算出整个序列的概率。 下面截图解释了。

CTC forward-backward 算法
这里CTC loss 是作为 神经网络的loss , 而且ctc的优化过程是算最大似然 (maximum likelihood), 这个和神经网络本身的训练过程是一致的
这个CTC 计算过程类似 forward-backward algorithm for HMM, 虽然我也不知道这个算法。 但是我可以学啊。 下面就是这个算法的推导过程, 依旧是论文截图+解释。

截图中的定义很清楚, 但是a_{t-1}(s) and a_{t-1}(s-1) 和 a_t(s) 的关系 也不那么好看出来,好在后面给了解释。
这段截图给了具体的推导过程 关于a_t{s} 的

这里的公式比较适合用下面的图来理解, a_1(1) 其实对应的就是下图中 左上角白色的圆圈。 就是 上来第一个label 是blank 的概率, 而 a_1(2) 是说上来识别 就是一个字母。 这里边我们假设每个字母之间都插入了 空白, 所以如果识别的是一个字母, 其实他的sequence 是2 (空白+字母)。 然后对于其他 sequence , 在时间是1 的情况下 概率都是 0.
下面这个图比较清楚 横轴是时间 t, 纵轴是 sequence, 这个例子里给的就是cat.
接下来我们分析 递归计算 (resursion). 公式6 分情况考虑
第一种情况就是 就是当前的label 是blank, 这个时候他的概率来自于过去t-1 的两个label 概率, 也就是 a_{t-1} (s) 和 a_{t-1} (s-1) . a_{t-1} (s) 就是说当前的sequence 已经是s 了, 下图就表现为横传, blank -->blank, 而 a_{t-1} (s-1) 是说明当前的字符还不够, 需要再加一个, 所以就是斜传 从黑色圆圈到白色圆圈。 仔细观察下图, 除了第一排的白色圆圈, 其他白色圆圈都有两个输入, 就是上述的两种情况。 当然判断blank 的方法也可以是判断I'_{s-2} = I'_{s}. 这种情况 也是说明I'_{s} 是blank, 因为每一个字符必须用 blank 隔开, 即使是相同字符。
第二章情况 也可以用类似逻辑得出, 只不过当前的状态s 是黑色圆圈, 有三种情况输入。

最终的概率 给定 就如公式8 的计算。 上面的计算 过程 就是 CTC forward algroirthm, 基于 Fig. 3 的左边的初始条件。但是基于Fig. 3 右边的初始条件, 我们还是可以计算出一个概率, 那个就是 CTC backward. 这里我就不详细介绍了, 直接截图。

这样一直做乘法, 数字值越来越小, 很快就到时underflow on diigital computer. 就是说计算机不能精准表达这么小的数值啦。 这个时候就需要做 scaling.
这里会思考, 算出了forward probability 和 backward probability, 有什么用啊, 论文里解释了。

就是说 forward probability and backward probability 的乘积, 代表了这个 sequence s at t 的 所有paths 的概率。 这样的话 我们就计算了 Fig. 3 中的每个圆圈的概率。
最后就是算微分了, 整个推导过程就是加法和乘法, 都可以微分。 考虑到tensorflow 已经带了这个函数而且自动微分, 具体请读者去看 ref [1] 啦。
CTC Loss 的局限
CTC 局限呢, 就是假设 每个label 直接是相互独立, 这样 概率才可以相乘 来计算conditional probability. 而实际上, 每个label 直接的概率不是相互独立的。 比如语言, the bird is fly in the sky. 最后一个单词 根据上下文很容易猜到时sky 的。 这个问题 可以通过beam search , language modeling 来解决。 当然这个也可能不完全是坏事, 比如希望模型能识别多个语言, 那language modelling 可能就不需要了。
原文写在石墨笔记上
https://shimo.im/docs/rpFiqCPHqfU3DM1P/
参考资料
[1] [A. Graves, S. Fernandez, F. Gomez, J. Schmidhuber. Connectionist Temporal lassification: Labeling Unsegmented Sequence Data with Recurrent Neural Networks. ICML 2006, Pittsburgh, USA, pp. 369-376.](http://www.cs.toronto.edu/~graves/icml_2006.pdf)
[2] https://distill.pub/2017/ctc/
作者:涛涛江水向坡流
链接:https://www.jianshu.com/p/e073c9d91b20
共同学习,写下你的评论
评论加载中...
作者其他优质文章



