

-
itemcf 基于商品的协同过滤 公式
查看全部 -
倒排,a 和 d 商品 比较相似。
查看全部 -
A 是用户 a是商品
查看全部 -
Architecture 结构设计
查看全部 -
协同过滤算法(Collaborative Filtering)
一、背景:
1、信息过载,用户实际需求不明确;
2、强依赖用户行为,有别于搜索行为,用户在使用推荐产品时,往往没有明确的需求,这时候根据用户行为历史来完成推荐或给与用户相同属性的召回算法则显得尤为重要;
协同过滤算法主要可以分为两类:基于用户相似的UserCF算法以及基于物品相似的ItemCF算法。简明地解释这两类的基本思想:如果user1和user2相似度高,那么user1买了一款物品item,就可以把这款物品也推荐给user2,这是UserCF的基本思想;如果item1和item2相似度高,那么一个用户user买了item1,就可以推荐他再买item2,这是ItemCF的基本思想。
二:Item cf:
1、给用户推荐他之前喜欢的物品相似的物品;
比如用户买了啤酒,我们应该要推荐和啤酒相似的物品,通俗来说,像白酒、红酒应该是和啤酒从物品属性上一致的产品,要优先推荐,但协同过滤可以推荐出诸如花生瓜子这样的零食;
2、如何衡量相似物品:
不同于从内容属性上衡量物品的相似性,协同过滤衡量物品的相似性是基于用户行为,如果喜欢两个物品的用户重合度越高,那两个物品也就越相似
3、如何衡量用户是否喜欢某个物品:
不同情况下衡量的方法是有差异的,首先要判断用户是否为真实点击,其次在电商场景下,更看重实际转化,也就是实际消费购买。信息流场景下,更看重真实的点击,也就是基于一定时长下的停留,那就认为是喜欢,所以还是要结合具体的产品;
三、结合实际例子来看如何基于itemcf衡量两个物品的相似度;
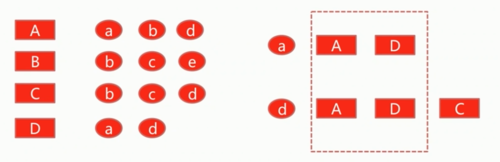
有四个用户,A、B、C、D,假设他们对以上的用户有过点击行为,这里我们以item a为例,之前说用户重合度的高低决定物品的相似程度,我们首先建立好每个item对应的每个用户的倒排,这里直接给出了与item a最相似的item d的倒排,item a与Item d有两个user是重合的,分别是A和D,item d 是其他几个item中与item a重合最多的,也是最相似的,结合之前说的item cf的简单原理,如果这里要给用户C,结合item cf的协同过滤来推荐物品的话,由于C曾经对item d有过点击 行为,那么这里我们会优先推荐与item d最相似的item a给C。
四、从数学公私上了解itemcf
itemcf的两大步骤:
1、根据用户点击行为计算两个物品的相似度;
u(i)表示对item i有过行为的用户集合,u(j)表示对item j有过行为的用户集合,分子部分是表示user的重合程度,显然重合度越高,物品越相似;再看分母,分母是做了归一化,例如,对item i有过行为的用户是两个,对item j有过行为的用户是三个,那么分母部分的数值就是根号6,从物理意义上来说,就是惩罚了热门物品与其他物品的相似度,因为热门物品对应的优热倒排会非常强,造成了与很多物品都有用户重合。如果分母除以一个很大的数,就会将相似度的数值趋于0,在得到了物品相似度矩阵后,我们根据用户的点击来推荐和点击相似的 item
2、
查看全部 -
规定双方法定
查看全部



举报